赛尔原创 | ACL 2019 机器阅读理解中不可答问题的数据增广
论文名称:Learning to Ask Unanswerable Questions for Machine Reading Comprehension
论文作者:朱海潮,董力,韦福如,王文辉,秦兵,刘挺
原创作者:哈工大 SCIR 博士生 朱海潮
论文链接:https://arxiv.org/abs/1906.06045
1. 背景介绍
机器阅读理解在近两年取得了非常巨大的进步,当答案为文档中的一个连续片段时,系统已经可以十分准确地从文档中抽取答案,在大规模基准数据集SQuAD上甚至取得超越了人类的表现。然而在现实生活中,往往无法保证给定的文档一定包含某个问题的答案,这时阅读理解系统应拒绝回答,而不是强行输出文档中的得分最高的一个片段。
针对这一问题,本文提出根据可答问题、原文和答案来自动生成相关的不可答问题,进而作为一种数据增强的方法来提升阅读理解系统的表现。利用现有阅读理解数据集(SQuAD 2.0)来构造不可答问题生成模型的训练数据;引入Pair2Seq作为问题生成模型来更好地利用输入的可答问题和原文。
2. 数据构造

图1 SQuAD 2.0数据示例,段落中的答案以高亮方式标示,作为线索对齐可答与不可答问题
SQuAD 2.0数据集包含超过5w个不可答问题,并且为不可答问题标注了一个看起来正确的答案(plausible answer)。上图展示了SQuAD2.0中一个文档和相应的可答与不可答问题,可以看到这两个问题的(plausible)答案对应到同一个片段,用词十分相似且答案具有的类型(所示例子中为organization),通过对可答问题进行修改就能得到相应的不可答问题。基于这个观察,作者以被标注的文本片段为线索来构造训练问题生成模型所需的数据。
3. 模型
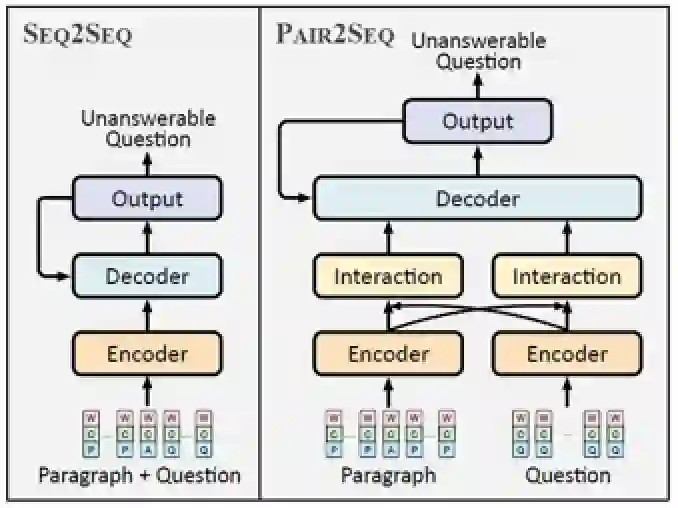
图2 Seq2Seq模型与提出的Pair2Seq模型示意图,输入为word embeddings、character embeddings和the token typeembeddings之和
在阅读理解系统中,问题与文档的交互是最为关键的组成部分,受此启发本文提出Pair2Seq模型,在编码(encoding)阶段通过注意力机制(attention mechanism)使问题和文档进行交互,得到基于问题的原文表示和基于原文的问题表示,并共同用于解码(decoding)。为了能够更有效地利用输入的单词来生成不可答问题,在解码时还采用了复制机制(copy mechanism),将文档和输入的可答问题中的词复制到输出中。
4. 实验结果
问题生成的实验结果如下表所示,Pair2Seq模型能够比Seq2Seq模型生成更好的不可答问题,且输入的可答问题起着十分重要的作用。
表1 问题生成自动评价结果
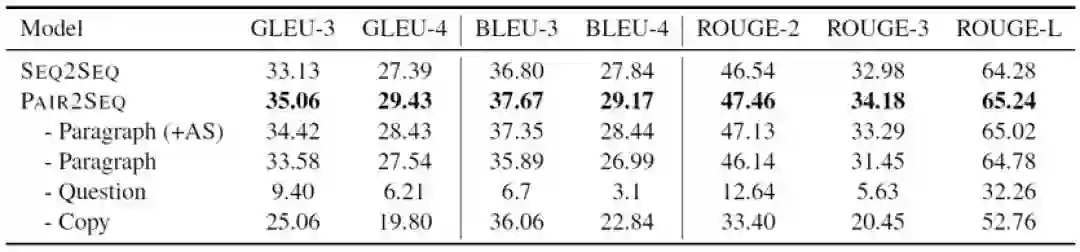
通过在SQuAD2.0数据集上的实验,结果如下表所示,生成的不可答问题作为增强数据能够提高若干不同机器阅读理解模型的表现,在BERT-Base模型上取得了1.9 F1提升,在BERT-Large模型取得了1.7 F1提升。
表2 在SQuAD2.0数据集上的数据增广实验结果,△表明的是绝对提升
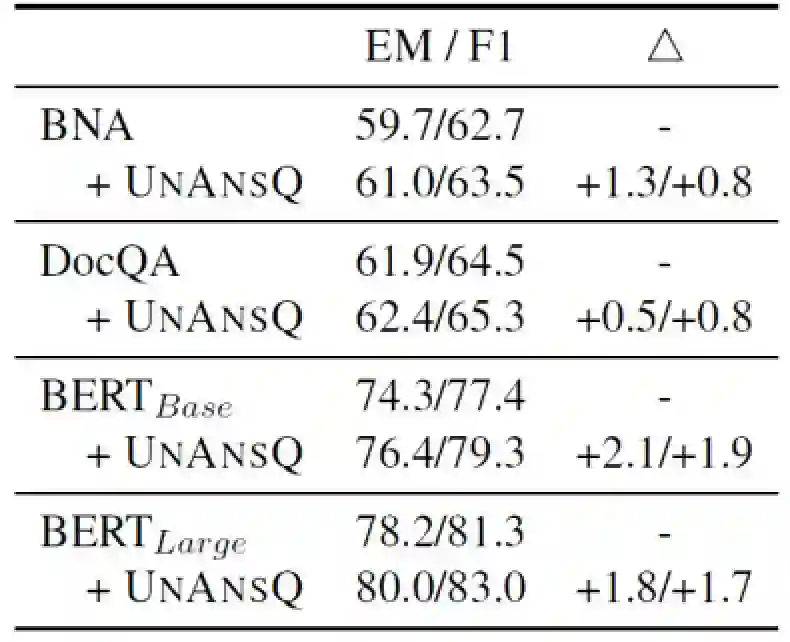
另外,对比不同的不可答问题生成方法,如使用可答问题通过TF-IDF来检索其他文档的问题,或者在可答问题中加入反义词、替换实体等规则构造不可答问题。从下表中可以看到,使用Pair2Seq模型生成的不可答问题作为增强数据取得了最大的提升。
表3 增广数据生成方法对比实验结果
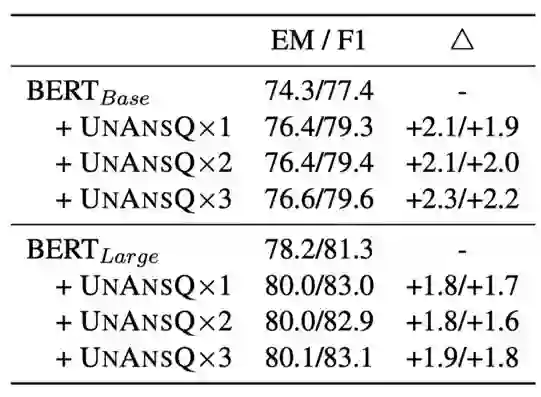
为了检验增强数据规模对阅读理解系统的影响,本文通过beam search来为每个输入样本生成多个不可回答问题,在BERT-base和BERT-large模型上进行实验,结果如下表所示,在较小的BERT-base模型上,扩大增强数据规模能够取得进一步的提升,但数据规模对BERT-large模型几乎没有影响。
表4 增广数据规模对比实验结果,“× N”表示数据扩充倍数
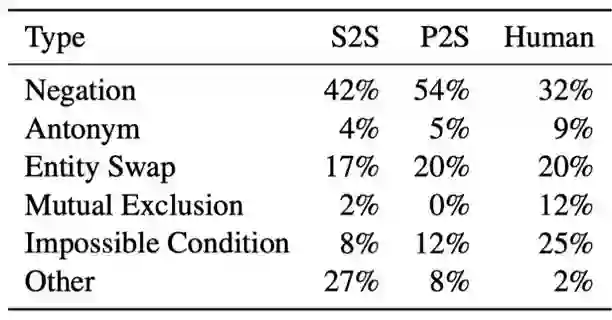
Rajpurkar等将SQuAD2.0中的不可答问题分为六类,基于这个标准,本文将生成的不可答问题进行分类统计,从下表中可以看到,自动生成的不可答问题主要由加入否定词和实体替换两类组成,与SQuAD 2.0数据集中人类生成的问题类型分布有较大的差别,类型相对也较单一。
表5 不可答问题类型统计结果,类型具体定义请参考(Rajpurkar et al., 2018)
本期责任编辑:刘一佳
本期编辑:赖勇魁
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,刘一佳,崔一鸣
编辑: 李家琦,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。





