

**论文题目:**AutoAct: Automatic Agent Learning from Scratch for QA via Self-Planning **本文作者:**乔硕斐(浙江大学)、张宁豫(浙江大学)、方润楠(浙江大学)、罗玉洁(浙江大学)、周王春澍(波形智能)、姜昱辰(波形智能)、吕承飞(阿里巴巴)、陈华钧(浙江大学) **发表会议:**ACL 2024 **论文链接:**https://arxiv.org/abs/2401.05268 ****代码链接:https://github.com/zjunlp/AutoAct 欢迎转载,转载请注明出处

一、引言
现如今的大模型智能体尽管已经取得了一定的成就,但仍然存在两大问题:一方面,训练开源模型需要大量的带注释的问答数据对,并且仍然依赖闭源模型来合成规划轨迹。然而,在许多现实场景中,如私人个人机器人或敏感的公司业务中,满足这些要求往往会面临困难。另一方面,从智能体框架的角度来看,基于微调的方法迫使一个单一的语言智能体学习所有的能力,给它们带来了更大的压力。这与西蒙的有界理性原则(Simon’s principle of bounded rationality)相矛盾,该原则认为"明确的社会分工和清晰的个体任务可以弥补个体处理和利用信息的能力的有限性"。
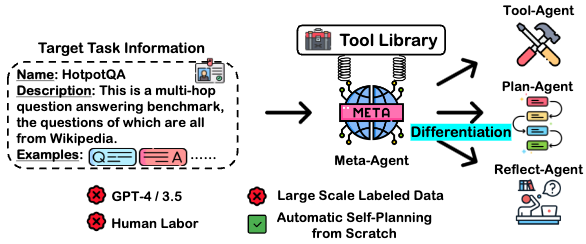
基于此,我们提出AutoAct,一个用于问答的自动化智能体学习框架,它不依赖于大规模带注释的数据和闭源模型生成的合成轨迹,同时引入了精确的个体任务分工。
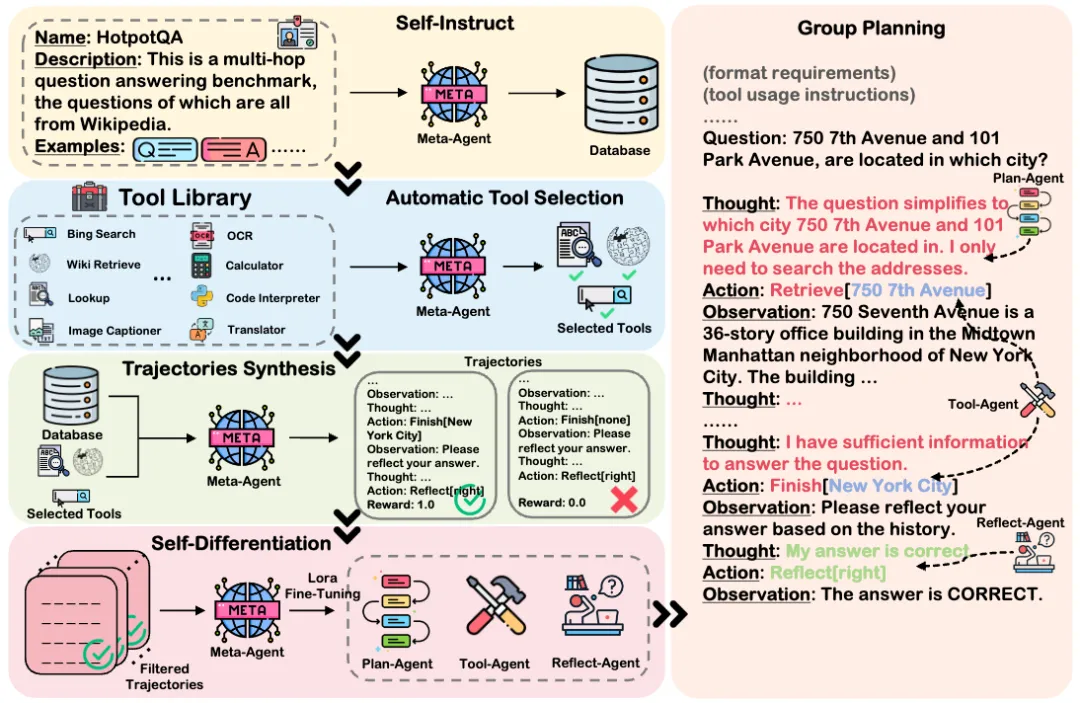
二、方法
开始阶段,AutoAct包含三个重要的组件:
1)Meta-Agent。Meta-Agent负责自我分化之前的所有准备工作,并且作为分化后各个子智能体的底座模型。给定少量任务信息和一个工具库,Meta-Agent可以分化成一个agent团队来协作完成任务。 2)目标任务信息。目标任务信息更像是一个任务的名片,主要包含任务名称、任务描述和任务的极少量数据样例(满足from scratch)。 3)工具集。工具集包含解决所有常见问答任务所需要的外部工具,每条工具包含具体地工具名称、工具描述以及工具使用方法。 有了三个组件后,AutoAct首先根据极少的数据样例进行数据增强,具体让Meta-Agent通过self-instruct的方式合成QA对,以达到足够训练的标准。随后给定目标任务信息,Meta-Agent被指使从工具集中选择适合完成目标任务的工具集合,并使用这些工具在之前合成的QA数据上合成规划轨迹,最后通过答案是否正确过滤掉低质量的轨迹数据。在分化阶段,AutoAct根据预先定义的分工,将原始的合成轨迹数据重组为各个子智能体需要的输入输出,并以LoRA的方式以Meta-Agent为底座训练出各个子智能体,完成类似细胞分化的过程。这里我们的子智能体包含三类: 1)规划智能体:负责任务的拆解和决定调用哪种工具。 2)工具库智能体:决定具体调用工具的参数,即如何调用工具。 3)反思智能体:根据答案的正确性对历史轨迹进行反思。 推理阶段,各个子智能体根据自己的职责协作完成任务。
三、主要实验
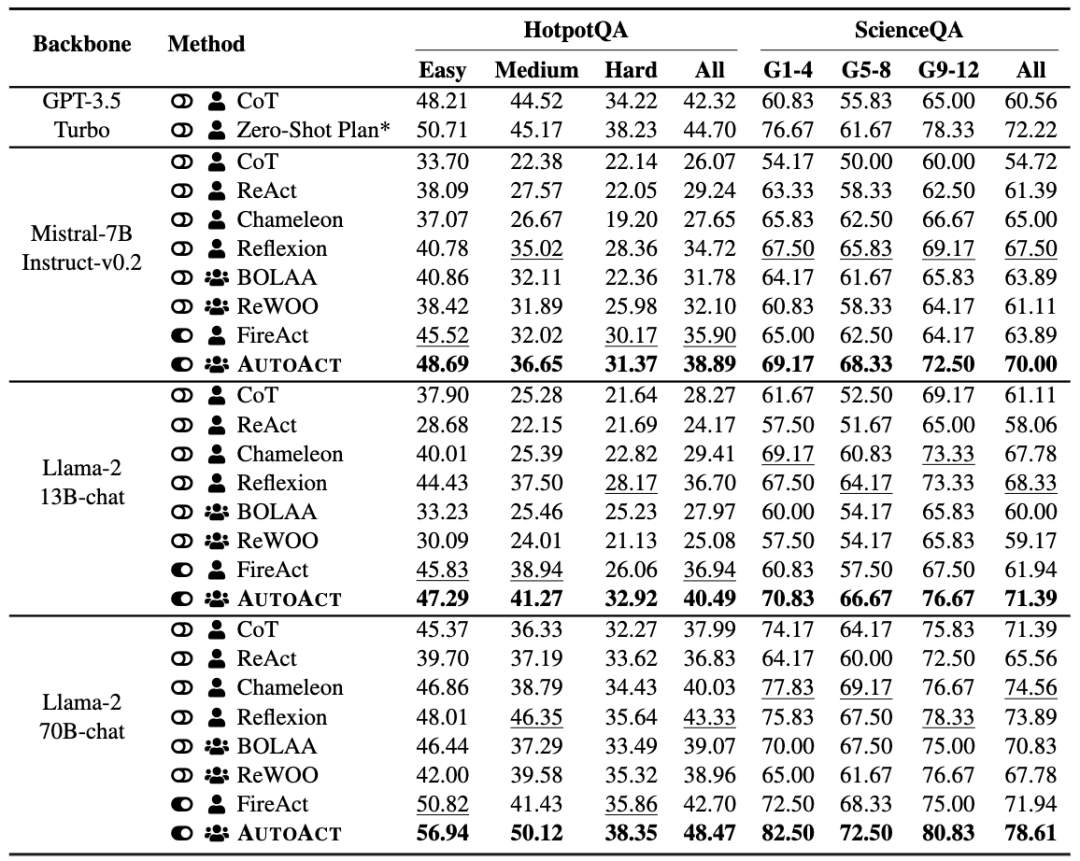
我们在两个复杂QA数据集上以及Mistral-7B、Llama-{7,13,70}B模型上进行了实验。如上表所示,AutoAct相比于各种baseline都取得了较好的效果。特别是相比于FireAct(训练数据基于GPT-4模拟),AutoAct在不基于大量标注数据的前提下,也能表现出色。另外,AutoAct的多智能体分工架构也是取得较好效果的关键因素。
如上表所示,进一步的消融实验也可以说明多智能体分工架构和微调的重要性。此外,一个有意思的发现是在数据合成阶段,基于问题答案的正确性进行数据过滤也是AutoAct取得不错效果的重要因素,可以发现在未经过滤的数据上进行训练,模型的表现甚至不如不微调的表现。
四、分析
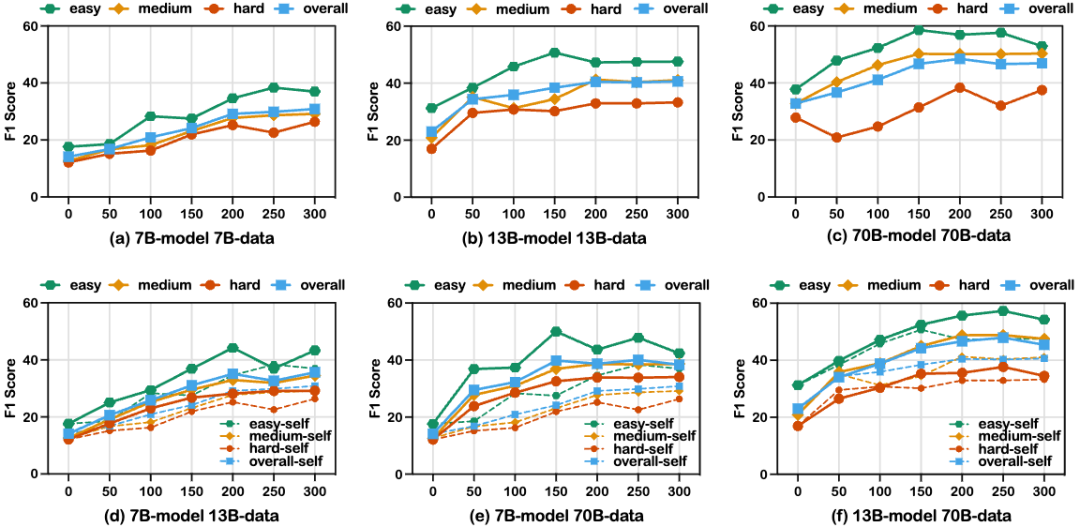
我们针对训练阶段的合成数据数量进行了探究,发现训练数据越多并不一定能带来更好的效果。如上图(a-c)所示,不同规模的Llama-2模型几乎都在200条训练数据时性能达到最好,超过200条数据模型的表现几乎不变甚至下降。我们推测这是由于self-instruct阶段的数据多样性造成的。另外我们让更大模型合成的数据在更小模型上进行训练(d-f),发现性能可以有进一步提升,这也印证了模型规模越大。合成数据的质量一般越高。

针对不同细粒度分工,我们也发现适当的分工才有利于规划的表现。我们进一步将工具智能体进行细分,根据工具的不同将每一种工具对应一个智能体进行训练,实验结果如上图所示,在所有模型上,AutoAct的分工方式都取得了最好的效果。反而更精确的分工(Tool-Specified)效果不如三个子智能体的协作表现。
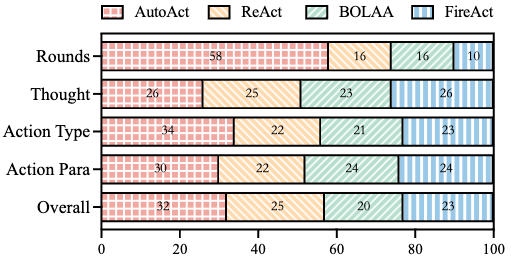

对于AutoAct和其他baseline生成的轨迹我们也进行了全方位的人工评估。发现AutoAct尤其在工具调用的种类和参数的准确度上有更好的表现,在总体质量上AutoAct生成的轨迹也好于FireAct等。然而AutoAct倾向于生成更多轮数的规划轨迹来完成任务,进一步的Case分析发现,这一特性是一把双刃剑,可以使AutoAct对自己生成的答案借助工具进行校准,但也会生成长文本导致轨迹跑偏。
五、总结
在本论文中,我们提出了AutoAct,一个自动代理学习框架,用于问答任务,它不依赖于大规模带注释的数据和闭源模型生成的合成轨迹,并通过明确分工来减轻个体代理的压力。有趣的未来方向包括:i)将AutoAct扩展到更加逼真的任务场景;ii)通过自我指导来增加更多的知识;iii)通过自我改进迭代地提升合成轨迹的质量。
