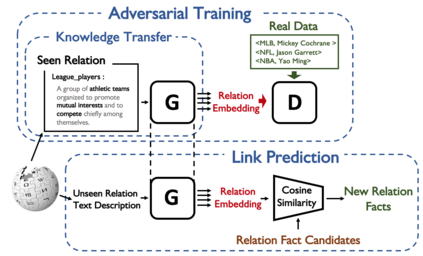
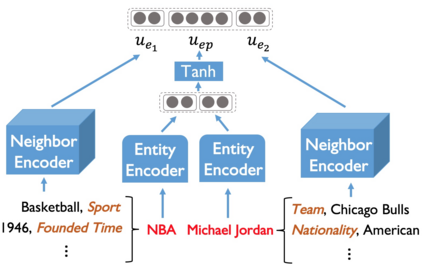
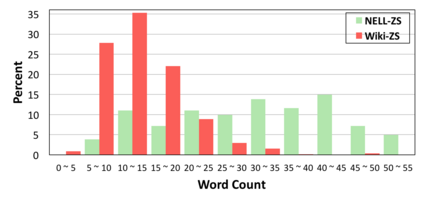
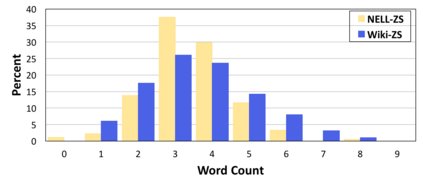
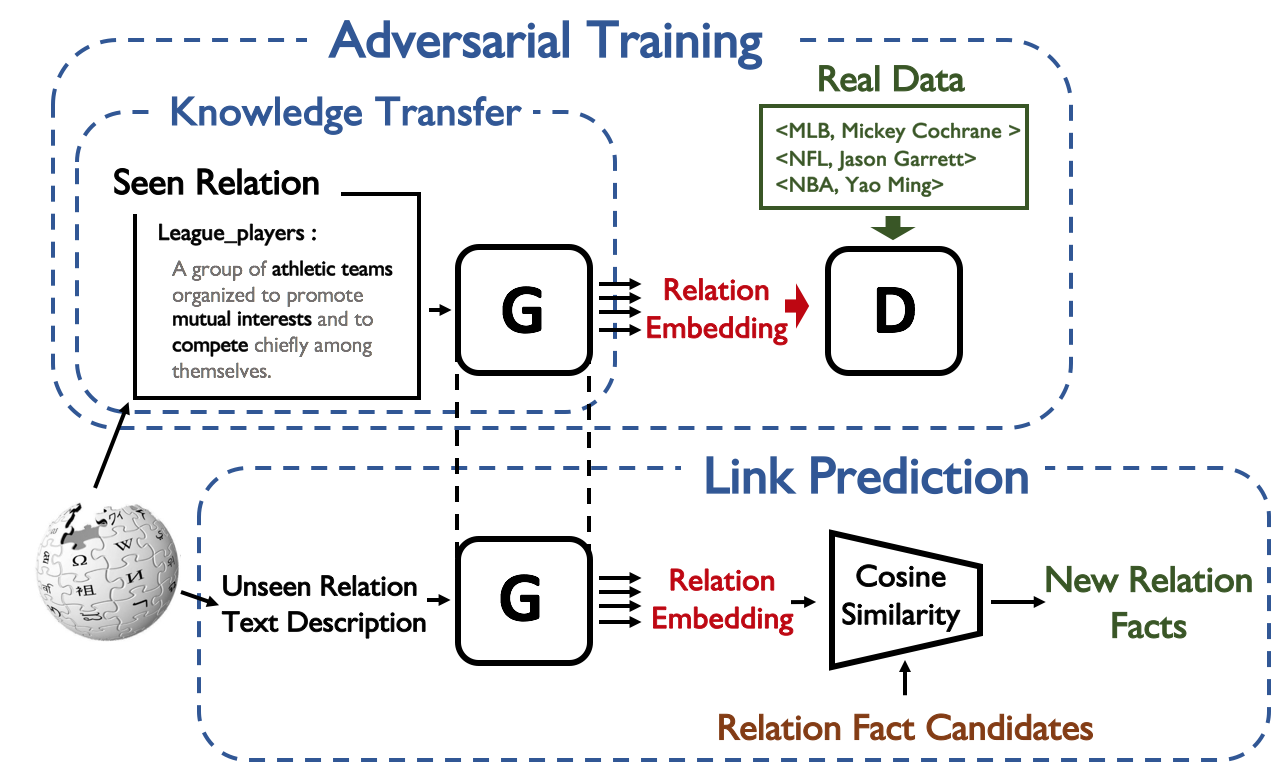
Large-scale knowledge graphs (KGs) are shown to become more important in current information systems. To expand the coverage of KGs, previous studies on knowledge graph completion need to collect adequate training instances for newly-added relations. In this paper, we consider a novel formulation, zero-shot learning, to free this cumbersome curation. For newly-added relations, we attempt to learn their semantic features from their text descriptions and hence recognize the facts of unseen relations with no examples being seen. For this purpose, we leverage Generative Adversarial Networks (GANs) to establish the connection between text and knowledge graph domain: The generator learns to generate the reasonable relation embeddings merely with noisy text descriptions. Under this setting, zero-shot learning is naturally converted to a traditional supervised classification task. Empirically, our method is model-agnostic that could be potentially applied to any version of KG embeddings, and consistently yields performance improvements on NELL and Wiki dataset.
翻译:大型知识图表(KGs)在当前信息系统中显得更加重要。为了扩大KGs的覆盖范围,以往关于知识图表完成情况的研究需要收集对新增加关系的适当培训实例。在本文中,我们考虑一种新颖的提法,即零点学习,以解脱这种繁琐的整理。对于新增加的关系,我们试图从它们的文字描述中学习它们的语义特征,从而承认不可见关系的事实,而没有看到任何实例。为此,我们利用Genemental 反versarial网络(GANs)在文本和知识图表域间建立联系:生成者学会仅仅用噪音的文字描述来生成合理的关系嵌入。在此背景下,零点学习自然转化为传统监管的分类任务。有规律地说,我们的方法是模型-认知性,有可能适用于任何版本的KG嵌入,并持续提高NELL和Wiki数据集的性能。