【泡泡图灵智库】竞争协作:深度,相机运动,光流和运动分割的联合无监督学习(CVPR)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Digging Into Self-Supervised Monocular Depth Estimation
作者:Clement Godard, Oisin Mac Aodha, Michael Firman, Gabriel Brostow
来源:CVPR 2019
编译:李伟
提取码:22me
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——Digging Into Self-Supervised Monocular Depth Estimation。
本文解决了几个相互关联的低等级视觉的无监督学习问题:单一视角的深度估计,相机位姿估计,光流,静态场景和移动区域的分割。我们的主要观点是将这四个基本的视觉问题通过几何约束耦合在一起。因此,学习一起解决它们简化了问题,因为解决方案可以相互加强。我们通过利用更明确的几何约束和分割静止场景和移动区域超过了以前的方法。为此,我们引入了竞争协作(Competitive Collaboration),这是一个促进多个专业神经网络协调训练以解决复杂问题的框架。竞争协作的工作方式与期望最大化非常相似,但神经网络既可以作为对应于静态或移动像素的竞争者,也可以作为将像素分配为静态或独立移动的协作者。我们的方法将这些问题集合到一个通用的框架里面,同时解释了将场景分割为移动物体和静态场景,相机的运动,静态场景结构的深度和移动物体的光流。我们的模型采用无监督学习的训练方法,达到了SOTA。
主要贡献
1.提出了竞争协作(Competitive Collaboration),一种无监督学习的框架,针对特定的任务,网络既充当竞争者也充当协作者。
2.表明了联合训练多个网络具有协同作用
3.第一个采用无监督学习的方法利用低级信息比如深度,相机位姿,光流等解决分割任务。
4.实现了无监督学习单一视角深度估计和相机位姿估计的SOTA,实现了无监督学习关于场景几何光流的SOTA,引入了无监督学习运动分割的baseline。
5.分析了我们的方法的收敛性能
算法流程
1、核心方法
在本文的特定场景中,竞争协作(CC)是一个三人游戏,两个玩家竞争,第三个玩家协调资源。如图1所示,我们的框架引入了两个竞争玩家,其中一个玩家为静态场景重建器R=(D,C),他利用深度D和相机运动C来重建静态场景,另一个玩家为移动区域重建器F,他预测单独移动区域的像素。这两个通过推断图形序列中的静态场景和运动区域来竞争训练数据。这两个竞争对手由运动分割网络M来调节分配静态场景和运动区域。因此R和F合作训练调节者M。这个框架与最大期望方法(EM)相似。

图1 网络框架
2、竞争协作
如图2所示,我们将训练分为两个阶段,第一阶段固定调节者M,最小化式1(竞争阶段),第二阶段竞争对手{R,F}形成共识训练调节者M,使其能正确的分割静态场景与运动物体,最小化式2(合作阶段)
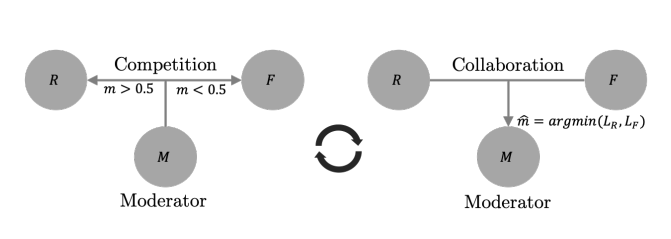
图2 竞争协作两个训练阶段

公式1 竞争阶段最小化函数
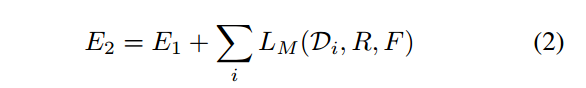
公式2 协作阶段最小化函数
2、损失函数
如公式3所示,损失函数由5项组成,其中ER为利用深度和相机位姿计算的光学重建误差,EF为利用光流计算的光学重建误差,EM为标签始终为1的交叉熵,EC为深度估计和光流估计之间达成共识来约束掩膜分割对象的损失函数,ES为局部光滑损失。
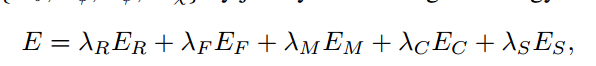
公式3 损失函数
2.3 多尺度估计
如下图3所示,本文将不同尺度的depthmap进行上采样至输入图像的分辨率,然后再计算光学误差。该方法可以有效的约束每个尺度的深度图都朝着重建高分辨率的目标图像这个目标。
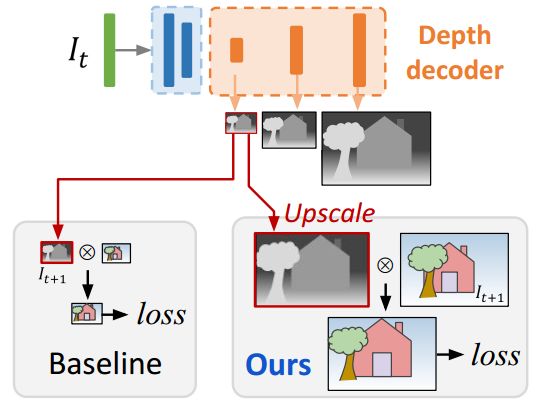
图3 全分辨率多尺度采样
3、网络构架
深度估计采用DispNet和DIspResNet(将卷积块替换为残差块),光流估计采用FlowNet和PWC-Net,掩膜网络采用编解码的结构。
主要结果
我们在KITTI2015数据集上测试了该网络构架的效果。
1、单目深度与相机运动估计结果
如下表1和表2所示,为我们在KITTI数据集上对单目深度的估计达到了SOTA。如表3所示,相机运动的估计也取得了较好的结果,在序列09和序列10上甚至超过了带有闭环检测的sequence09和10.
表1 KITTI数据集上不同方法深度估计结果
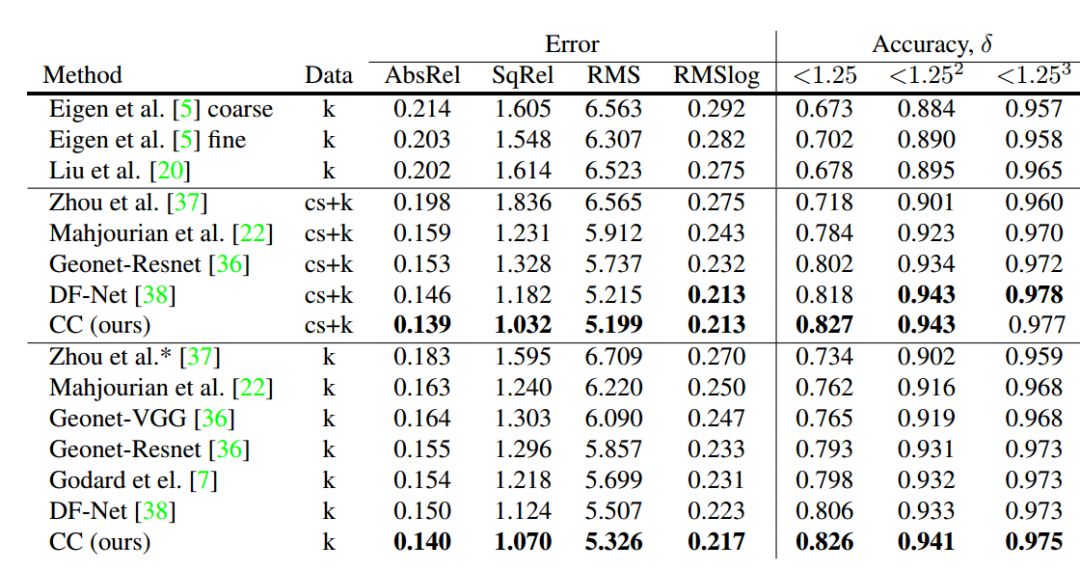
表2 KITTI数据集上裁减测试深度估计结果
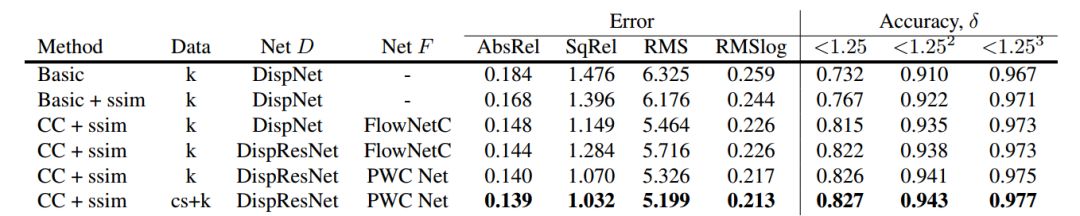
表3 KITTI数据集上不同方法位姿估计结果

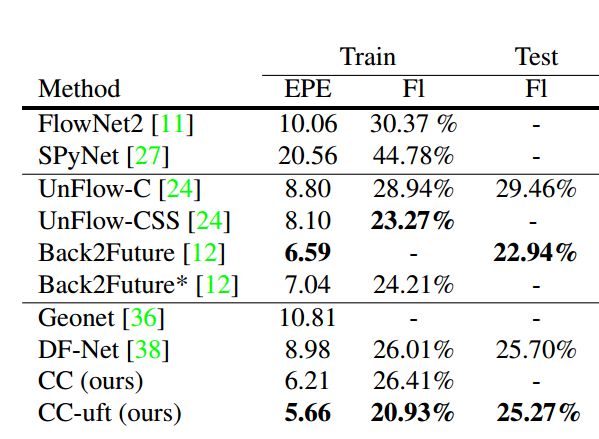
2、光流估计
如下表4所示,为在KITTI2015数据集上不同方法进行的光流估计结果。
表4 在KITTI数据集上光流估计的结果
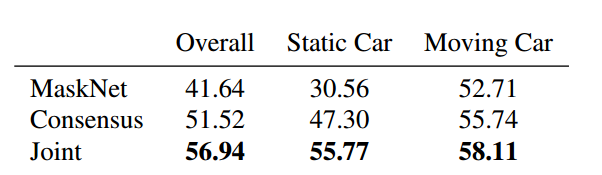
3、掩膜估计
如下表5所示,为在KITTI2015数据集上运动分割的结果。
表5 KITTI数据集上运动分割的结果
Abstract
We address the unsupervised learning of several interconnected problems in low-level vision: single view depth prediction, camera motion estimation, optical flow, and segmentation of a video into the static scene and moving regions. Our key insight is that these four fundamental vision problems are coupled through geometric constraints. Consequently, learning to solve them together simplifies the problem because the solutions can reinforce each other. We go beyond previous work by exploiting geometry more explicitly and segmenting the scene into static and moving regions. To that end, we introduce Competitive Collaboration, a framework that facilitates the coordinated training of multiple specialized neural networks to solve complex problems. Competitive
Collaboration works much like expectation-maximization, but with neural networks that act as both competitors to explain pixels that correspond to static or moving regions, and as collaborators through a moderator that assigns pixels to be either static or independently moving. Our novel method integrates all these problems in a common framework and simultaneously reasons about the segmentation of the scene into moving objects and the static background, the camera motion, depth of the static scene structure, and the optical flow of moving objects. Our model is trained without any supervision and achieves state-of-the-art performance among joint unsupervised methods on all sub-problems.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



