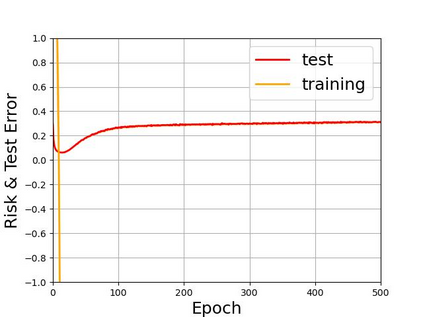
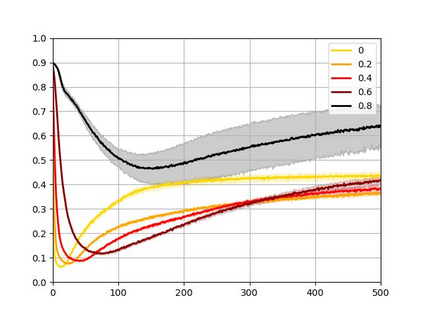
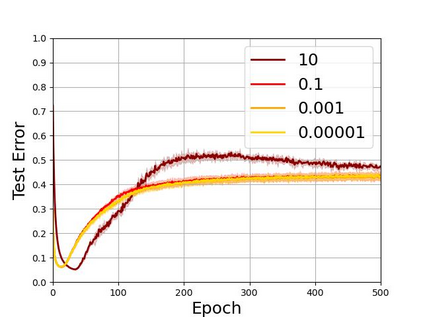
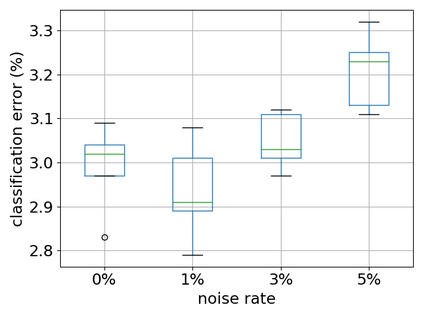
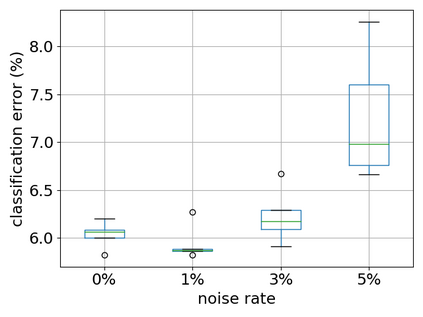
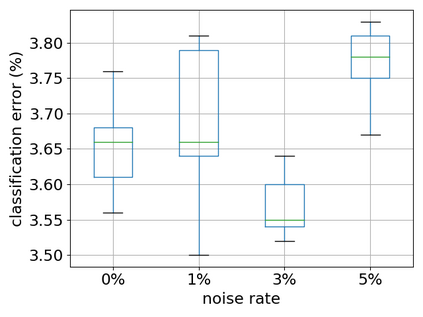
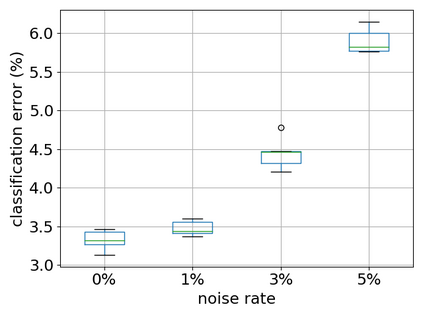
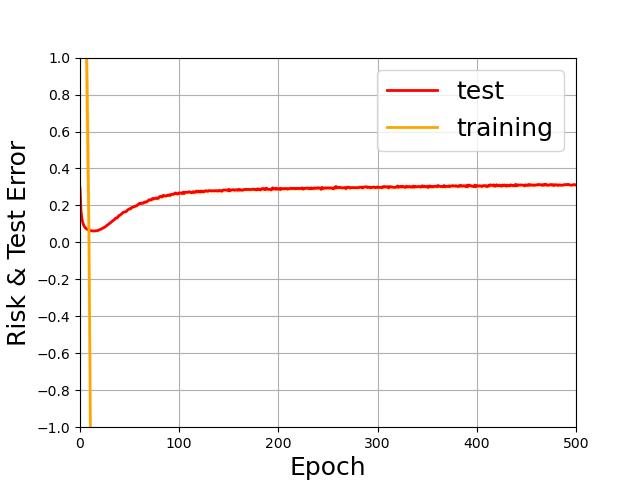
Recent years have witnessed a great success of supervised deep learning, where predictive models were trained from a large amount of fully labeled data. However, in practice, labeling such big data can be very costly and may not even be possible for privacy reasons. Therefore, in this paper, we aim to learn an accurate classifier without any class labels. More specifically, we consider the case where multiple sets of unlabeled data and only their class priors, i.e., the proportions of each class, are available. Under this problem setup, we first derive an unbiased estimator of the classification risk that can be estimated from the given unlabeled sets and theoretically analyze the generalization error of the learned classifier. We then find that the classifier obtained as such tends to cause overfitting as its empirical risks go negative during training. To prevent overfitting, we further propose a partial risk regularization that maintains the partial risks with respect to unlabeled datasets and classes to certain levels. Experiments demonstrate that our method effectively mitigates overfitting and outperforms state-of-the-art methods for learning from multiple unlabeled sets.
翻译:近些年来,监督深层学习取得了巨大成功,通过大量贴上完整标签的数据对预测模型进行了培训。然而,在实践中,贴上这种大数据标签可能非常昂贵,甚至可能由于隐私原因无法做到。因此,在本文件中,我们的目标是在没有任何分类标签的情况下,学习准确的分类器。更具体地说,我们考虑的是多套未贴标签的数据,而只有其类别前科,即每个类别的比例,存在多套未贴标签的数据,我们考虑的情况。在设置这一问题下,我们首先从理论上分析从给定的未贴标签数据集中可以估计到的分类风险,并从理论上分析所学的分类器的普遍错误。我们随后发现,获得的分类器在培训中往往会造成过度适应,因为其实证风险是负面的。为了防止过度配置,我们进一步提议部分风险规范,在未贴标签数据集和班级到某些级别时,保持部分风险。实验表明,我们的方法有效地减轻了从多套未贴标签的分类器中学习的过度和超常规方法。