ECCV 2020 Oral | 苏黎世联邦理工学院提出:弱监督语义分割新网络
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:阿柴和她的CV学习日记
注:论文已上传,文末附下载方式

论文地址:arxiv.org/pdf/2007.01947
代码地址:https://github.com/GuoleiSun/MCIS_wsss
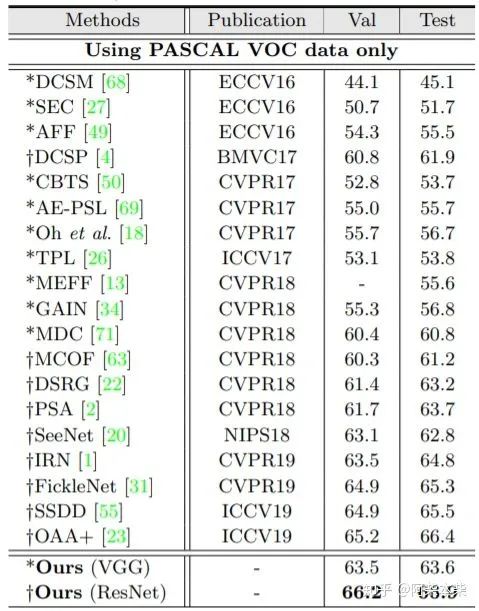
本篇文章沿着近几年弱监督语义分割(WSSS)的研究热点 — 如何改进CAM [1] 只能定位局部判别性区域,提出了不同之前只从改进分割网络结构或细化分类网络任务的的方法。作者采用跨图像(cross image)的方式,获得了更加丰富的图片间的上下文信息,从而实现了更高的精度。本篇文章在pacvoc 2012验证集上mIoU达到了66.2,在测试集上达到了66.9,均为最高。
一、简介
如果阅读过我之前关于弱监督语义分割(WSSS)的论文阅读笔记的读者,就一定知道弱监督语义分割从开始到现在的发展大致分为两个阶段。这两个阶段以CAM [1] 的出现为划分节点。在CAM这个方法出现之前,WSSS的研究呈现百花齐放的状态。这种状态体现在两个方面:
弱监督标签的多样性:这一阶段大家选择的弱监督标签是多样化的。有bouding box [2,3], Image level label [4,5], point [6], Scribble[7]等弱监督标签都在被研究用于WSSS。

方法的多样性:这一阶段大家也都还没有统一的思维和研究方向。拿Image level label这个弱标签来说,有用多示例的思想来做的,也有用resnet的中间特征图做优化来生成伪GT [5]的。但是实际上效果都不是很理想。
2016年,CAM出现之后,大大的提高了弱监督语义分割的精度,这使得大家的研究方向趋于统一:1)使用Image level label的弱标签,因为它标注起来最便捷,最能体现弱监督的“弱”;2)方法上,大家都开始使用CAM得到的定位图来训练语义分割网络。
由于CAM得到的定位图存在只能定位到局部具有判别力的区域,而更加全面的定位图显然可以训练出精度更高的模型。所以,近两年,有大量的工作都在研究如何改进分类网络的结构从而使得CAM的定位图更加的全面。比如:region hiding and erasing [8]、区域增长 [9]、多尺度上下文 [10]。
本篇文章同样沿袭了这一改进思路,但是思想上独辟蹊径。作者并没有专注于改进分类网络本身,而是使用两张有着共同标签的图片共同训练。并引入了两个注意力模块,一个来找寻两张图片所拥有的共同对象,另一个来找寻两张图片之间的不同对象。最后,作者详细的阐述了他所提出的得到定位图的方法。
二、方法(Cross image)
2.1、Overview
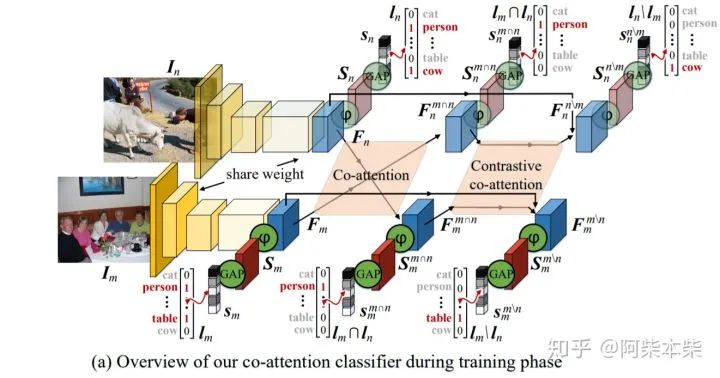
可以看到一直到Co-attention之前,所有的操作与之前通用的CAM的框架一致。都是用一个特征提取器比如resnet提取到图片对应的特征图Fn(Fm)。然后将Fn(Fm)送入相继送进全连接层、GAP。然后用image-level的标签作为监督信息,sigmoid cross entropy (CE)作为损失函数来训练网络。
作者与之前方法的区别在于,它用了两张图片同时训练。这两张图片是拥有共同的标签(person),当然也可能有不同的标签(cow、table)。所以作者在提取完Fn(Fm)又将其送入Co-attention模块之中以寻找两张图片共同的对象(person),然后送入Contrastive Co-Attenttion中去寻找两张图片不同的对象(cow、table)。下面我们来看看这两个注意力模块是怎么做的。
2.2、Co-Attenttion
作者首先计算了Fm与Fn之间的亲和力矩阵:
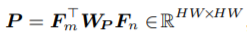
在计算过程中,Fm与Fn首先要flattened into 矩阵的形式。Wp是一个可学习的矩阵,它的大小为C×C。实际上这个亲和力矩阵的计算过程可以类比non-local。只不过non-local是计算自己和自己的相似度,所以non-local的原理也称为自注意力。而这里计算的是Fm和Fn之间的相似度。P的第(i, j)个元素给出了Fm中的第i个位置和Fn中的第j个位置之间的相似性。
然后对P进行列优先的softmax操作从而归一化:
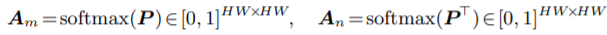
归一化之后实质上得到了两个注意力图Am与An。他们分别关注Fm与Fn中相似的特征。所以可以用Am与An分别与Fm和Fn对应相乘,使得Fm与Fn中相似的特征被highlight:

然后将相乘得到的结果同样相继送进全连接层、GAP。然后用image-level的标签作为监督信息,sigmoid cross entropy (CE)作为损失函数来训练网络。但是值得注意的是image-level的标签这里只用两张图片共有的标签。
以下是被highlight区域的可视化:

2.3、Contrastive Co-Attenttion
现在我们还只找到了相同的区域,还不能定位出不同的区域(cow、table)。所以作者设计了Contrastive Co-Attenttion。首先对Co-Attenttion的结果使用了1×1的卷积(Wb代表1×1卷积),来压缩通道得到一个共同区域的mask:
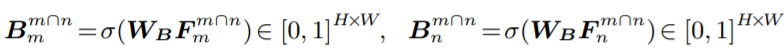
那么,1-该结果就得到了关注不同对象区域的注意力图:
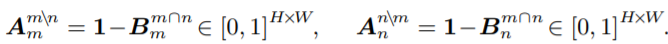
可以用Am与An分别与Fm和Fn对应相乘,使得Fm与Fn中不相似的特征被highlight:

然后将相乘得到的结果同样相继送进全连接层、GAP。然后用image-level的标签作为监督信息,sigmoid cross entropy (CE)作为损失函数来训练网络。但是值得注意的是image-level的标签这里只用两张图片不共有的标签。
以下是被highlight区域的可视化:

2.4、得到定位图的方法
对于一张图,从数据集中取出与其它有相同标签的所有图片。利用Co-Attenttion让这张图与这些图片对比,可以得到这张图中当前标签对应的目标在图中的区域。如果这张图还存在其他的标签,重复上述过程就可以了。当所有标签都被找完之后,便得到了最后的定位图。这个方法得到的定位图与CAM相比,由于存在图片间的上下文关系,所以该定位图定位的区域更加的全面而准确。
三、实验
作者做了很多的实验。这里我们只列出最标准的image-level设置的实验结果:

参考文献:
[1] CVPR_2016: Learning Deep Features for Discriminative Localization
[2] ICCV_2015:Exploiting Bounding Boxes toSupervise Convolutional Networks for Semantic Segmentation
[3] CVPR_2018: Simple Does It_Weakly Supervised Instance and Semantic Segmenta-tion
[4] ICLR_2015: Fully CONVOLUTIONAL MULTI-CLASS MULTIPLE INSTANCELEARNING
[5] ECCV_2016: Built-in Foreground/Background Prior for Weakly-SupervisedSemantic Segmentation
[6] ECCV_2016: What’s the Point: Semantic Segmentation with PointSupervision
[7] CVPR_2016: ScribbleSup: Scribble-Supervised Convolutional Networks forSemantic Segmentation
[8] ICCV_2017:Hide-and-seek: Forcing a network to be meticulous for weakly-supervised object and action localization
[9] Seed, Expand and Constrain: Three Principles forWeakly-Supervised Image Segmentation
[10] CVPR_2018: Revisiting Dilated Convolution:A Simple Approach forWeakly- and SemiSupervised Semantic Segmentation
下载
在CVer公众号后台回复:0719,即可下载本论文
重磅!CVer-图像分割交流群成立
扫码添加CVer助手,可申请加入CVer-图像分割 微信交流群,目前已满1500+人,旨在交流语义分割、实例分割、全景分割和医学图像分割等方向。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
点赞和在看!让更多CVer看见



