【导读】NeurIPS 是全球最受瞩目的AI、机器学习顶级学术会议之一,每年全球的人工智能爱好者和科学家都会在这里聚集,发布最新研究。NIPS 2019大会已经在12月8日-14日在加拿大温哥华举行。这次专知小编发现零样本学习(Zero-Shot Learning, ZSL)在今年的NeurIPS出现了好多篇,也突出其近期的火热程度, 为此,专知小编整理了NIPS 2019零样本学习(Zero-Shot Learning)相关的论文供大家学习收藏—零样本知识迁移、Transductive ZSL、多注意力定位、ZSL语义分割、对偶对抗语义一致网络。
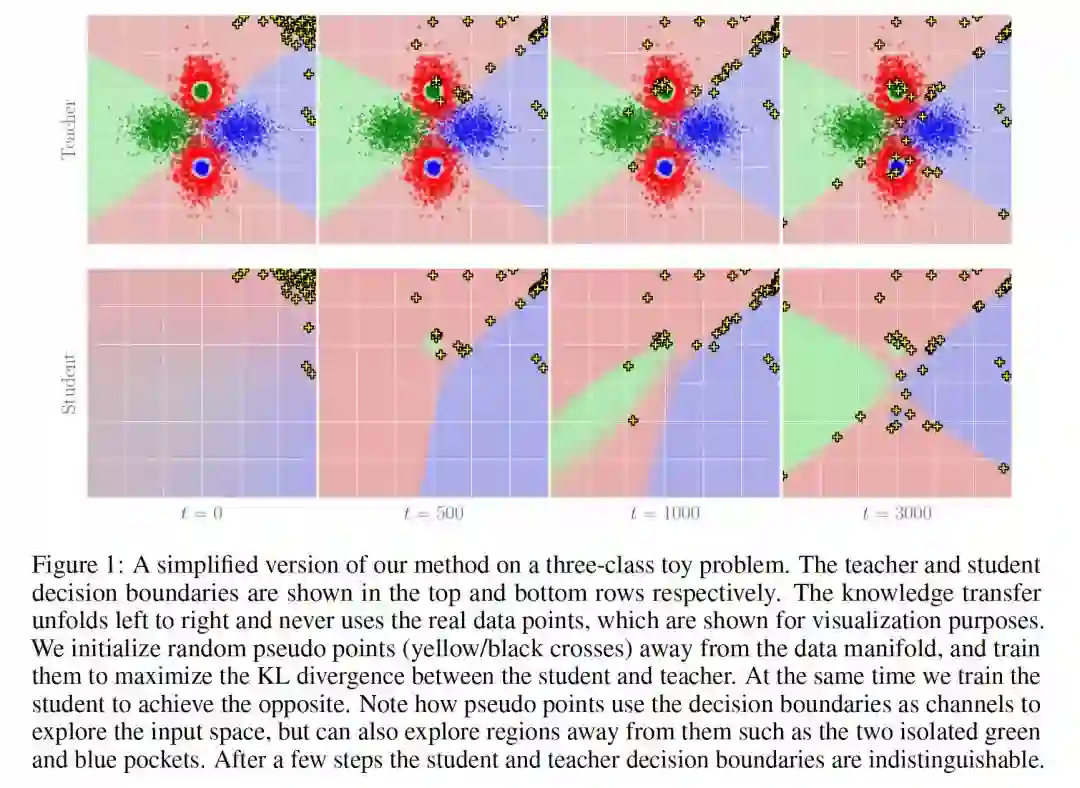
- Zero-shot Knowledge Transfer via Adversarial Belief Matching
作者:Paul Micaelli and Amos Storkey
摘要:在现代深度学习应用中,将知识从一个大的teacher network迁移到一个小的student network中是一个很受欢迎的任务。然而,由于数据集的规模越来越大,隐私法规也越来越严格,越来越多的人无法访问用于训练teacher network的数据。我们提出一种新方法,训练student network在不使用任何数据或元数据的情况下,与teacher network的预测相匹配。我们通过训练一个对抗生成器来搜索student与teacher匹配不佳的图片,然后使用它们来训练student,从而达到这个目的。我们得到的student在SVHN这样的简单数据集上与teacher非常接近,而在CIFAR10上,尽管没有使用数据,我们在few-shot distillation (100 images per class)的技术水平上进行了改进。最后,我们还提出了一种度量标准,来量化teacher与student在决策边界附近的信念匹配程度,并观察到我们的zero-shot student与teacher之间的匹配程度显著高于用真实数据提取的student与teacher之间的匹配程度。我们的代码链接如下:
https://github.com/polo5/ZeroShotKnowledgeTransfer。
网址:
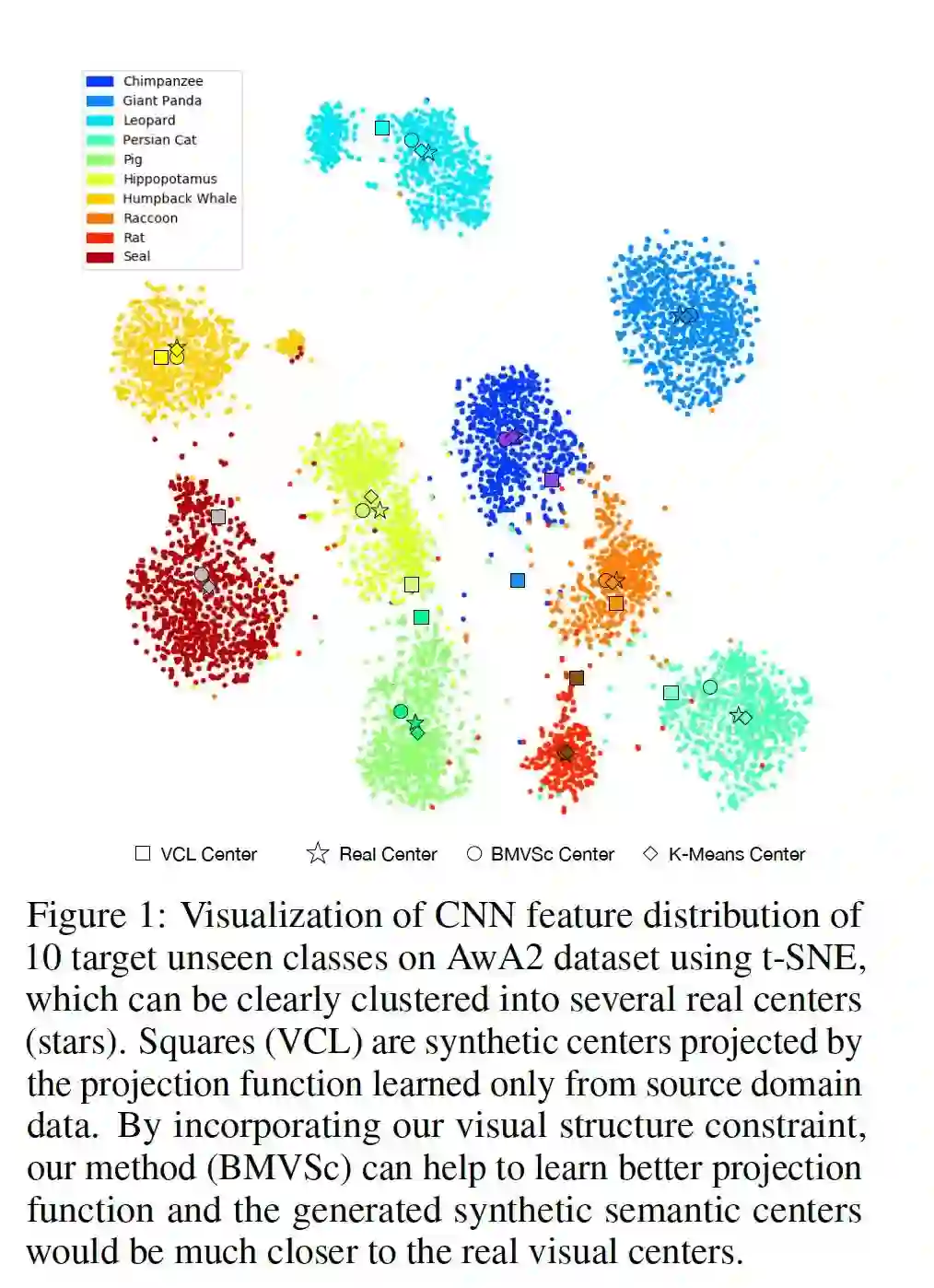
https://papers.nips.cc/paper/9151-zero-shot-knowledge-transfer-via-adversarial-belief-matching 2. Transductive Zero-Shot Learning with Visual Structure Constraint
作者:Ziyu Wan, Dongdong Chen, Yan Li, Xingguang Yan, Junge Zhang, Yizhou Yu and Jing Liao
摘要:为了识别未知类的目标,现有的零样本学习(Zero-Shot Learning, ZSL)方法大多是先根据源可见类的数据,在公共语义空间和视觉空间之间学习一个相容的投影函数,然后直接应用于目标未知类。然而,在实际场景中,源域和目标域之间的数据分布可能不匹配,从而导致众所周知的domain shift问题。基于观察到的测试实例的视觉特征可以被分割成不同的簇,我们针对转导ZSL的类中心提出了一种新的视觉结构约束,以提高投影函数的通用性(即缓解上述域移位问题)。具体来说,采用了三种不同的策略 (symmetric Chamfer-distance, Bipartite matching distance, 和Wasserstein distance) 来对齐测试实例的投影不可见的语义中心和可视集群中心。我们还提出了一种新的训练策略,以处理测试数据集中存在大量不相关图像的实际情况,这在以前的方法中是没有考虑到的。在许多广泛使用的数据集上进行的实验表明,我们所提出的视觉结构约束能够持续地带来可观的性能增益,并取得最先进的结果。我们源代码在:https://github.com/raywzy/VSC。
网址:
https://papers.nips.cc/paper/9188-transductive-zero-shot-learning-with-visual-structure-constraint
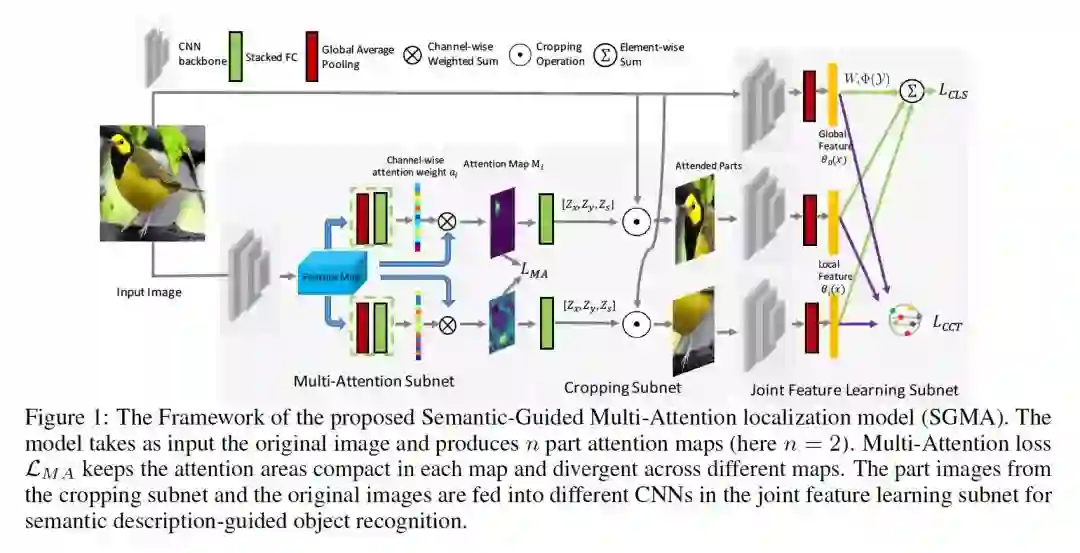
- Semantic-Guided Multi-Attention Localization for Zero-Shot Learning
作者:Yizhe Zhu, Jianwen Xie, Zhiqiang Tang, Xi Peng and Ahmed Elgammal
摘要:零样本学习(Zero-shot learning)通过引入类的语义表示,将传统的目标分类扩展到不可见的类识别。现有的方法主要侧重于学习视觉语义嵌入的映射函数,而忽视了学习discriminative视觉特征的效果。本文研究了discriminative region localization的意义。提出了一种基于语义引导的多注意力定位模型,该模型能自动发现目标中最discriminative的部分,实现零样本学习,不需要人工标注。我们的模型从整个目标和被检测部分共同学习协作的全局和局部特征,根据语义描述对对象进行分类。此外,在嵌入softmax loss和class-center triplet loss的联合监督下,鼓励模型学习具有高类间离散性和类内紧凑性的特征。通过对三种广泛使用的零样本学习基准的综合实验,我们证明了multi-attention localization的有效性,我们提出的方法在很大程度上改进了最先进的结果。
网址:
- Zero-shot Learning via Simultaneous Generating and Learning
作者:Hyeonwoo Yu and Beomhee Lee
摘要:为了克服不可见类训练数据的不足,传统的零样本学习方法主要在可见数据点上训练模型,并利用可见类和不可见类的语义描述。在探索类与类之间关系的基础上,我们提出了一个深度生成模型,为模型提供了可见类与不可见类的经验。该方法基于类特定多模态先验的变分自编码器,学习可见类和不可见类的条件分布。为了避免使用不可见类的示例,我们将不存在的数据视为缺失的示例。也就是说,我们的网络目标是通过迭代地遵循生成和学习策略来寻找最优的不可见数据点和模型参数。由于我们得到了可见类和不可见类的条件生成模型,因此无需任何现成的分类器就可以直接进行分类和生成。在实验结果中,我们证明了所提出的生成和学习策略使模型取得了优于仅在可见类上训练的结果,也优于几种最先进的方法。
网址:
https://papers.nips.cc/paper/8300-zero-shot-learning-via-simultaneous-generating-and-learning
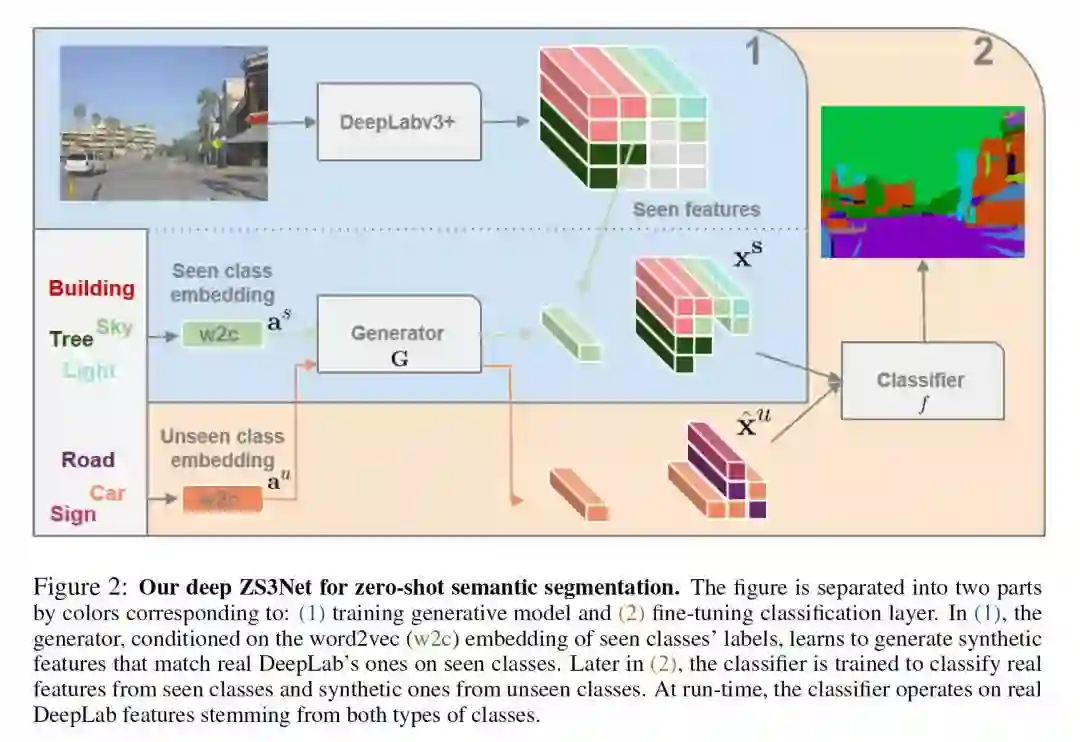
- Zero-Shot Semantic Segmentation
作者:Maxime Bucher, Tuan-Hung VU, Matthieu Cord and Patrick Pérez
摘要:语义分割模型在扩展到大量对象类别的能力上受到限制。在本文中,我们介绍了零样本语义分割的新任务:用零训练实例学习从未见过的对象类别的像素级分类器。为此,我们提出了一个新的架构,ZS3Net,结合了一个深度的视觉分割模型和一种从语义词嵌入生成视觉表示的方法。通过这种方式,ZS3Net解决了在测试时可见和不可见的类别都面临的像素分类任务(所谓的“generalized” zero-shot 分类)。通过依赖于不可见类的像素的自动伪标记的自训练步骤,可以进一步提高性能。在两个标准的细分数据集,Pascal-VOC和Pascal-Context,我们提出了zero-shot基准和设置竞争的baseline。对于Pascal-Context数据集中的复杂场景,我们通过使用图形-上下文编码来扩展我们的方法,以充分利用来自类分割图的空间上下文先验。
网址:
https://papers.nips.cc/paper/8338-zero-shot-semantic-segmentation
- Dual Adversarial Semantics-Consistent Network for Generalized Zero-Shot Learning
作者:Jian Ni, Shanghang Zhang and Haiyong Xie
摘要:广义零样本学习(Generalized zero-shot learning,GZSL)是一类具有挑战性的视觉和知识迁移问题,在测试过程中,既有看得见的类,也有看不见的类。现有的GZSL方法要么在嵌入阶段遭遇语义丢失,抛弃有区别的信息,要么不能保证视觉语义交互。为了解决这些局限性,我们提出了一个Dual Adversarial Semantics-Consistent Network (简称DASCN),它在一个统一的GZSL框架中学习原始的和对偶的生成的对抗网络(GANs)。在DASCN中,原始的GAN学习综合类间的区别和语义——从可见/不可见类的语义表示和对偶GAN重构的语义表示中保留视觉特征。对偶GAN通过语义一致的对抗性学习,使合成的视觉特征能够很好地表示先验语义知识。据我们所知,这是针对GZSL采用新颖的Dual-GAN机制的第一个工作。大量的实验表明,我们的方法比最先进的方法取得了显著的改进。
网址: