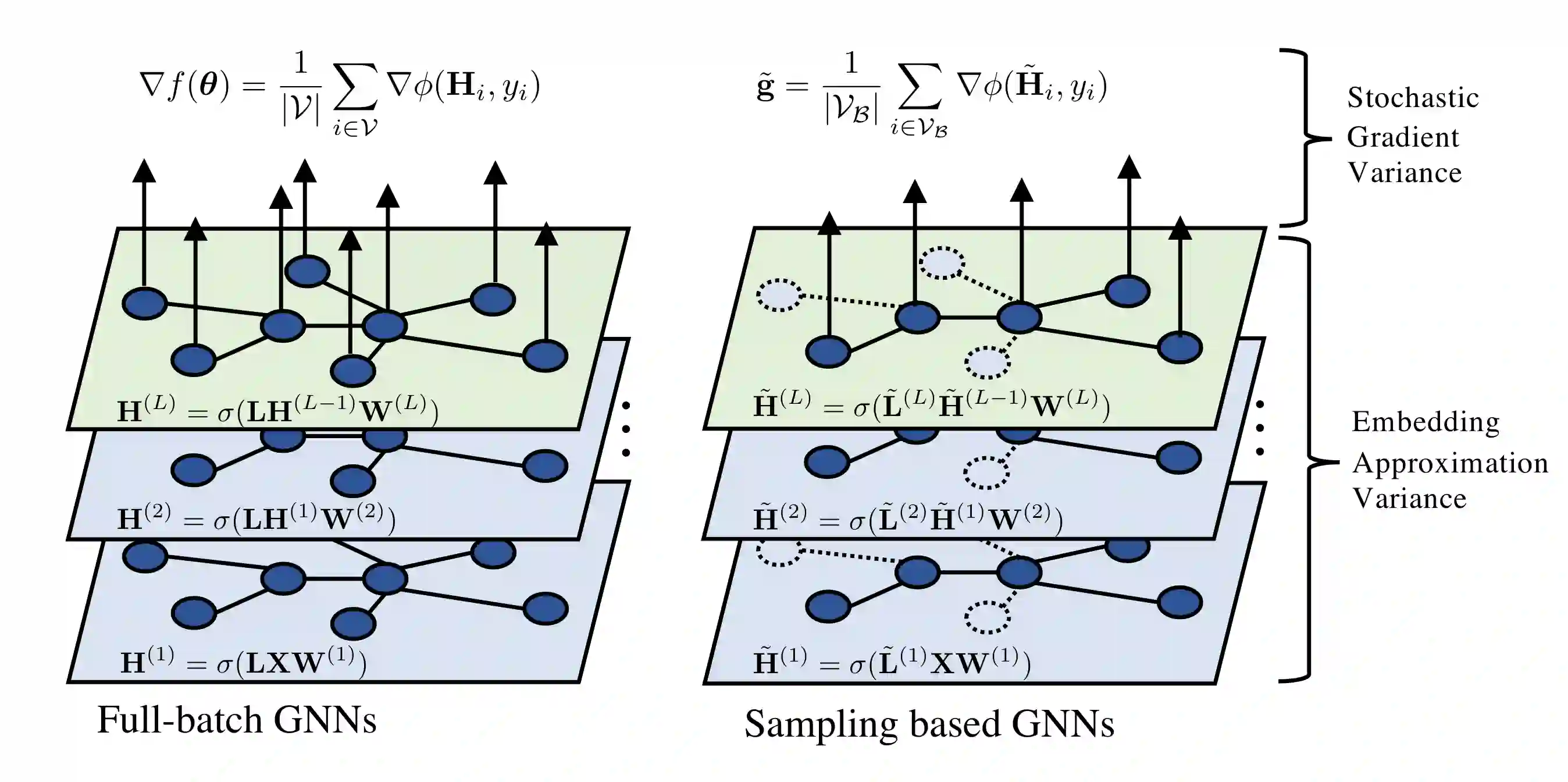
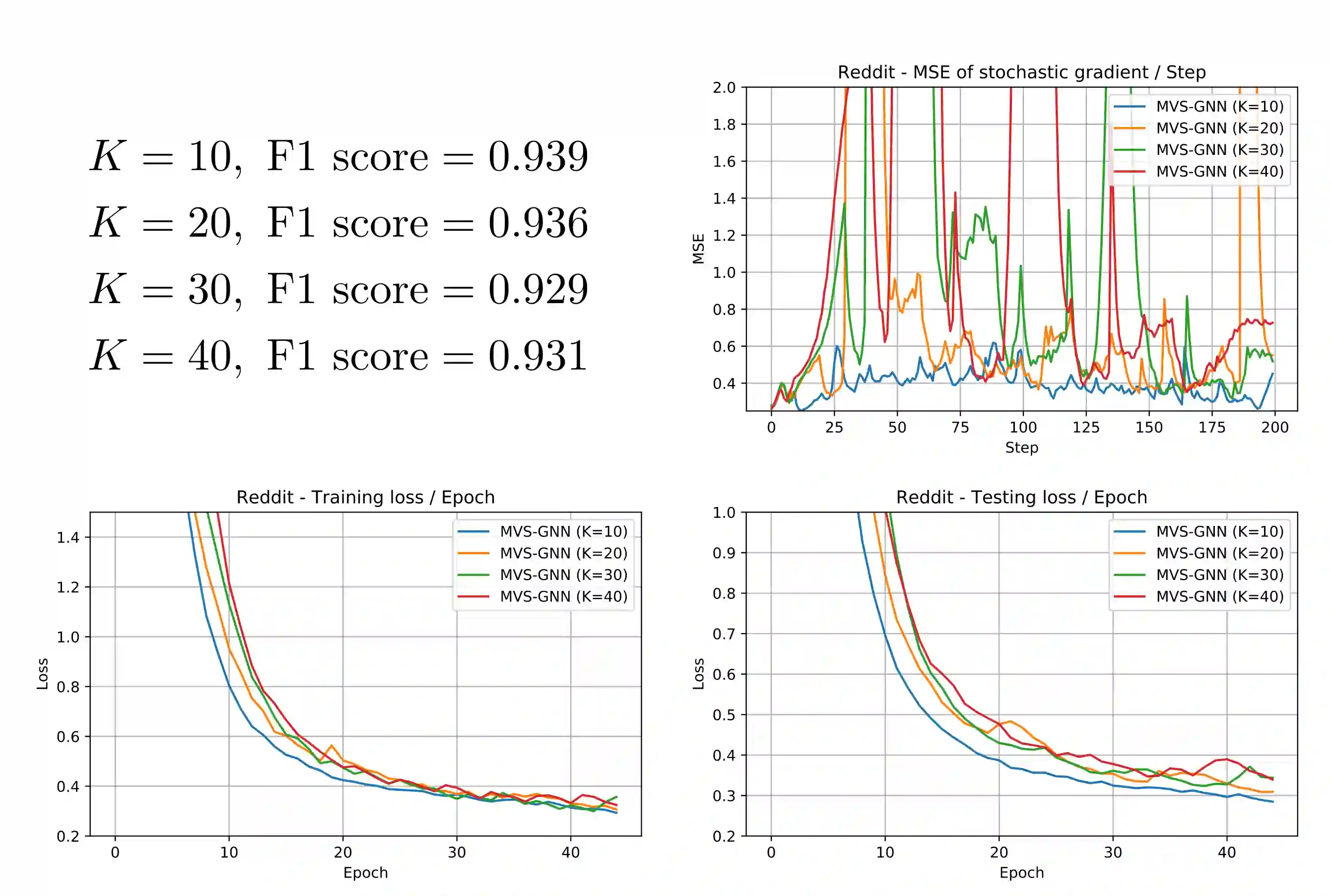
Sampling methods (e.g., node-wise, layer-wise, or subgraph) has become an indispensable strategy to speed up training large-scale Graph Neural Networks (GNNs). However, existing sampling methods are mostly based on the graph structural information and ignore the dynamicity of optimization, which leads to high variance in estimating the stochastic gradients. The high variance issue can be very pronounced in extremely large graphs, where it results in slow convergence and poor generalization. In this paper, we theoretically analyze the variance of sampling methods and show that, due to the composite structure of empirical risk, the variance of any sampling method can be decomposed into \textit{embedding approximation variance} in the forward stage and \textit{stochastic gradient variance} in the backward stage that necessities mitigating both types of variance to obtain faster convergence rate. We propose a decoupled variance reduction strategy that employs (approximate) gradient information to adaptively sample nodes with minimal variance, and explicitly reduces the variance introduced by embedding approximation. We show theoretically and empirically that the proposed method, even with smaller mini-batch sizes, enjoys a faster convergence rate and entails a better generalization compared to the existing methods.
翻译:抽样方法(例如,交点、分层或子集)已成为加速培训大型图形神经网络(GNNS)的不可或缺的战略,但是,现有的抽样方法大多以图表结构信息为基础,忽视了优化的动态性,从而导致在估计随机梯度时出现很大差异。高差异问题在极大图中非常明显,这导致趋同速度缓慢和概括化不力。在本文中,我们从理论上分析抽样方法的差异,并表明,由于经验风险的综合结构,任何抽样方法的差异都可以分解成前阶段的\textit{包含的近似差}和后阶段的\textit{随机梯度差异},这导致在估计分解两种差异以获得更快的趋同率方面差异很大。我们提出了一个分解差异减少战略,将(近似)梯度信息用于适应性采样节点,差异最小,并通过嵌入近似来明确减少差异。我们从理论上和实证上表明,拟议的方法可以在理论上和实证上形成更好的趋同率,即使微缩方法也比了较快的趋同。