AAAI 2020 | 中科大:智能教育系统中的神经认知诊断,从数据中学习交互函数
 作者 | 陈恩红、刘淇团队
作者 | 陈恩红、刘淇团队

论文链接:https://arxiv.org/abs/1908.08733v1
认知诊断与智慧教育
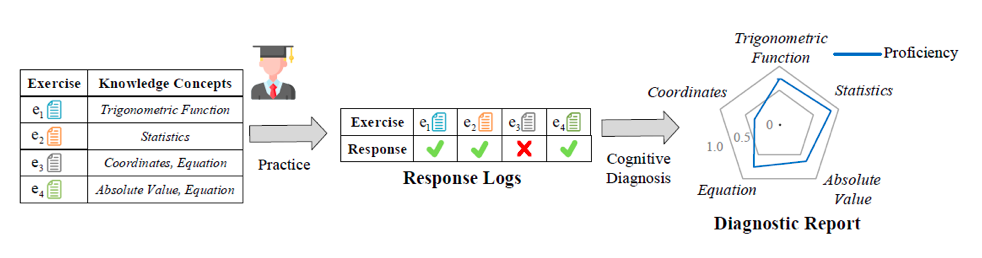
图1 认知诊断示例
 ,而
包含“三角函数”(Trigonometric Function)这个知识点,因此诊断出来该学生对于“三角函数”这个知识点掌握程度较高(例如0.8),反映到诊断报告的雷达图中蓝线靠近外侧。
认知诊断的结果可以被用作教育资源推荐、学生表现预测、学习小组分组等后续教育应用中。
,而
包含“三角函数”(Trigonometric Function)这个知识点,因此诊断出来该学生对于“三角函数”这个知识点掌握程度较高(例如0.8),反映到诊断报告的雷达图中蓝线靠近外侧。
认知诊断的结果可以被用作教育资源推荐、学生表现预测、学习小组分组等后续教育应用中。
背景


DINA模型中,学生i与试题j之间的关系被建模为:
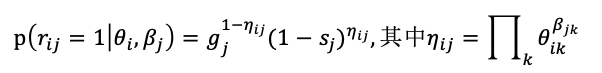
式中 

基于神经网络的认知诊断
 ,试题集合
,试题集合
 ,知识点集合
,知识点集合
 。学生的答题记录可以表示为三元组
。学生的答题记录可以表示为三元组
 的集合
的集合
 ,其中
,其中
 ,
,
 ,
,
 是学生
是学生
 在试题
在试题
 上的得分(转换为百分比)。此外,有将试题与知识点关联的Q矩阵
上的得分(转换为百分比)。此外,有将试题与知识点关联的Q矩阵
 (例如,有教研专家提前标注)。
和 Q 矩阵
(例如,有教研专家提前标注)。
和 Q 矩阵
 ,我们的认知诊断的任务是通过学生答题预测的过程获取学生在各个知识点上的掌握程度。
,我们的认知诊断的任务是通过学生答题预测的过程获取学生在各个知识点上的掌握程度。
2、神经认知诊断框架
使用神经网络做认知诊断并不容易,一个主要的原因是其广为诟病的“黑盒”特性,即模型参数难以解释,而认知诊断需要得到学生在各个知识点上的掌握程度,因此这是必须跨越的障碍。同时神经网络也带来了新的机遇,其强大的拟合能力使其能够从数据中学到更为复杂且贴近现实的交互函数,且神经网络在自然语言处理方面取得的成功也使将试题文本运用到认知诊断成为可能。
几乎所有传统认知诊断方法都包括学生参数、试题参数、学生与试题交互函数这三个部分,其合理性已被大量工作验证,因此神经认知诊断框架NeuralCD亦沿用此方式,其结构如图2:
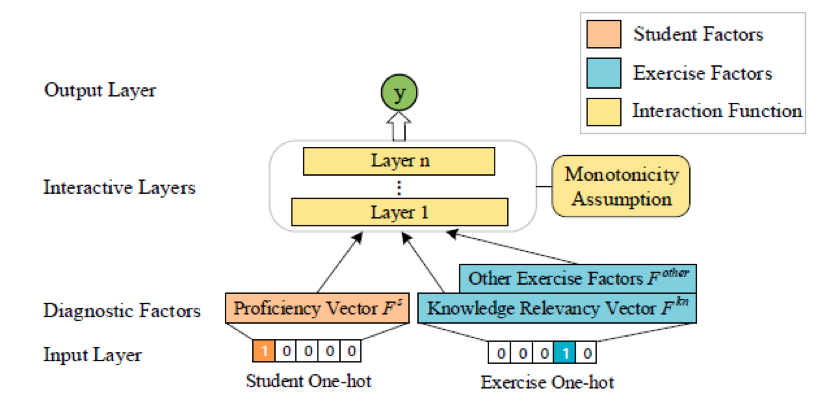
NeuralCD将认知诊断分为三个部分:学生因素、试题因素和交互函数(在图中分别用不同颜色标注)。学生因素最基本的是知识点熟练度向量 


为了确保训练结束后得到的
1. 输入层需要包含 

2. 对多层神经网络使用“单调性假设”来约束。单调性假设是教育心理学方法中常用的假设,其内容是:学生答对试题的概率随学生任意一维知识点熟练度单调递增(不需要严格单调)。换句话说,在训练过程中,若模型的预测值小于真实得分,则需要提高该学生的
3、神经认知诊断模型(Neural Cognitive Diagnosis Model, NeuralCDM)
在NeuralCD的框架下,我们做了一个模型实现,其结构如图3:
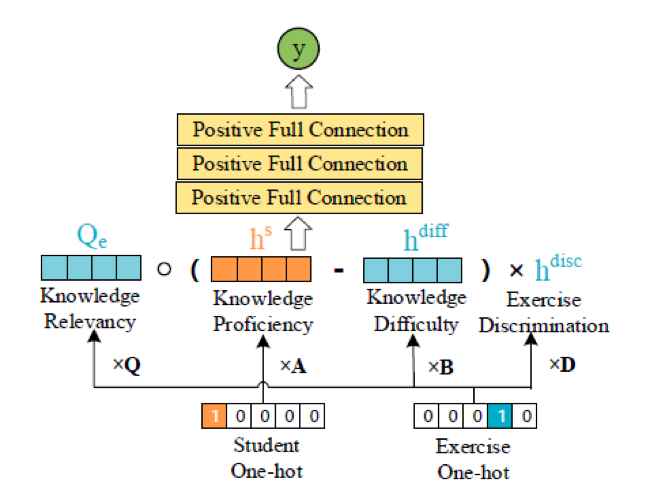
学生的知识点熟练度向量(对应前述的 








NeuralCDM不追求模型的复杂性,而是为验证NeuralCD的有效性,因而其交互函数由最常见的多层全连接层构成。为满足单调性假设,我们限定每一层的权值为正(可部分为0),这样 



训练结束后,学生对应的 
4、利用试题文本对NeuralCD扩展
试题文本与试题信息是十分相关的,例如通过试题文本预测试题的难度、区分度、知识点等。这里我们不对所有相关性进行讨论,而是选取其中的一种展示NeuralCD的可扩展性。
在NeuralCDM和一些传统方法(如DINA)中,通过Q矩阵获取试题与知识点的关联信息。然而,人工标注的Q矩阵不可避免地主观性甚至错误。例如,对于一道解方程的问题,专家可能只标注了其中的主要考点“Equation”,但是却忽略了其中乘除法的知识点。而通过试题文本,发现其中包含除法符号“÷”,可以将此知识点补充。基于此,我们利用试题文本对NeuralCDM进行扩展,记为NeuralCDM+,其结构如图4:
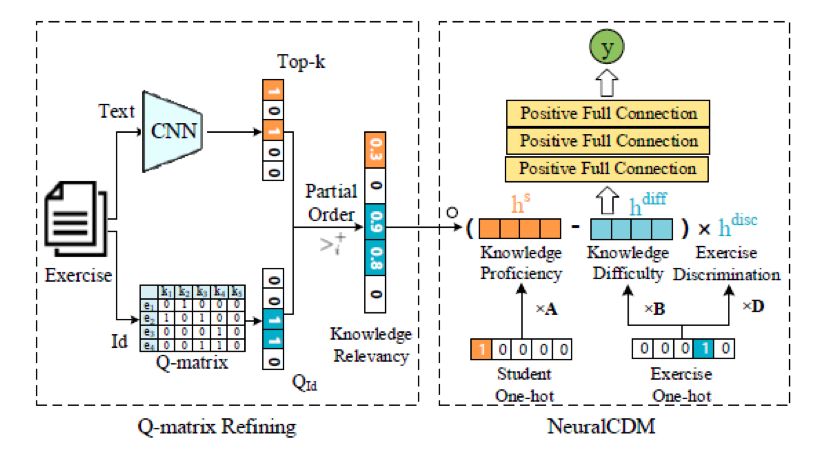
我们首先预训练了一个卷积神经网络(CNN),输入试题文本来预测与试题相关的知识点,取其输出的Top-k知识点集合 
接下来我们通过将 

这是因为尽管人工标注的Q矩阵存在部分缺点,但仍然具有较高的可信度,因此Q矩阵中标注的知识点最有可能有较高的相关度。而既非标注也未被预测的知识点则认为是与该题无关。我们采用概率模型的方式来实现这一偏序关系,并最终得到经文本预测补充的知识点相关度矩阵
5、NeuralCD的泛化性
NeuralCD是泛化性较强的认知诊断框架,一些传统的认知诊断模型可被视为NeuralCD的特例(如矩阵分解、IRT、MIRT等)。例如,IRT与NeuralCD的关系可被下图5概括,
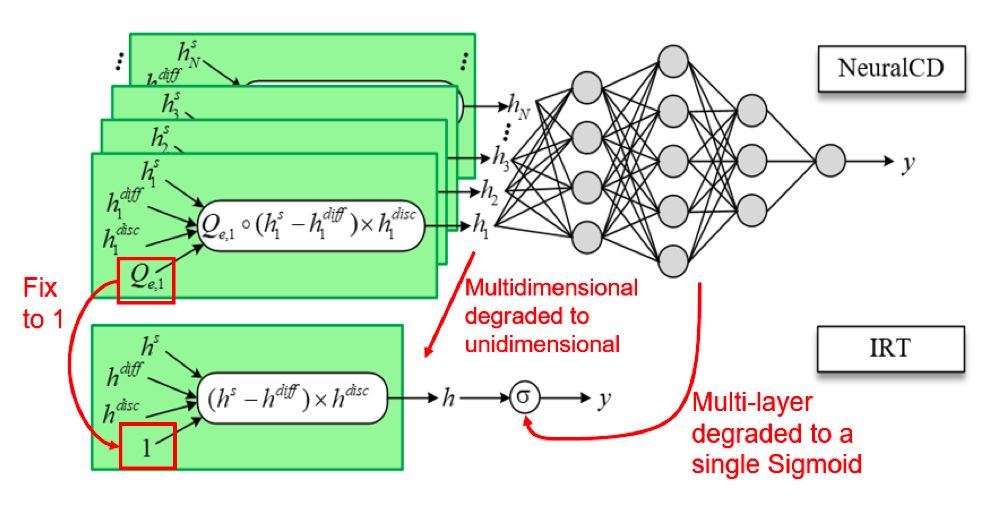
若将NeuralCD从多维退化至一维,知识相关度向量固定为1,并且神经网络构成的交互函数退化为单个Sigmoid函数,模型就退化成了IRT。其他示例和具体推导请参阅论文。
实验
实验在两个数据集上进行。一个是科大讯飞的在线学习平台智学网提供的私有数据集Math,包含多所高中的期末考试试题、文本和答题记录。另一个是公开数据集ASSISTment 2009-2010 Skill-Builder,包含数学试题和学生答题记录。由于后者没有提供试题文本,所以NeuralCDM+并未在该数据集上进行实验。
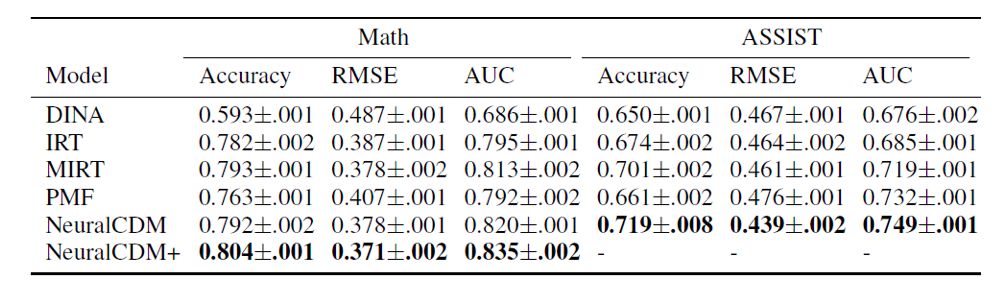
1、学生答题预测
学生真实的知识点熟练度标签是无法获取的,因此我们采用间接衡量诊断结果准确性的方法,即使用学生的诊断结果来预测学生的在非训练数据中试题的得分,这也是传统认知诊断模型的常规做法。实验的结果如下表1,我们的NeuralCD模型在两个数据集中相较传统模型取得了较大的提升。
2、解释性度量
我们希望学生的诊断结果能够符合直觉上的预期:若学生 





式中 








计算模型诊断结果中平均每个知识点的DOA值,各个模型的结果如下图6:
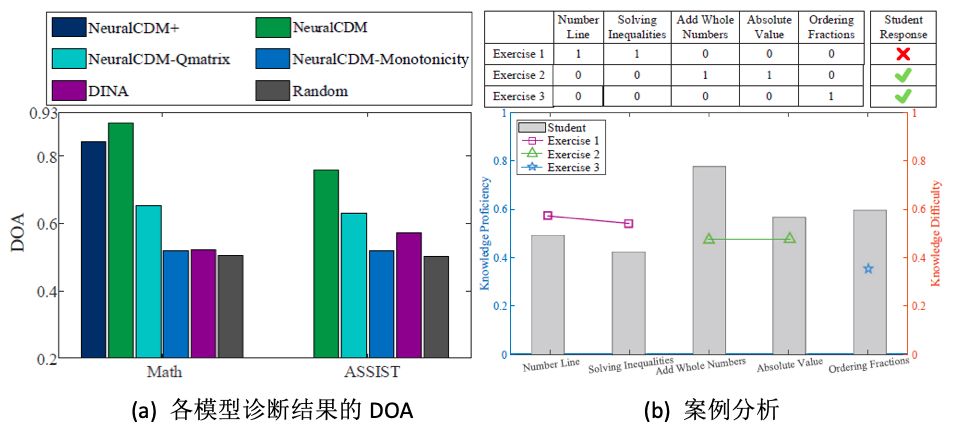
(a)(部分基准模型未做因为其学生向量没有与知识点的对应关系)。(b)是ASSIST数据集中一个学生诊断结果的实例。
上半部分为3道试题的Q矩阵和对应的实际答题结果,下半部分的柱形图为该学生在各个知识点上的诊断出的熟练度,数据点代表3道题所包含知识点的考察难度。诊断结果中,当学生对知识点的掌握程度超过试题的要求时,更有可能答对试题。例如试题2中包含“Add Whole Numbers”和“Absolute Value”这两个知识点,难度分别为0.47和0.48,而该学生在这两个知识点上的掌握度分别为0.77和0.56,超过了难度需求,因此答对了该题。诊断的结果是符合常识认知的。
结语
随着智慧教育的兴起,认知诊断会成为备受重视的任务。传统的认知诊断方法已不在适应当前的多学科、大数据量、异构数据类型的场景。使用神经网络进行认知诊断是值得探索的方向。本文还是初期的探索,在理论上、模型结构上还有许多可以提升的地方,留待未来工作完善。
论文的NeuralCDM代码已公开至https://github.com/bigdata-ustc/NeuralCD,该团队智慧教育研究组的主页:http://base.ustc.edu.cn/。
更多AAAI 2020信息,将在「AAAI 2020 交流群」中进行,加群方式:添加AI研习社顶会小助手(AIyanxishe2),备注「AAAI」,邀请入群。

AAAI 2020 论文解读系列:
13. [中科院自动化所] 通过解纠缠模型探测语义和语法的大脑表征机制
14. [中科院自动化所] 多模态基准指导的生成式多模态自动文摘
16. [UCSB 王威廉组] 零样本学习,来扩充知识图谱(视频解读)
18. [奥卢大学] 基于 NAS 的 GCN 网络设计(视频解读)








