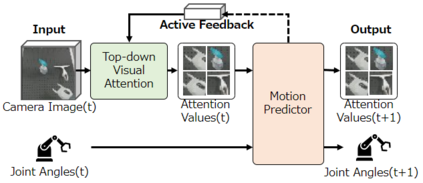
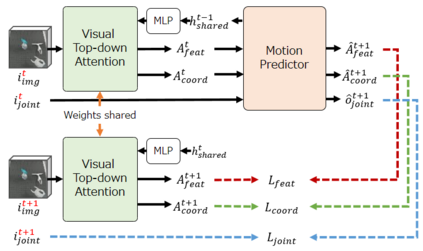
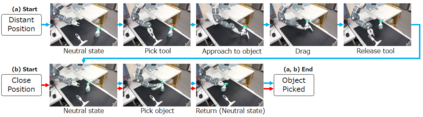
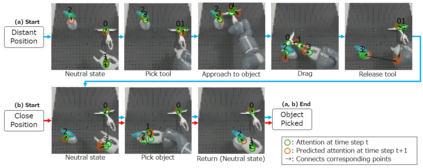
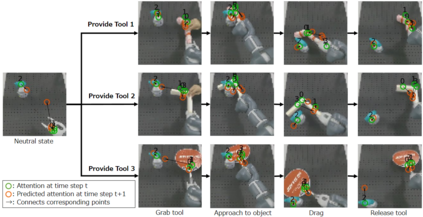
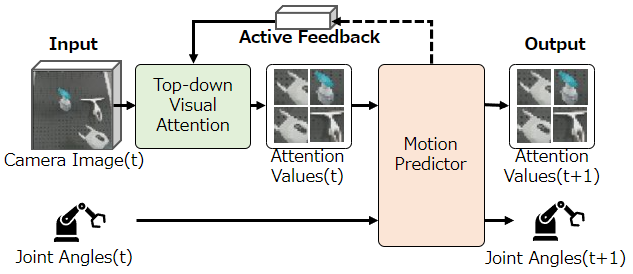
Sufficiently perceiving the environment is a critical factor in robot motion generation. Although the introduction of deep visual processing models have contributed in extending this ability, existing methods lack in the ability to actively modify what to perceive; humans perform internally during visual cognitive processes. This paper addresses the issue by proposing a novel robot motion generation model, inspired by a human cognitive structure. The model incorporates a state-driven active top-down visual attention module, which acquires attentions that can actively change targets based on task states. We term such attentions as role-based attentions, since the acquired attention directed to targets that shared a coherent role throughout the motion. The model was trained on a robot tool-use task, in which the role-based attentions perceived the robot grippers and tool as identical end-effectors, during object picking and object dragging motions respectively. This is analogous to a biological phenomenon called tool-body assimilation, in which one regards a handled tool as an extension of one's body. The results suggested an improvement of flexibility in model's visual perception, which sustained stable attention and motion even if it was provided with untrained tools or exposed to experimenter's distractions.
翻译:虽然引入深视处理模型有助于扩展这种能力,但现有方法缺乏积极修改感知的能力;人类在视觉认知过程中的内部表现。本文件通过在人类认知结构的启发下提出新的机器人动作生成模型来解决这个问题。模型包含一个由国家驱动的积极自上而下视觉关注模块,该模块获得关注,能够根据任务状态积极改变目标。我们将这些关注点称为基于作用的关注点,因为所获得关注点指向的是在整个运动中具有一致作用的目标。该模型在机器人工具使用任务上受到培训,其中角色关注点将机器人抓抓器和工具分别视为相同的终端效应器,在物体采集和物体拖动动作时也是如此。这类似于一种生物现象,即工具-身体同化,其中一种是将处理工具作为人体延伸的延伸。结果表明模型视觉认知的灵活性有所改进,即使提供了未经训练的工具或暴露了实验者的分心,也保持了稳定的注意力和运动。