Hierarchical Disentangled Representations
https://arxiv.org/abs/1804.02086
Abstract
Deep latent-variable models learn representa-
tions of high-dimensional data in an unsuper-
vised manner. A number of recent efforts have
focused on learning representations that disen-
tangle statistically independent axes of varia-
tion, often by introducing suitable modifica-
tions of the objective function. We synthesize
this growing body of literature by formulating
a generalization of the evidence lower bound
that explicitly represents the trade-offs between
sparsity of the latent code, bijectivity of repre-
sentations, and coverage of the support of the
empirical data distribution. Our objective is
also suitable to learning hierarchical representa-
tions that disentangle blocks of variables whilst
allowing for some degree of correlations within
blocks. Experiments on a range of datasets
demonstrate that learned representations con-
tain interpretable features, are able to learn dis-
crete attributes, and generalize to unseen com-
binations of factors.
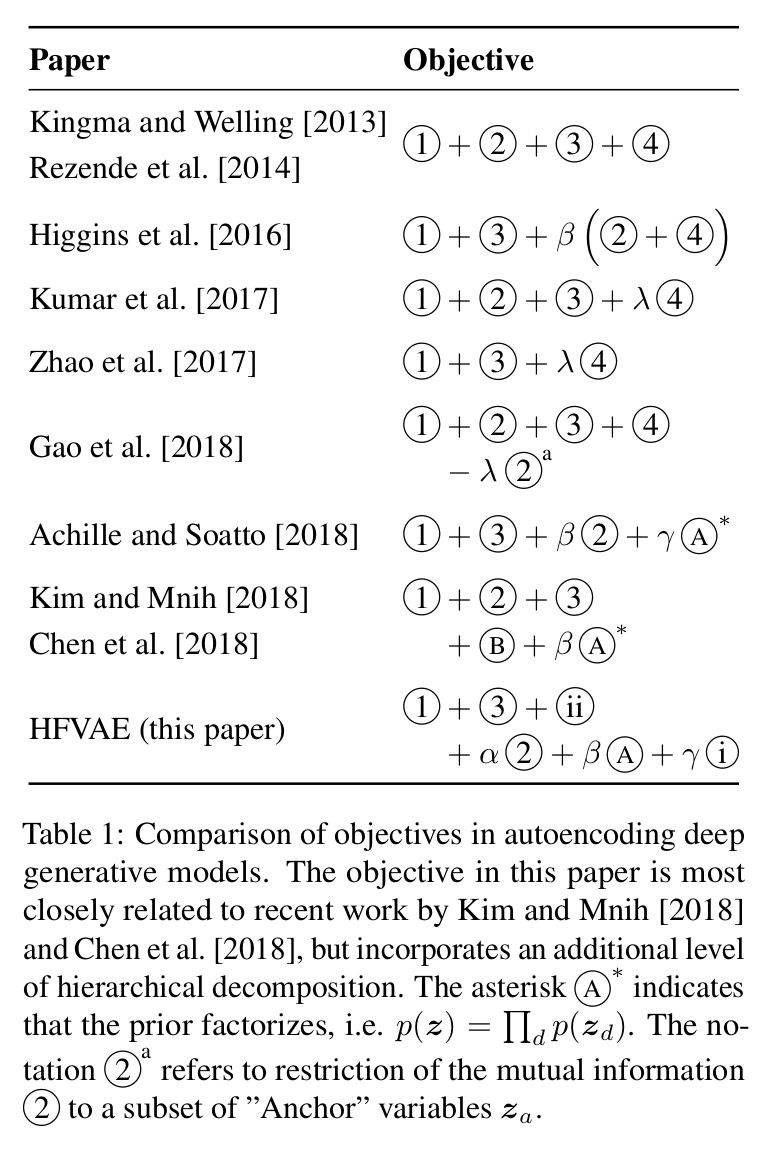
各种vae的比较!