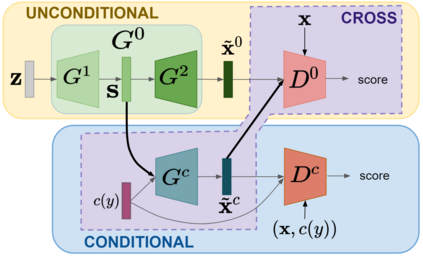
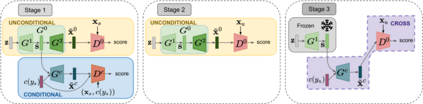
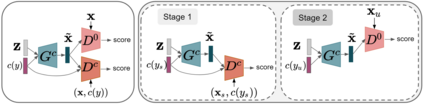
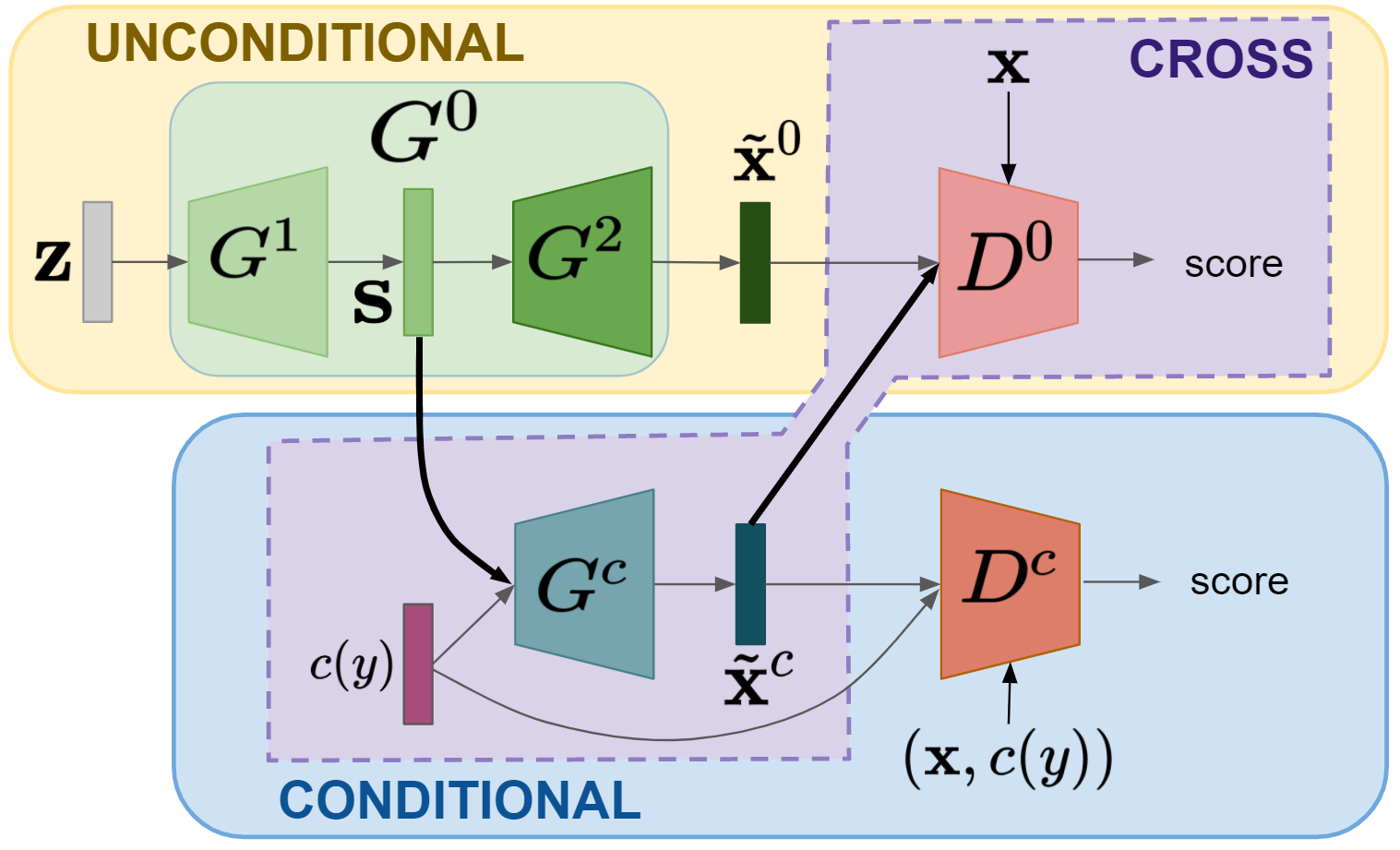
In this paper, we address zero-shot learning (ZSL), the problem of recognizing categories for which no labeled visual data are available during training. We focus on the transductive setting, in which unlabelled visual data from unseen classes is available. State-of-the-art paradigms in ZSL typically exploit generative adversarial networks to synthesize visual features from semantic attributes. We posit that the main limitation of these approaches is to adopt a single model to face two problems: 1) generating realistic visual features, and 2) translating semantic attributes into visual cues. Differently, we propose to decouple such tasks, solving them separately. In particular, we train an unconditional generator to solely capture the complexity of the distribution of visual data and we subsequently pair it with a conditional generator devoted to enrich the prior knowledge of the data distribution with the semantic content of the class embeddings. We present a detailed ablation study to dissect the effect of our proposed decoupling approach, while demonstrating its superiority over the related state-of-the-art.
翻译:在本文中,我们讨论了零光学习(ZSL)问题,即识别在培训期间没有贴标签的视觉数据的类别的问题;我们侧重于感应设置,在这种设置中,可以获得来自隐蔽阶级的未贴标签的视觉数据;ZSL最先进的范例典型地利用基因对抗网络将语义属性的视觉特征合成。我们假设这些方法的主要局限是采用单一模型来面对两个问题:1)产生现实的视觉特征,2)将语义属性转换成视觉提示。不同地说,我们提议分解这些任务,分别解决它们。特别是,我们培训一个无条件的生成器,专门捕捉视觉数据传播的复杂程度,然后将它与一个有条件的生成器配对,专门用来丰富先前数据传播知识与班级嵌入的语义内容。我们提出详细的关系研究,以解析我们拟议脱钩方法的影响,同时展示其优于相关艺术的优越性。