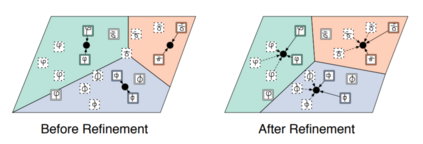
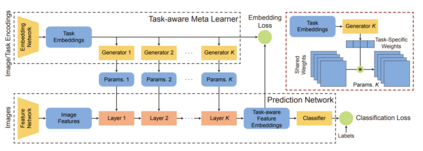
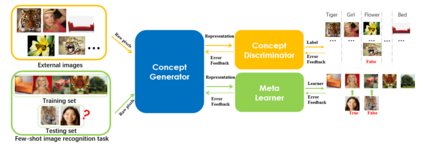
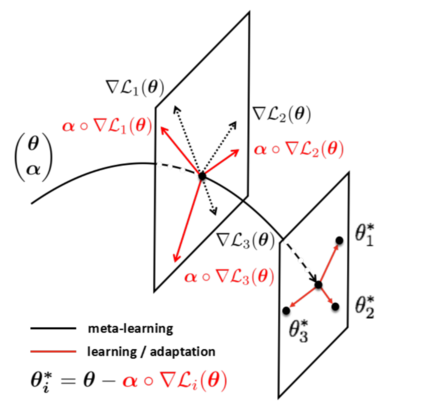
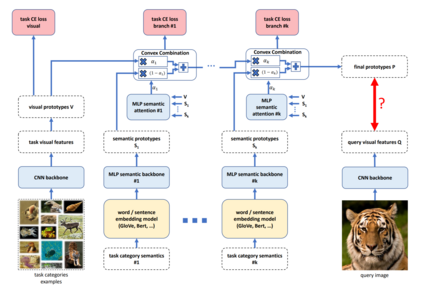
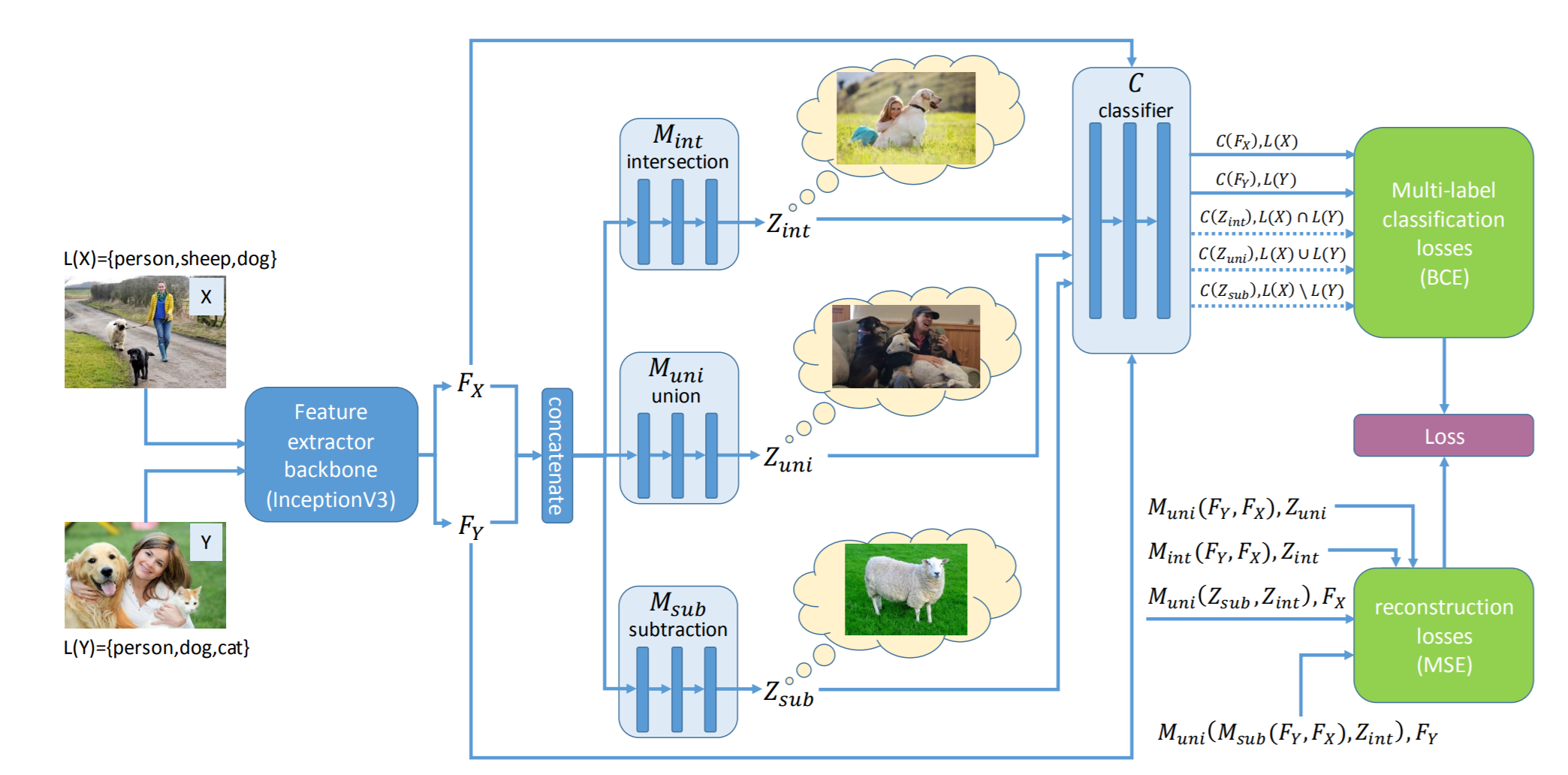
Deep neural networks have been able to outperform humans in some cases like image recognition and image classification. However, with the emergence of various novel categories, the ability to continuously widen the learning capability of such networks from limited samples, still remains a challenge. Techniques like Meta-Learning and/or few-shot learning showed promising results, where they can learn or generalize to a novel category/task based on prior knowledge. In this paper, we perform a study of the existing few-shot meta-learning techniques in the computer vision domain based on their method and evaluation metrics. We provide a taxonomy for the techniques and categorize them as data-augmentation, embedding, optimization and semantics based learning for few-shot, one-shot and zero-shot settings. We then describe the seminal work done in each category and discuss their approach towards solving the predicament of learning from few samples. Lastly we provide a comparison of these techniques on the commonly used benchmark datasets: Omniglot, and MiniImagenet, along with a discussion towards the future direction of improving the performance of these techniques towards the final goal of outperforming humans.
翻译:深神经网络在某些情况中,例如图像识别和图像分类,已经能够超越人类。然而,随着各种新型类别的出现,不断从有限的样本中扩大这类网络的学习能力的能力仍是一个挑战。Meta-Learning和/或少发数发学习等技术显示了有希望的结果,它们可以在先前的知识基础上学习或概括到一个新的类别/任务。在本文件中,我们根据它们的方法和评价指标,对计算机视觉领域现有的微小的元学习技术进行了一项研究。我们为这些技术提供了分类,并将它们分类为数据增强、嵌入、优化和语义学,这些技术以少发、一发和零发环境为基础。然后我们描述每个类别完成的半成品工作,并讨论它们如何解决从少数样本中学习的困境。最后,我们将这些技术与通常使用的基准数据集:Omniglot和MiniImagenet进行比较,同时讨论今后如何改进这些技术的性能,以最终达到表现人类的目标。