meta learning 17年:MAML SNAIL
maml
1
The process of training a model’s parameters such that a few gradient steps, or even a single gradient step, can pro- duce good results on a new task can be viewed from a fea- ture learning standpoint as building an internal representa- tion that is broadly suitable for many tasks. If the internal representation is suitable to many tasks, simply fine-tuning the parameters slightly (e.g. by primarily modifying the top layer weights in a feedforward model) can produce good results. In effect, our procedure optimizes for models that are easy and fast to fine-tune, allowing the adaptation to happen in the right space for fast learning. From a dynami- cal systems standpoint, our learning process can be viewed as maximizing the sensitivity of the loss functions of new tasks with respect to the parameters: when the sensitivity is high, small local changes to the parameters can lead to
2.2
we propose a method that can learn the parameters of any standard model via meta-learning in such a way as to prepare that model for fast adaptation. The intuition behind this approach is that some internal representations are more transferrable than others. For example, a neural network might learn internal features that are broadly applicable to all tasks in p(T ), rather than a single individual task. How can we en- courage the emergence of such general-purpose representa- tions? We take an explicit approach to this problem: since the model will be fine-tuned using a gradient-based learn- ing rule on a new task, we will aim to learn a model in such a way that this gradient-based learning rule can make rapid progress on new tasks drawn from p(T ), without overfit- ting. In effect, we will aim to find model parameters that are sensitive to changes in the task, such that small changes in the parameters will produce large improvements on the loss function of any task drawn from p(T ), when altered in the direction of the gradient of that loss (see Figure 1). We
https://github.com/tristandeleu/pytorch-maml-rl
https://github.com/cbfinn/maml_rl
-------------------------------
A SIMPLE NEURAL ATTENTIVE META-LEARNER
We propose a class of simple and generic meta-learner architectures that use a novel combination of temporal convolutions and soft attention; the former to aggregate information from past experience and the latter to pinpoint specific pieces of information.
1
Meta-learning can be formalized as a sequence-to-sequence problem; in existing approaches that adopt this view, the bottleneck is in the meta-learner’s ability to internalize and refer to past experience. Thus, we propose a class of model architectures that addresses this shortcoming: we combine temporal convolutions, which enable the meta-learner to aggregate contextual information from past experience, with causal attention, which allow it to pinpoint specific pieces of information within that context.
3
construct SNAIL by combining the two: we use temporal convolutions to produce the context over which we use a causal attention operation. By interleaving TC layers with causal attention layers, SNAIL can have high-bandwidth access over its past experience without constraints on the amount of experience it can effectively use. By using attention at multiple stages within a model that is trained end-to-end, SNAIL can learn what pieces of information to pick out from the experience it gathers, as well as a feature representation that is amenable to doing so easily. As an additional benefit, SNAIL architectures are easier to train than traditional RNNs such as LSTM or GRUs
3.1 MODULAR BUILDING BLOCKS
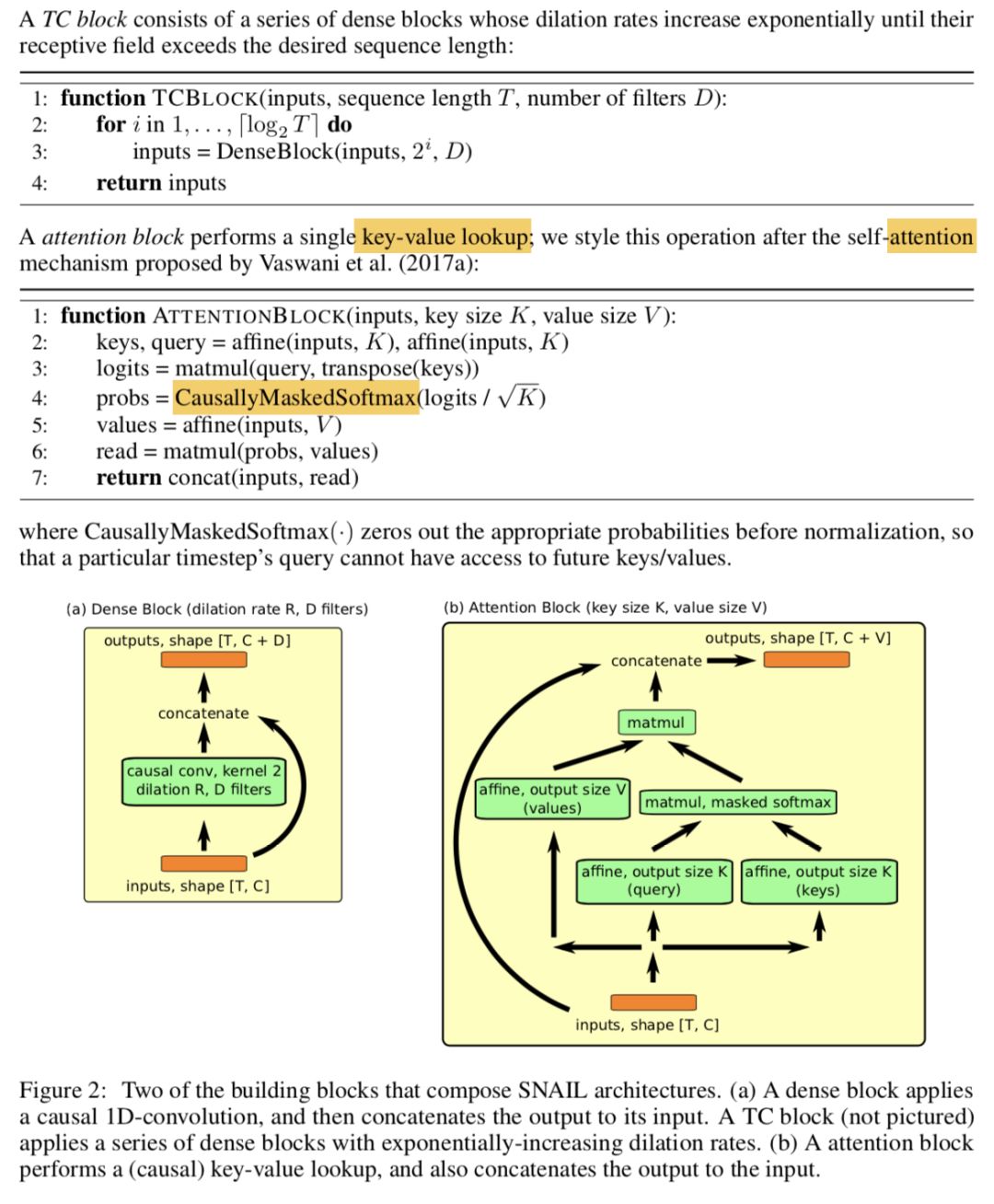
实验领域及效果
5 EXPERIMENTS
Our experiments were designed to investigate the following questions:
• How does SNAIL’s generality affect its performance on a range of meta-learning tasks?
• How does its performance compare to existing approaches that are specialized to a particular
task domain, or have elements of a high-level strategy already built-in?
• HowdoesSNAILscalewithhigh-dimensionalinputsandlong-termtemporaldependencies?
5.1 FEW-SHOT IMAGE CLASSIFICATION
https://github.com/sagelywizard/snail
https://github.com/eambutu/snail-pytorch




