
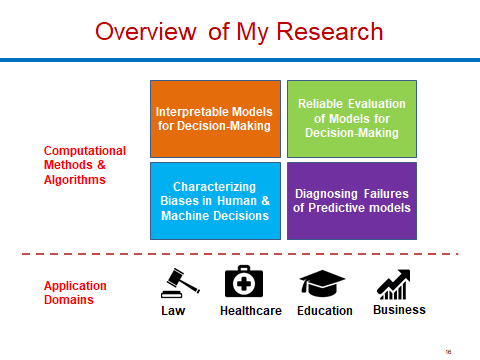
机器学习可解释性,Interpretability and Explainability in Machine Learning
- Overview As machine learning models are increasingly being employed to aid decision makers in high-stakes settings such as healthcare and criminal justice, it is important to ensure that the decision makers (end users) correctly understand and consequently trust the functionality of these models. This graduate level course aims to familiarize students with the recent advances in the emerging field of interpretable and explainable ML. In this course, we will review seminal position papers of the field, understand the notion of model interpretability and explainability, discuss in detail different classes of interpretable models (e.g., prototype based approaches, sparse linear models, rule based techniques, generalized additive models), post-hoc explanations (black-box explanations including counterfactual explanations and saliency maps), and explore the connections between interpretability and causality, debugging, and fairness. The course will also emphasize on various applications which can immensely benefit from model interpretability including criminal justice and healthcare.

相关VIP内容
相关资讯
相关论文