大佬会告诉你,强大的 AI 技术 idea 应该非常简单,实现起来也很快捷。
什么样的 AI 论文能刚上 arXiv 不到半天,就成为知乎热搜?
![]()
![]()
![]()
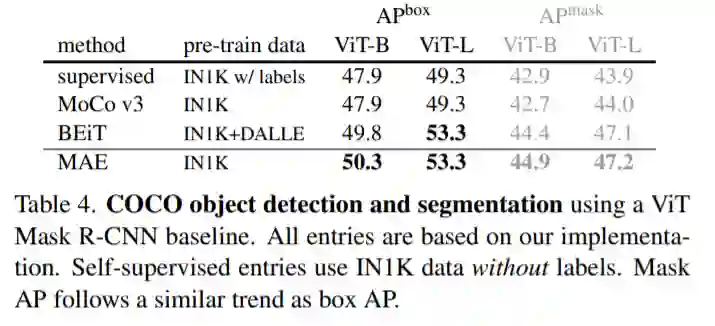
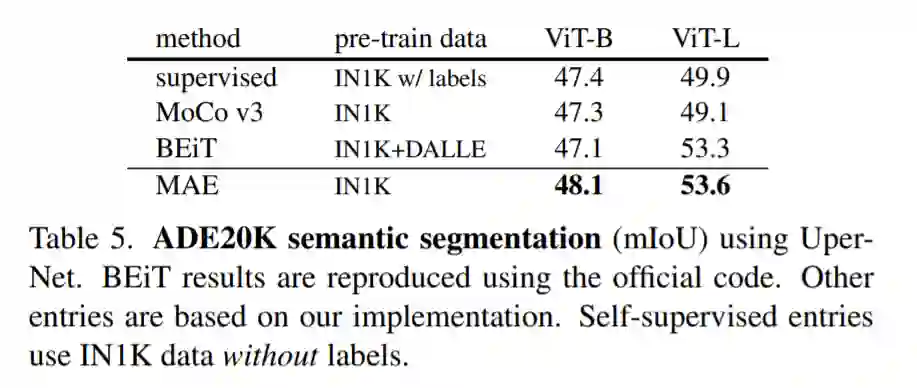
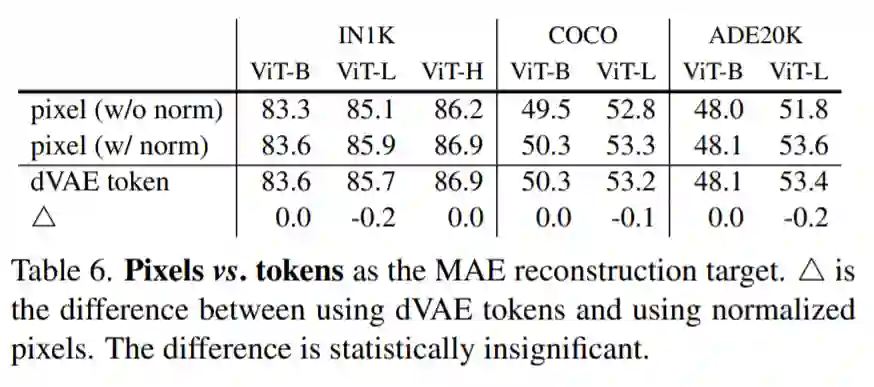
11 月 12 日,一篇由 Facebook AI 研究院完成、何恺明一作的论文《Masked Autoencoders Are Scalable Vision Learners》成为了计算机视觉圈的热门话题。
![]()
论文链接:https://arxiv.org/abs/2111.06377
社交网络上已有不止一人说,这篇论文说不定能「预定」CVPR 2022 的最佳。虽然我们还不能武断地认为它就是近期最重要的研究,但 MAE 研究的确是按照 CVPR 格式上传的,而且看来已是一个很有质量的工作。11 月 9 日,CVPR 2022 大会刚刚截止论文注册,论文提交的 Deadline 是太平洋时间 16 号晚 12 点。
这篇论文展示了一种被称为掩蔽自编码器(masked autoencoders,MAE)的新方法,可以用作计算机视觉的可扩展自监督学习器。MAE 的方法很简单:掩蔽输入图像的随机区块并重建丢失的像素。它基于两个核心理念:研究人员开发了一个非对称编码器 - 解码器架构,其中一个编码器只对可见的 patch 子集进行操作(没有掩蔽 token),另一个简单解码器可以从潜在表征和掩蔽 token 重建原始图像。
研究人员进一步发现,掩蔽大部分输入图像(例如 75%)会产生重要且有意义的自监督任务。结合这两种设计,我们就能高效地训练大型模型:提升训练速度至 3 倍或更多,并提高准确性。
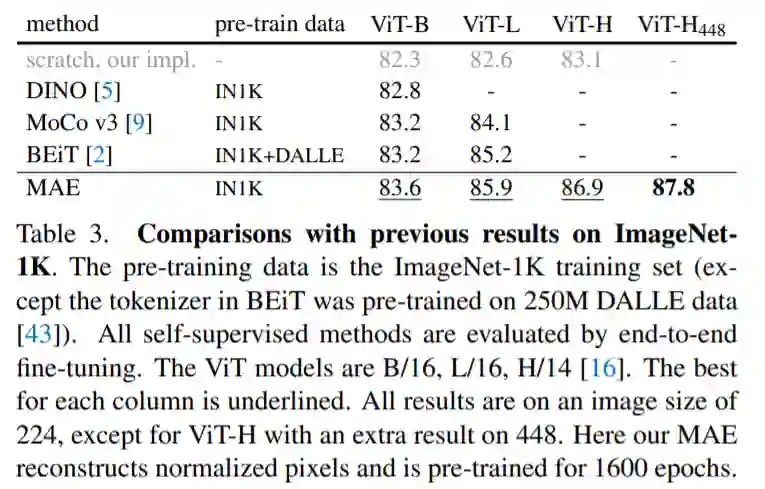
作者认为,这种可扩展方法允许学习泛化良好的高容量模型:例如在仅使用 ImageNet-1K 数据的方法中,vanilla ViT-Huge 模型实现了最佳准确率 (87.8%)。在下游任务中的传输性能优于有监督的预训练,并显示出可观的扩展能力。
用 MAE 做 pre-training 只需 ImageNet-1k 就能达到超过 87% 的 top 1 准确度,超过了所有在 ImageNet-21k pre-training 的 ViT 变体模型。而从方法上看,MAE 选择直接重建原图的元素,而且证明了其可行性,改变了人们的认知,又几乎可以覆盖 CV 里所有的识别类任务,看起来像是开启了一个新的方向。
近些年来,深度学习领域出现了一大批能力、容量均不断增长的架构。在不断升级的硬件的支持下,今天的模型已经能够轻松地消化数百万张图像,而且开始向数以亿计的标记图像进发。
在自然语言处理中,这种数据需求已经成功地通过自监督预训练来解决。基于 GPT 自回归语言建模和 BERT 掩蔽自编码的解决方案在概念上非常简单:它们删除一部分数据,并学习预测删除的内容。这些方法可以用来训练包含数千亿参数的可泛化 NLP 模型。
掩蔽自编码器是一种更通用的去噪自编码器,也适用于计算机视觉。其实,与视觉密切相关的研究早于 BERT。在 BERT 成功之后,人们对这一想法也产生了极大的兴趣。但尽管如此,视觉自编码方法的发展还是落后于 NLP。何恺明等研究者想知道:是什么造成了这种差异?
1、架构差异。在计算机视觉领域,卷积网络是过去十年的主流架构。不过,随着 Vision Transformers(ViT)的推出,这种架构上的差异已经逐渐缩小,应该不会再成为障碍。
2、信息密度差异。语言是人类产生的高度语义化信号,信息非常密集。当训练一个模型来预测每个句子中缺失的寥寥数词时,这项任务似乎能诱发复杂的语言理解。但视觉任务就不同了:图像是自然信号,拥有大量的空间冗余。例如,一个缺失的 patch 可以根据相邻的 patch 恢复,而不需要对其他部分、对象和场景有很多的高级理解。
为了克服这种差异并鼓励学习有用的特征,研究者展示了:一个简单的策略在计算机视觉中也能非常有效:掩蔽很大一部分随机 patch。这种策略在很大程度上减少了冗余,并创造了一个具有挑战性的自监督任务,该任务需要超越低级图像统计的整体理解。下图 2 - 图 4 展示了这一重建任务的定性结果。
![]()
![]()
![]()
3、自编码器的解码器(将潜在表征映射回输入)在文本和图像重建任务中起着不同的作用。在计算机视觉任务中,解码器重建的是像素,因此其输出的语义水平低于一般的识别任务。这与语言相反,语言任务中的解码器预测的是包含丰富语义信息的缺失单词。虽然在 BERT 中,解码器可能是微不足道的(一个 MLP),但何恺明等研究者发现,对于图像,解码器的设计对于学到的潜在表示的语义水平起着关键作用。
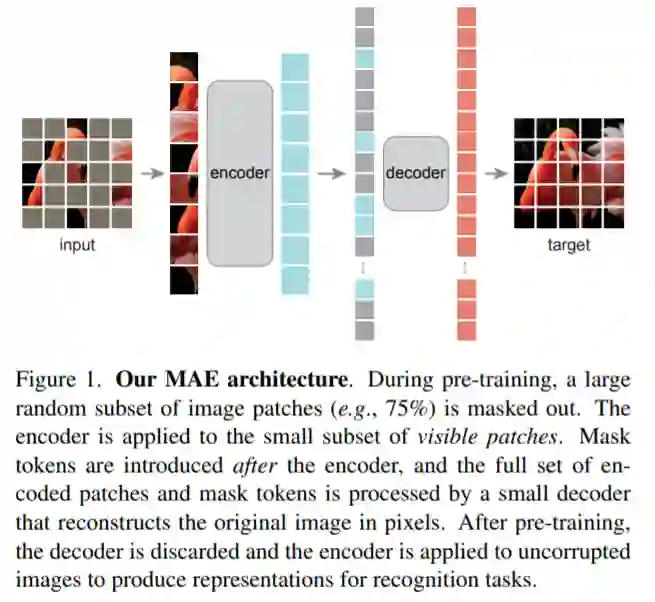
基于以上分析,研究者提出了一种简单、有效且可扩展的掩蔽自编码器(MAE)用于视觉表征学习。该 MAE 从输入图像中掩蔽了随机 patch 并重建像素空间中缺失的 patch。它具有非对称的编码器 - 解码器设计。其中,编码器仅对 patch 的可见子集(没有掩码 token)进行操作,解码器则是轻量级的,可以从潜在表征和掩码 token 中重建输入(图 1)。
在这个非对称编码器 - 解码器中,将掩码 token 转移到小型解码器会导致计算量大幅减少。在这种设计下,非常高的掩蔽率(例如 75%)可以实现双赢:它优化了准确性,同时允许编码器仅处理一小部分(例如 25%)的 patch。这可以将整体预训练时间减少至原来的 1/3 或更低,同时减少内存消耗,使我们能够轻松地将 MAE 扩展到大型模型。
![]()
MAE 可以学习非常大容量的模型,而且泛化性能良好。通过 MAE 预训练,研究者可以在 ImageNet-1K 上训练 ViT-Large/-Huge 等需要大量数据的模型,提高泛化性能。例如,在 ImageNet-1K 数据集上,原始 ViT-Huge 模型经过微调后可以实现 87.8% 的准确率。这比以前所有仅使用 ImageNet-1K 数据的模型效果都要好。
![]()
研究者还对 MAE 进行了迁移学习方面的评估,具体任务包括目标检测、实例分割、语义分割等。实验结果表明,MAE 实现了比监督预训练更好的结果。更重要的是,随着模型规模的扩大,MAE 的收益也越来越明显。这些结果与 NLP 预训练中观察到的自监督预训练结果一致。
![]()
![]()
![]()
具有良好扩展性的简单算法是深度学习的核心。在 NLP 中,简单的自监督学习方法(如 BERT)可以从指数级增大的模型中获益。在计算机视觉中,尽管自监督学习取得了进展,但实际的预训练范式仍是监督学习。在 MAE 研究中,研究人员在 ImageNet 和迁移学习中观察到自编码器——一种类似于 NLP 技术的简单自监督方法——提供了可扩展的前景。视觉中的自监督学习可能会因此走上与 NLP 类似的轨迹。
与 ViT 类似,该方法将图像划分为规则的非重叠 patch,然后对 patch 的子集进行采样,并掩蔽(移除)剩余的 patch。该方法的采样策略很简单:不带替换地随机采样 patch,遵循均匀分布。研究者将其称为「随机采样」。具有高掩蔽率(即移除 patch 的比率)的随机采样在很大程度上消除了冗余,从而创建了一项无法借助可见相邻 patch 外推(extrapolation)来轻松解决的任务。均匀分布可以避免出现潜在的中心偏置(center bias,即图像中心附近有更多的掩蔽 patch)。最后,高度稀疏的输入有助于设计高效的编码器。
该方法的编码器是一个仅适用于可见、未掩蔽 patch 的 ViT。就像在一个标准的 ViT 中一样,该编码器通过添加位置嵌入的线性投影嵌入 patch,然后通过一系列 Transformer 块处理结果集。但该编码器只对整个集合的一小部分(例如 25%)进行操作。被掩蔽的 patch 被移除;不使用掩蔽 token。这使得该方法能够仅使用一小部分计算和内存来训练非常大的编码器。
MAE 解码器的输入是一个完整的 token 集,包括 (i) 已编码的可见 patch 和 (ii) 掩蔽 token,如上图 1 所示。每个掩蔽 token 是一个共享的学得向量,指示是否存在需要预测的缺失 patch。该研究为这个完整集合中的所有 token 添加了位置嵌入,否则掩蔽 token 将没有关于它们在图像中位置的信息。解码器也有一系列的 Transformer 块。
MAE 解码器仅在预训练期间用于执行图像重建任务,仅使用编码器生成用于识别的图像表征,因此可以以独立于编码器设计的方式灵活地设计解码器的架构。该研究尝试了非常小的解码器,比编码器更窄更浅。例如该方法的默认解码器每个 token 的计算量仅为编码器的 10% 以下。通过这种非对称设计,所有 token 仅用轻量级解码器处理,显著减少了预训练时间。
![]()
何恺明是 AI 领域著名的研究者。2003 年他以标准分 900 分获得广东省高考总分第一,被清华大学物理系基础科学班录取。在清华物理系基础科学班毕业后,他进入香港中文大学多媒体实验室攻读博士学位,师从汤晓鸥。
何恺明曾于 2007 年进入微软亚洲研究院视觉计算组实习,实习导师为孙剑。2011 年博士毕业后,他加入微软亚洲研究院工作,任研究员。2016 年,何恺明加入 Facebook 人工智能实验室,任研究科学家至今。
何恺明曾于 2009 年拿到国际计算机视觉顶会 CVPR 的 Best Paper,2016 年再获 Best Paper 奖,2021 年有一篇论文是最佳论文的候选。何恺明还因为 Mask R-CNN 获得过 ICCV 2017 的最佳论文(Marr Prize),同时也参与了当年最佳学生论文的研究。
https://www.zhihu.com/question/498364155
https://arxiv.org/pdf/2111.06377.pdf
第一期:快速搭建基于Python和NVIDIA TAO Toolkit的深度学习训练环境
英伟达 AI 框架 TAO(Train, Adapt, and optimization)提供了一种更快、更简单的方法来加速培训,并快速创建高度精确、高性能、领域特定的人工智能模型。
11月15日19:30-21:00,英伟达专家带来线上分享,
将介绍:
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com