
主题: Heterogeneous Graph-based Knowledge Transfer for Generalized Zero-shot Learning
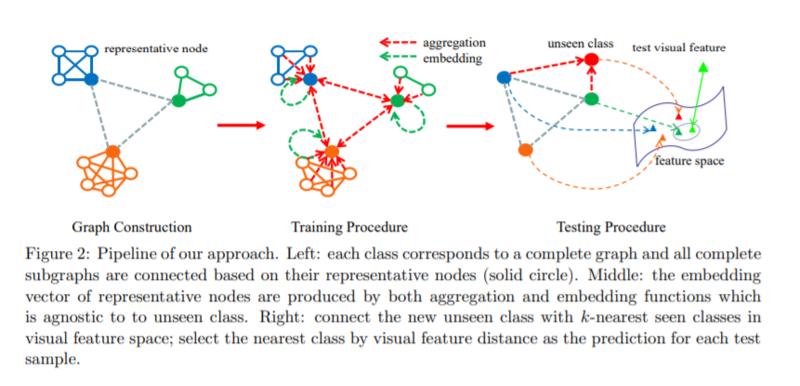
摘要: 广义零样本学习(GZSL)解决了同时涉及可见类和不可见类的实例分类问题。关键问题是如何有效地将从可见类学习到的模型转换为不可见类。GZSL中现有的工作通常假设关于未公开类的一些先验信息是可用的。然而,当新的不可见类动态出现时,这种假设是不现实的。为此,我们提出了一种新的基于异构图的知识转移方法(HGKT),该方法利用图神经网络对GZSL、不可知类和不可见实例进行知识转移。具体地说,一个结构化的异构图,它是由所见类的高级代表节点构造而成,这些代表节点通过huasstein-barycenter来选择,以便同时捕获类间和类内的关系,聚集和嵌入函数可以通过图神经网络来学习,它可以用来计算不可见类的嵌入,方法是从它们的内部迁移知识。在公共基准数据集上的大量实验表明,我们的方法达到了最新的结果。
成为VIP会员查看完整内容
相关内容

专知会员服务
29+阅读 · 2020年4月17日
专知会员服务
78+阅读 · 2020年3月1日
专知会员服务
64+阅读 · 2020年1月11日
专知会员服务
12+阅读 · 2020年1月7日
专知会员服务
102+阅读 · 2019年11月24日
Arxiv
10+阅读 · 2020年3月12日
Arxiv
11+阅读 · 2018年5月9日
Arxiv
4+阅读 · 2017年10月26日

相关VIP内容
专知会员服务
29+阅读 · 2020年4月17日
专知会员服务
78+阅读 · 2020年3月1日
专知会员服务
64+阅读 · 2020年1月11日
专知会员服务
12+阅读 · 2020年1月7日
专知会员服务
102+阅读 · 2019年11月24日
相关资讯
相关论文
Arxiv
10+阅读 · 2020年3月12日
Arxiv
11+阅读 · 2018年5月9日
Arxiv
4+阅读 · 2017年10月26日