何恺明一作,刷新7项检测分割任务,无监督预训练完胜有监督
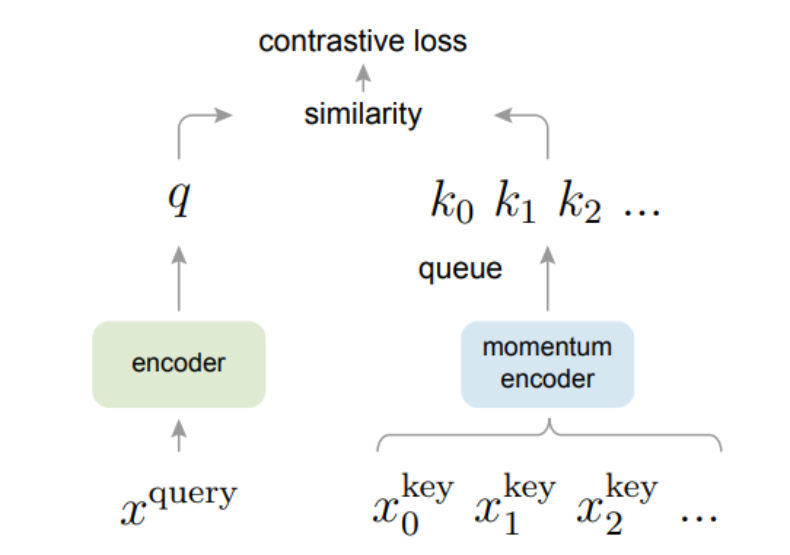
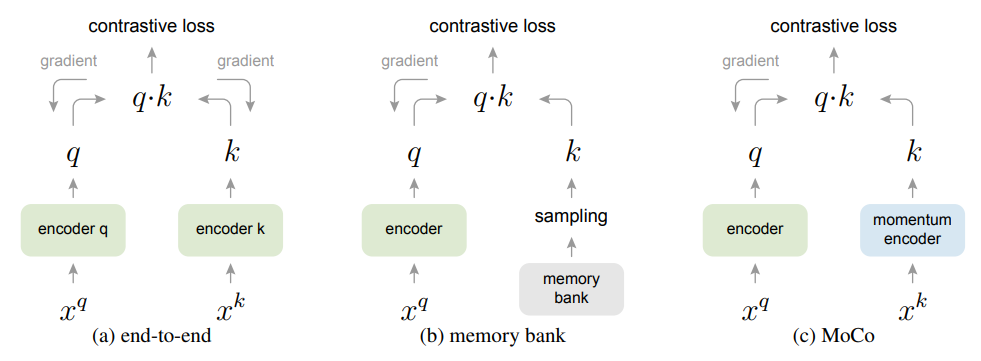
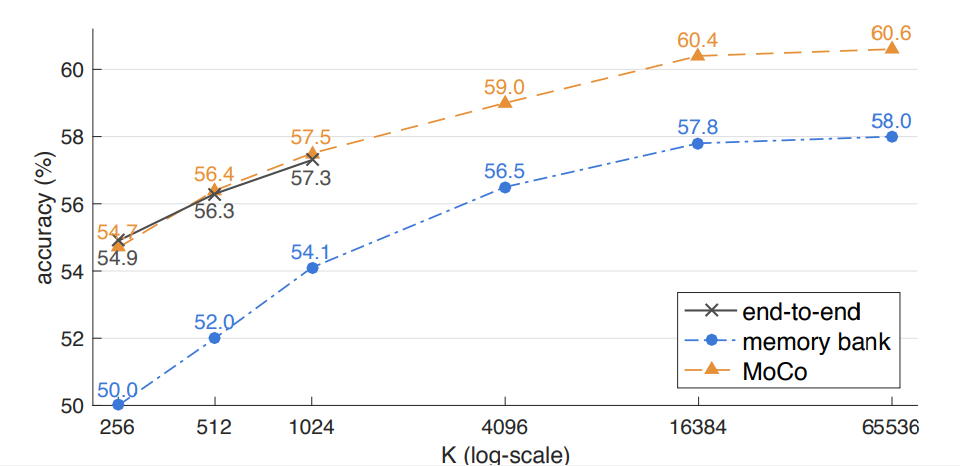
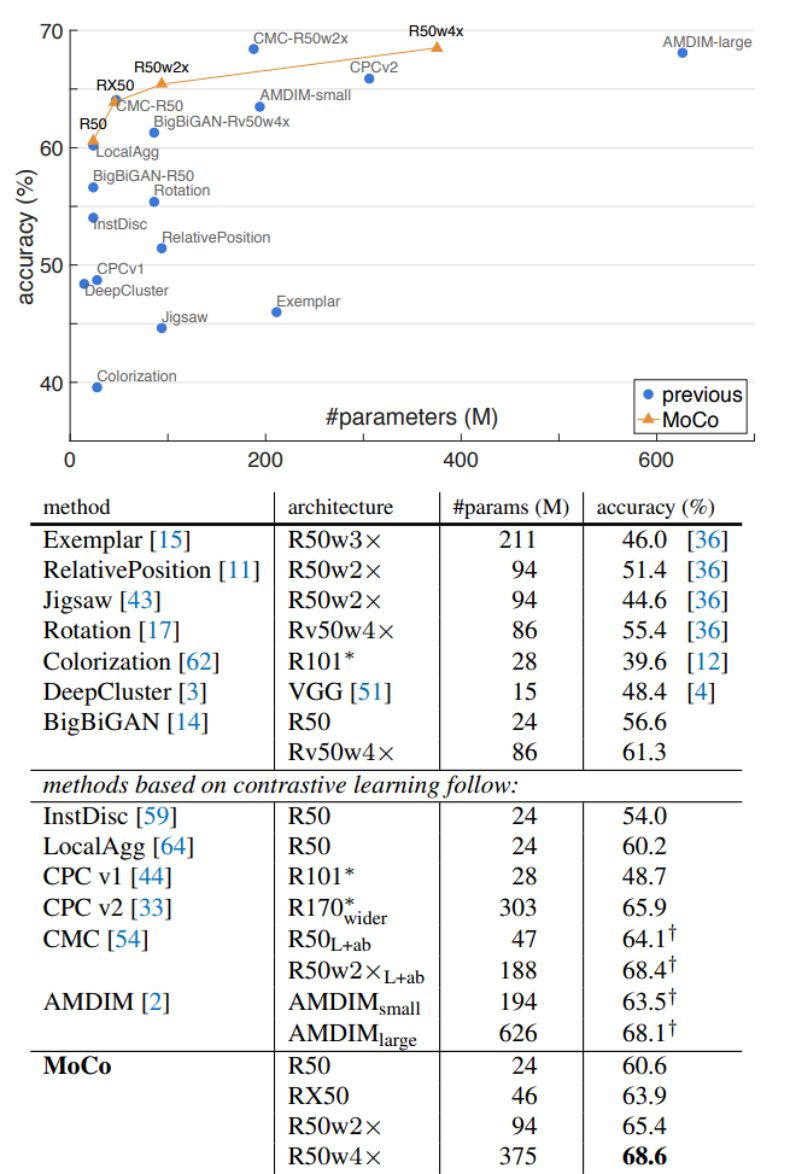
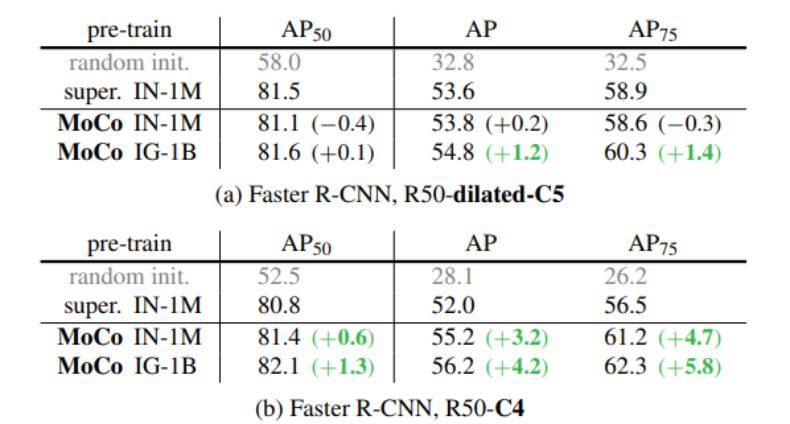
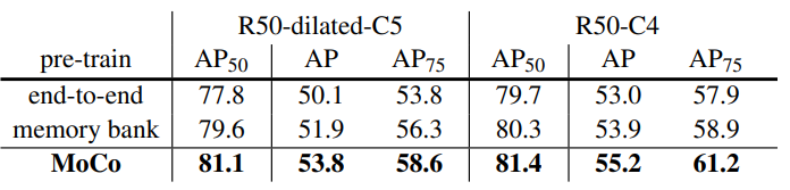
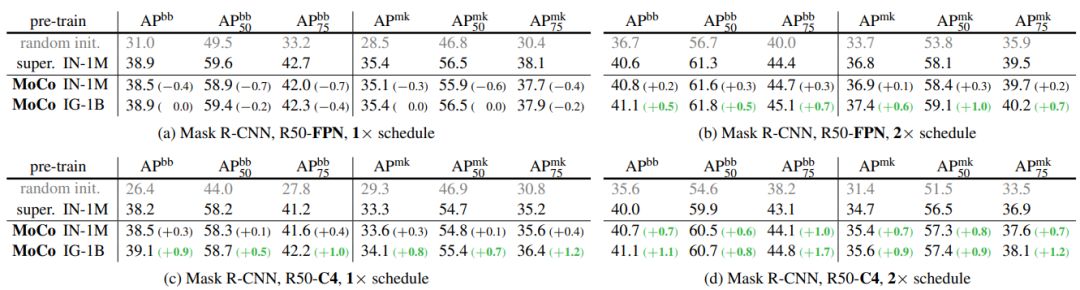
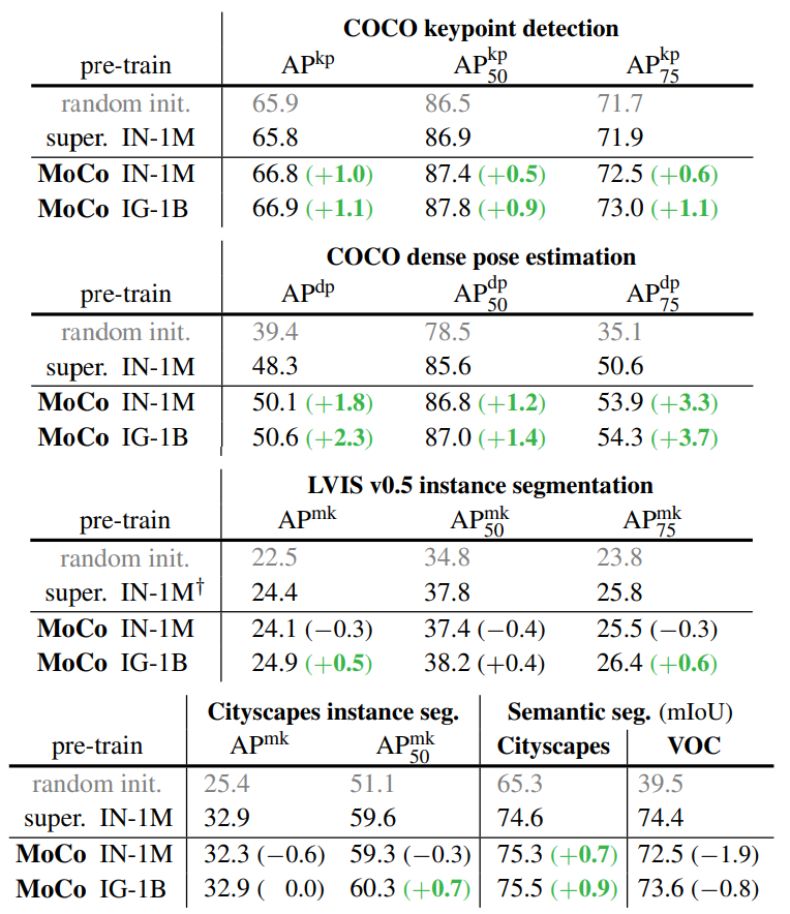
Facebook AI 研究团队的何恺明等人提出了一种名为动量对比(MoCo)的无监督训练方法。 在 7 个与检测和分割相关的下游任务中,MoCo 可以超越在 ImageNet 上的监督学习结果,在某些情况下其表现甚至大大超越后者。 作者在摘要中写道: 「这表明,在许多视觉任务中,无监督和监督表征学习之间的差距已经在很大程度上被消除了。 」

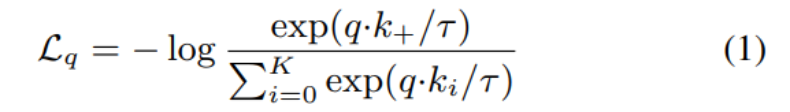
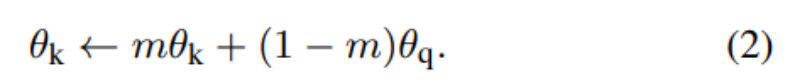



登录查看更多
相关内容


相关VIP内容
相关资讯
相关论文