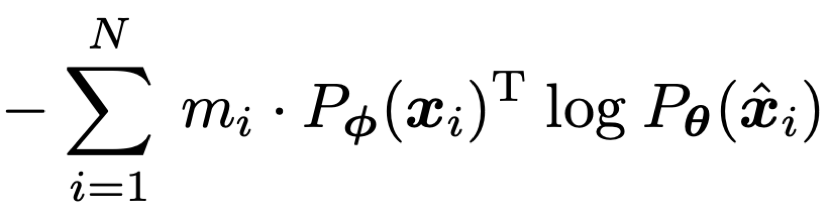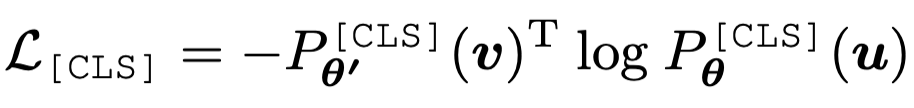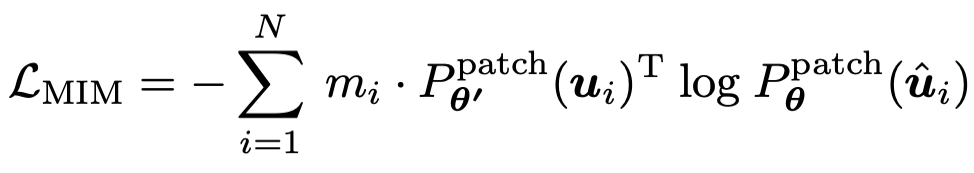这个新方法在十几类任务和数据集上刷新了 SOTA 结果,在一些指标上甚至超过了 MAE。
![]()
那么,MAE 就是大模型视觉模型预训练方法的巅峰了吗?显然不是,一大波挑战者已经在路上了,比如字节跳动、约翰霍普金斯大学等机构组成的联合团队。
在一篇最新的论文中,他们提出了适用于视觉任务的大规模预训练方法 iBOT,通过对图像使用在线 tokenizer 进行 BERT [1]式预训练让 CV 模型获得通用广泛的特征表达能力。该方法在十几类任务和数据集上刷新了 SOTA 结果,在一些指标上甚至超过了 MAE [2]。
![]()
论文链接:
https://arxiv.org/abs/2111.07832
![]()
在 NLP 的大规模模型训练中,MLM(Masked Language Model)是非常核心的训练目标,其思想是遮住文本的一部分并通过模型去预测这些遮住部分的语义信息,通过这一过程可以使模型学到泛化的特征。NLP 中的经典方法 BERT 就是采用了 MLM 的预训练范式,通过 MLM 训练的模型已经被证明在大模型和大数据上具备极好的泛化能力,成为 NLP 任务的标配。
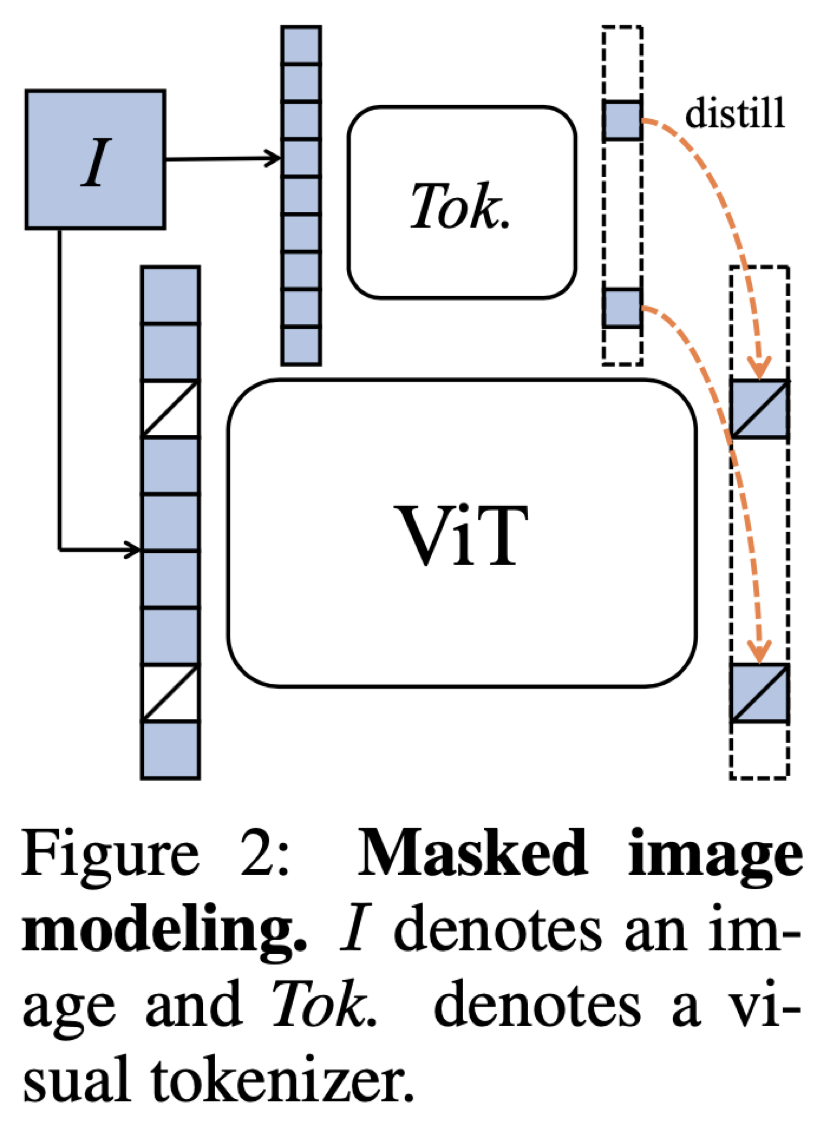
在该工作中,研究者主要探索了这种在 NLP 中主流的 Masked Modeling 是否能应用于大规模 Vision Transformer 的预训练。作者给出了肯定的回答,并认为问题关键在于 visual tokenizer 的设计。不同于 NLP 中 tokenization 通过离线的词频分析即可将语料编码为含高语义的分词,图像 patch 是连续分布的且存在大量冗余的底层细节信息。而作者认为一个能够提取图像 patch 中高层语义的 tokenizer 可帮助模型避免学习到冗余的这些细节信息。作者认为视觉的 tokenizer 应该具备两个属性:(a)具备完整表征连续图像内容的能力;(b) 像 NLP 中的 tokenizer 一样具备高层语义。
如何才能设计出一个 tokenizer,使之同时具备以上的属性呢?作者首先将经过 mask 过的图片序列输入 Transformer 之后进行预测的过程建模为知识蒸馏的过程:
![]()
![]()
作者发现,通过使用在线 tokenizer 监督 MIM 过程,即 tokenizer 和目标网络同步学习,能够较好地保证语义的同时并将图像内容转化为连续的特征分布。具体地,tokenizer 和目标网络共享网络结构,在线即指 tokenizer 其参数从目标网络的历史参数中滑动平均得出。该形式近期在 DINO [3]中以自蒸馏被提出,并被用以针对同一张图片的两个不同视野在 [CLS] 标签上的优化:
![]()
在该损失函数的基础之上,作者将 MIM 同样也使用自蒸馏的思路进行优化,其中在线 tokenizer 的参数即
为目标网络历史参数的平均。其过程可表示为:
![]()
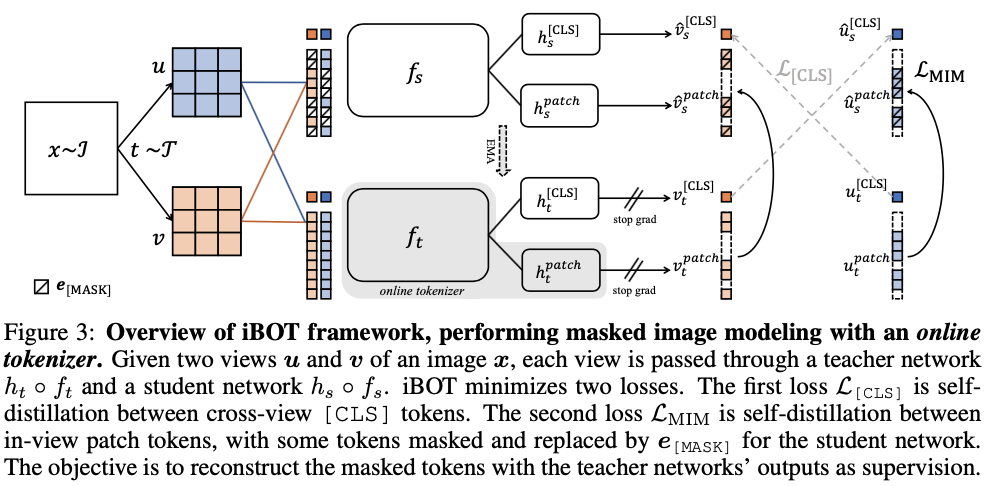
基于上述训练目标,作者提出了一种新的自监督预训练框架 iBOT。iBOT 同时优化上述两项损失函数。其中,在 [CLS] 标签上的自蒸馏保证了在线 tokenizer 学习到高语义特征,并将该语义迁移到 MIM 的优化过程中;而在 patch 标签上的自蒸馏则将在线 tokenizer 表征的 patch 连续分布作为目标监督 masked patch 的复原。该方法在保证模型学习到高语义特征的同时,通过 MIM 显式建模了图片的内部结构。同时,在线 tokenizer 与 MIM 目标可以一起端到端地学习,无需额外的 tokenizer 训练阶段。
![]()
预训练时采用孪生网络结构,其中在线 tokenizer 可以看作教师分支的一部分。教师、学生两分支包括结构相同的 backbone 网络和 projection 网络。作者广泛验证了 iBOT 方法搭配不同的 Transformers 作为 backbone,如 Vision Transformers(ViT-S/16, ViT-B/16, ViT-L/16)及 Swin Transformers(Swin-T/7, Swin-T/14)。作者发现共享 [CLS] 标签与 patch 标签的 projection 网络能够有效提升模型在下游任务上的迁移性能。作者还采用了随机 MIM 的训练机制,对每张图片而言,以 0.5 的概率不进行 mask,以 0.5 的概率从 [0.1, 0.5] 区间随机选取一个比例进行 mask。实验表明随机 MIM 的机制对于使用了 multi-crop 数据增强的 iBOT 非常关键。
为了验证 iBOT 预训练方法的有效性,作者在大量的下游任务上进行了验证,同时也在附录里提供了比较详细的不同任务超参数对最终结果的影响。
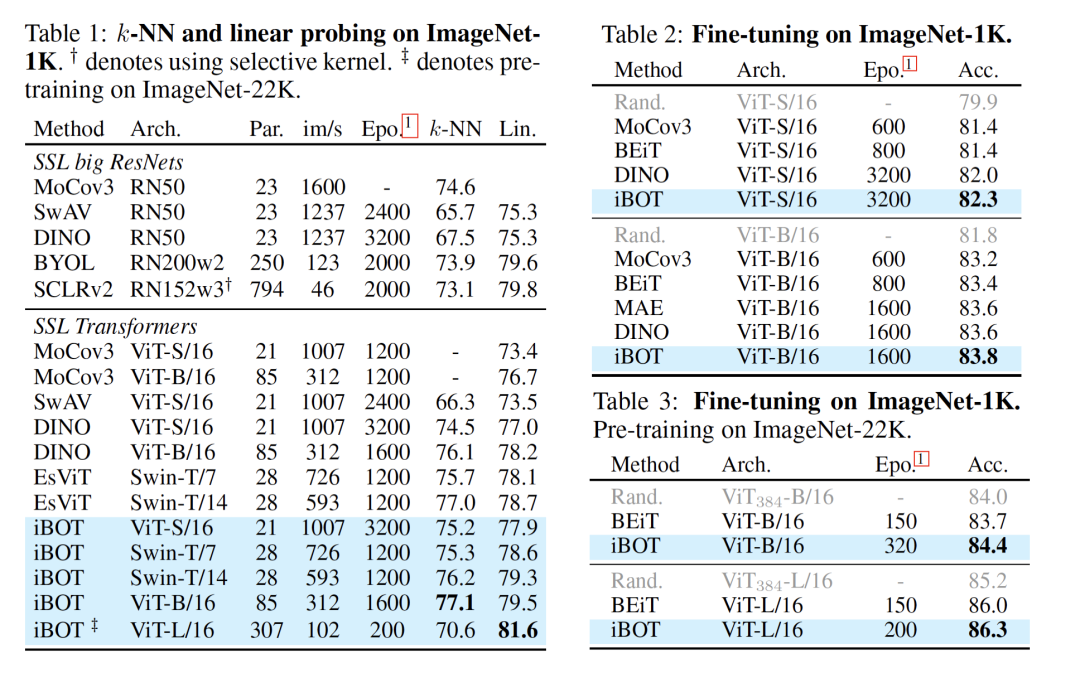
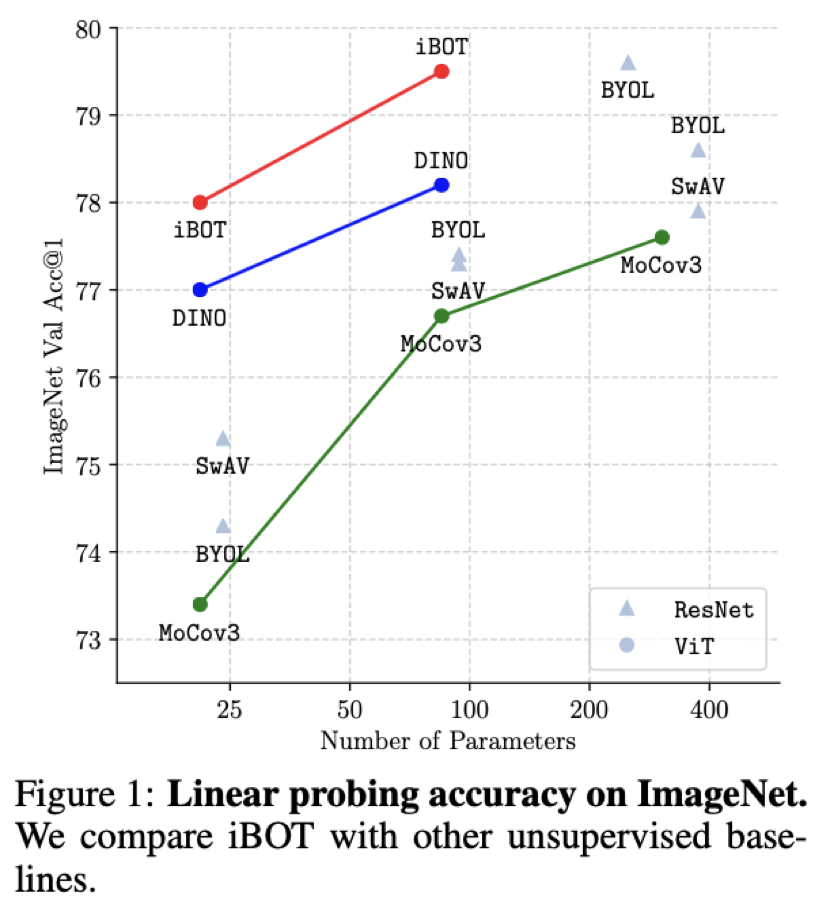
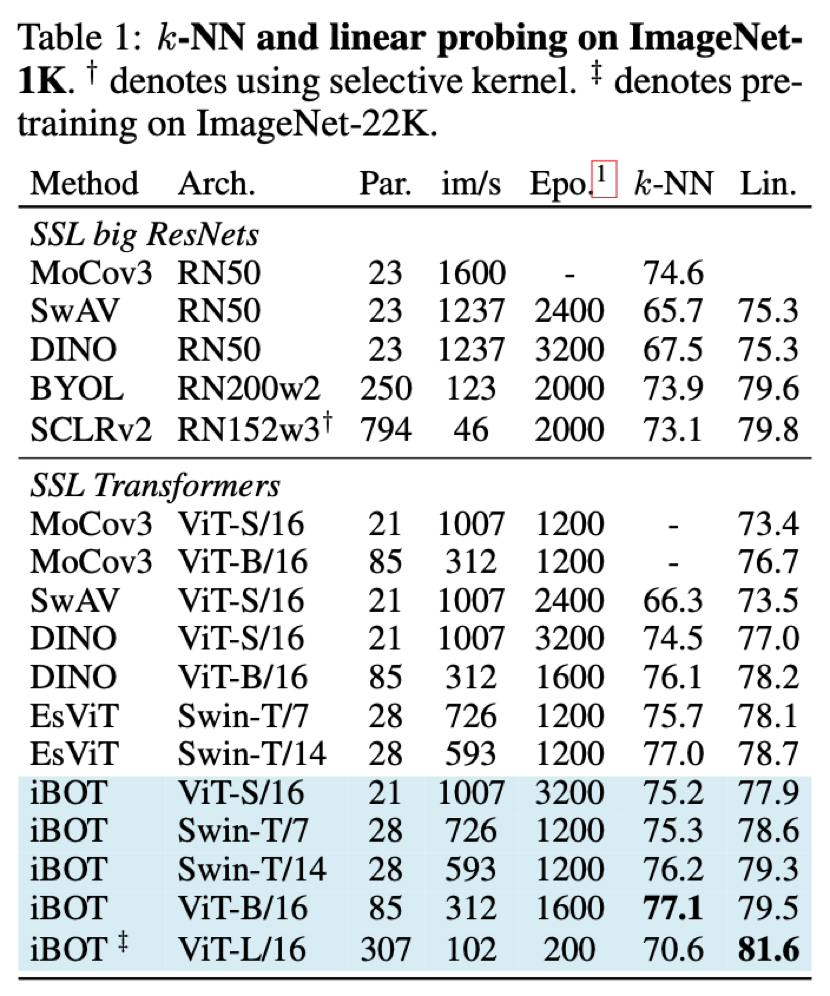
从 Linear probing(线性分类)及 k-NN 分类的结果上来看,iBOT 使用 ViT-B/16 达到 79.5% 线性分类准确度,超越了 DINO 的 78.2%;使用 Swin-T/14 达到 79.3% 准确度,超越了 EsViT 的 78.7%;使用 ViT-L/16 及 ImageNet-22K 作为预训练数据达到 81.6% 准确度,为目前 ImageNet-1K 线性分类基准上最高的结果。
![]()
![]()
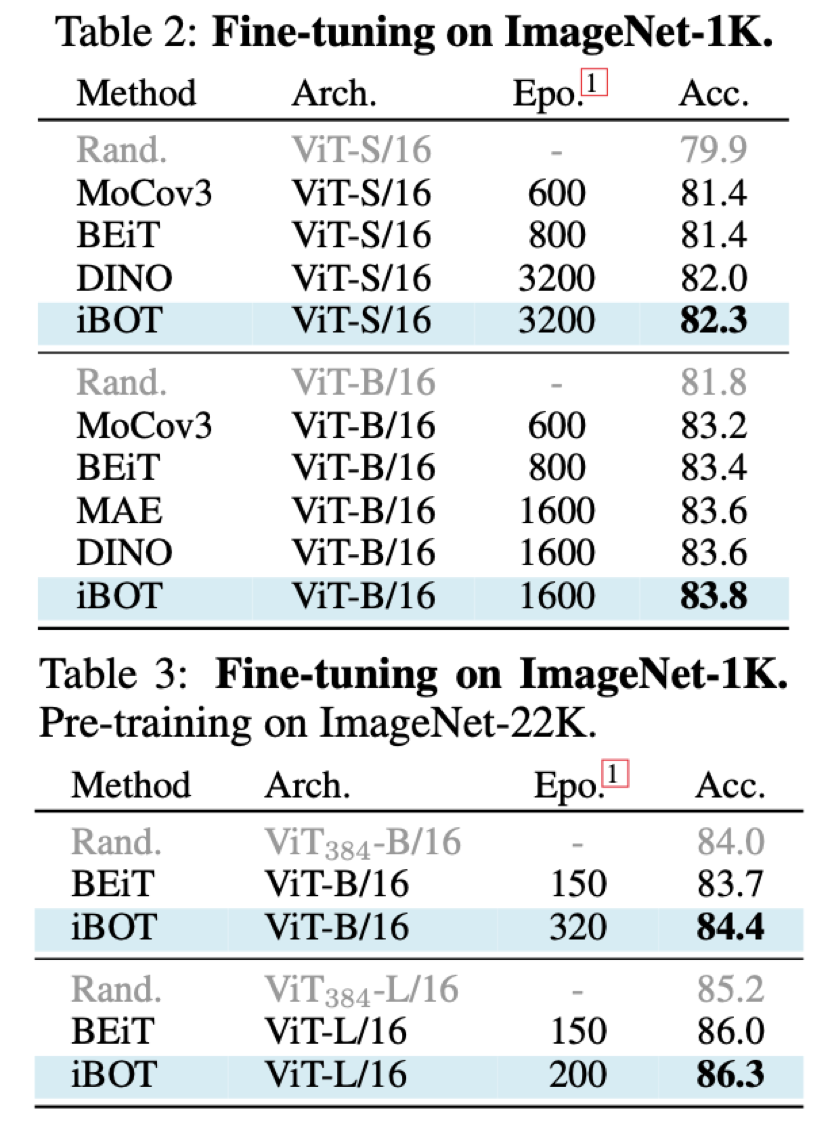
从 Fine-tuning 的结果上来看,使用 ImageNet-1K 作为预训练数据及 ViT-B/16 时 iBOT 可达到 83.8% 准确率,高于 DINO、MAE 的 83.6%;使用 ImageNet-22K 作为预训练数据及 ViT-L/16 时 iBOT 可达到 86.3%,高于 BEiT [4]的 86.0%。
![]()
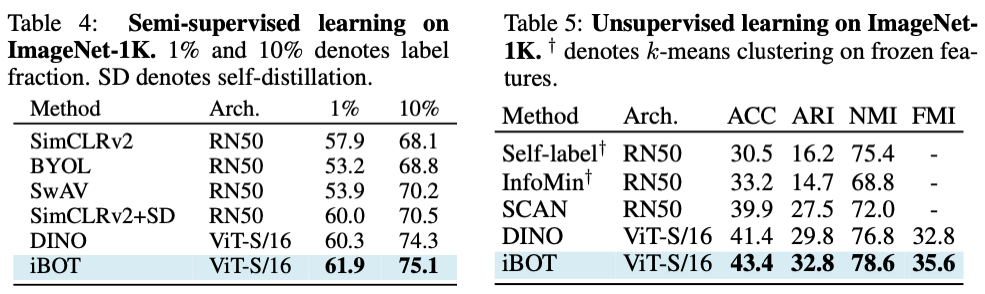
在半监督及无监督分类的结果上来看,iBOT 也显著优于没有 MIM 训练目标的 DINO。其中在半监督的基准下,作者发现微调数据越少时,iBOT 的优势越明显。在无监督的基准下,iBOT 能达到 43.4% 的准确率以及 78.6% 的 NMI。
![]()
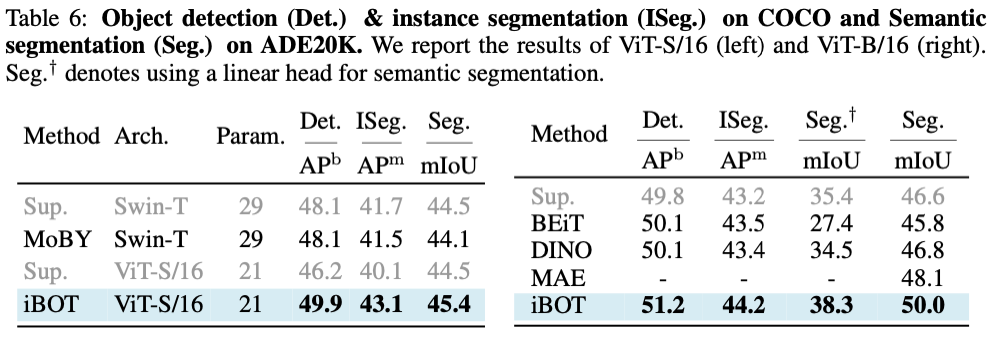
除此之外,因为 MIM 显示建模了图片内部结构,作者发现 iBOT 在密集的下游任务也有非常好的迁移结果。其中 iBOT 使用 ViT-B/16 及 Cascade Mask R-CNN 在目标检测下可达到 51.2 APb;使用 ViT-B/16 及 UperNet 在语义分割下可达到 50.0 mAP,高于 MAE 达到的 48.1 mAP。
![]()
同时作者也进一步探究了 MIM 训练目标所带来的特性,以帮助分析 iBOT 在全局图像任务及密集图像任务出色表现的原因。作者根据 ImageNet 验证集中所有图片 patch 的概率分布,可视化了部分类别中心所代表的模式。作者在大量的可视化结果中发现 iBOT 针对局部语义有非常好的可视化结果,如下图左一、左二中所示的车灯、狗耳朵展现了不同局部类别语义的出现,而在下图左三、左四中展现了不同局部纹理语义的出现。
![]()
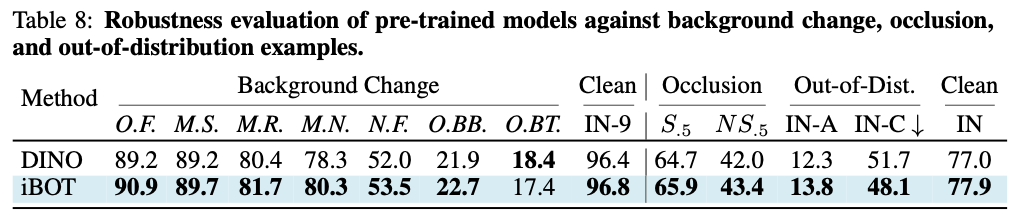
在大量鲁棒性分析及测评中,作者发现 iBOT 相较没有 MIM 训练目标的 DINO 有更出色的表现,这说明局部语义的出现能够帮助模型在遮挡、模糊等一系列干扰存在的图像识别任务下有更好的准确性。
![]()
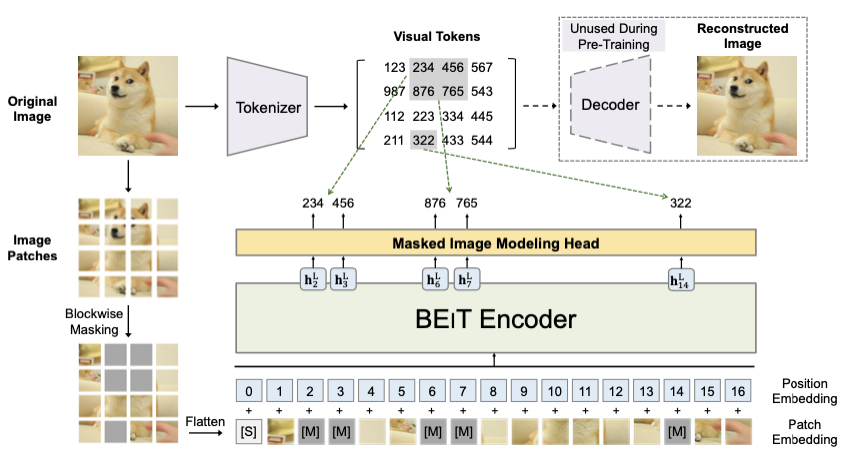
近期 masked autoencoding 的思路可谓在视觉领域大火,和近期一些工作对比,BEiT 使用了一个预训练好的 DALL-E encoder 作为 tokenizer,将每个 patch 标签离散化后的 one-hot 编码作为目标模型的标签。
![]()
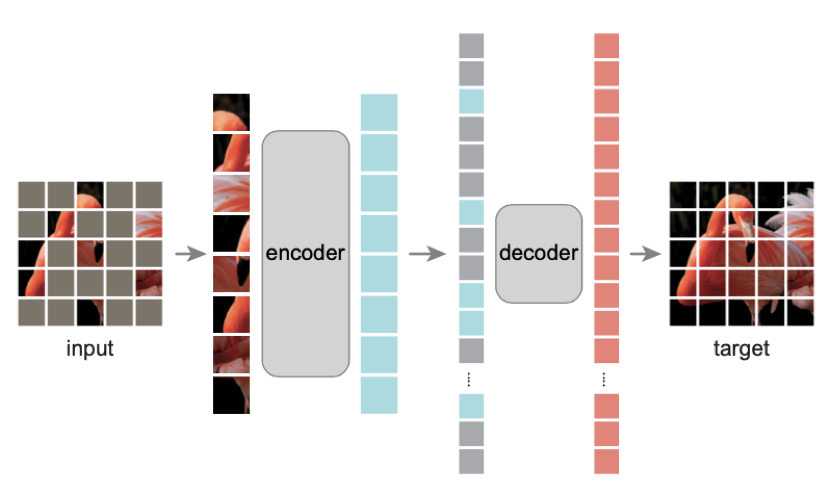
而 MPP [5]及近期较火的 MAE 则可将 tokenizer 视为恒等变换,即直接在像素空间内进行回归而非分类。
![]()
而 iBOT 则指出了上述几种方式的 tokenizer 存在过度关注低级信息的问题,这也可以从上述几种方法线性分类的性能不是很高可以看出。但近期 MAE 中指出当图片中被 mask 的比例足够大时,可使网络无法从相近 patches 中插值获取信息从而迫使其学到全局信息;MAE 还指出线性分类并不是唯一评估特征表征能力的基准,且和下游迁移学习的表现不能较好相关。
[1] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In NAACL, 2019.
[2] Kaiming He,Xinlei Chen, Saining Xie, Yanghao Li,Piotr Dollar, and Ross Girshick. Masked autoencoders are scalable vision learners. arXiv preprint arXiv:2111.06377, 2021.
[3] Mathilde Caron, Hugo Touvron, Ishan Misra, Herve ́ Je ́gou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In ICCV, 2021.
[4] Hangbo Bao, Li Dong, and Furu Wei. BEiT: BERT pre-training of image transformers. arXiv preprint arXiv:2106.08254, 2021.
[5] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com