Single-Shot Object Detection with Enriched Semantics
CVPR 2018 论文 论文链接 https://arxiv.org/abs/1712.00433
1.摘要
作者提出了名为Detection with Enriched Semantics(DES)的网络,在SSD网络的基础上,增加了语义分割分支(semantic segmentation branch)和全局激活模块(global activation module)。语义分割分使用bounding box级别的ground-truth来监督学习,不需要额外的标注数据。全局激活模块负责学习通道间的关系,学习每个通道的权重。
2.概述
回顾一下SSD的网络结构:
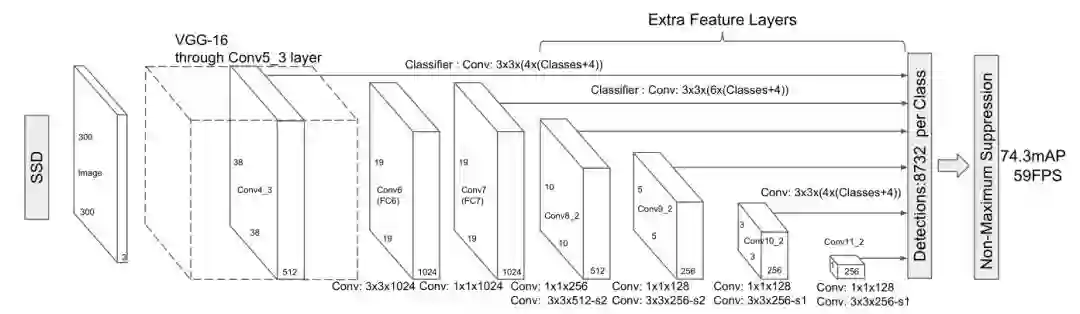
骨干网络使用VGG16,然后使用不用尺寸的feature map预测不同尺度的目标,浅层(从Conv4_3开始)负责预测小目标,深层(到Conv11_2)负责预测大目标。然而浅层网络拥有较少的语义信息,可能导致小目标检测效果不好。
3.方法介绍
为了解决上述问题,作者在SSD的基础上增加了语义分割分支和全局激活模块。整体结构如图:
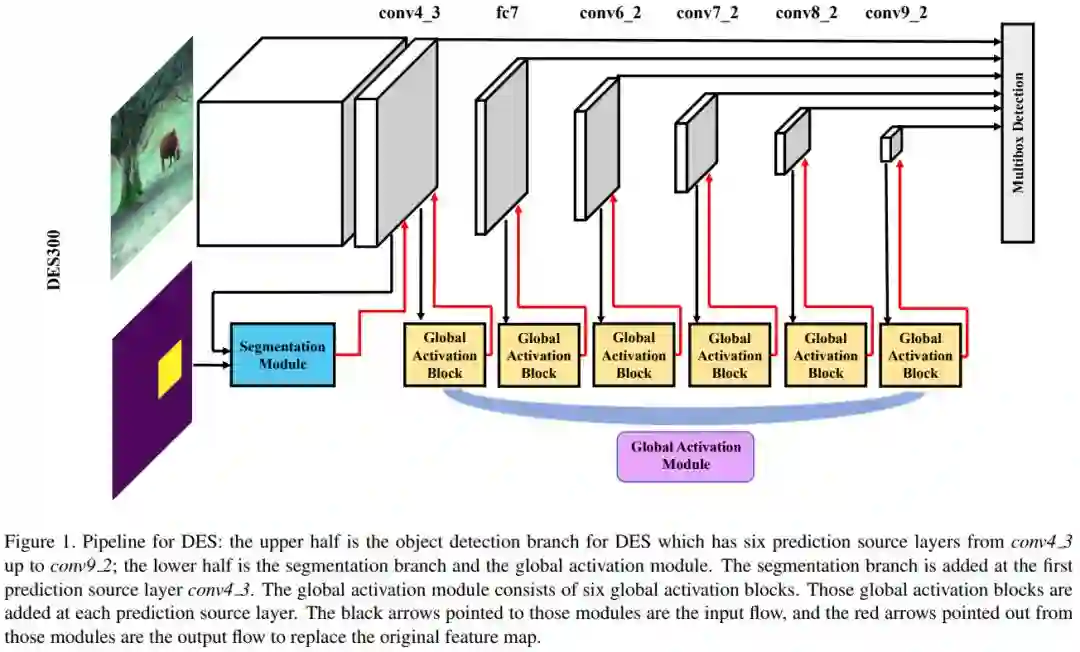
3.1 语义分割模块
语义分割模块添加在第一个预测层(Conv4_3),其结构如图:
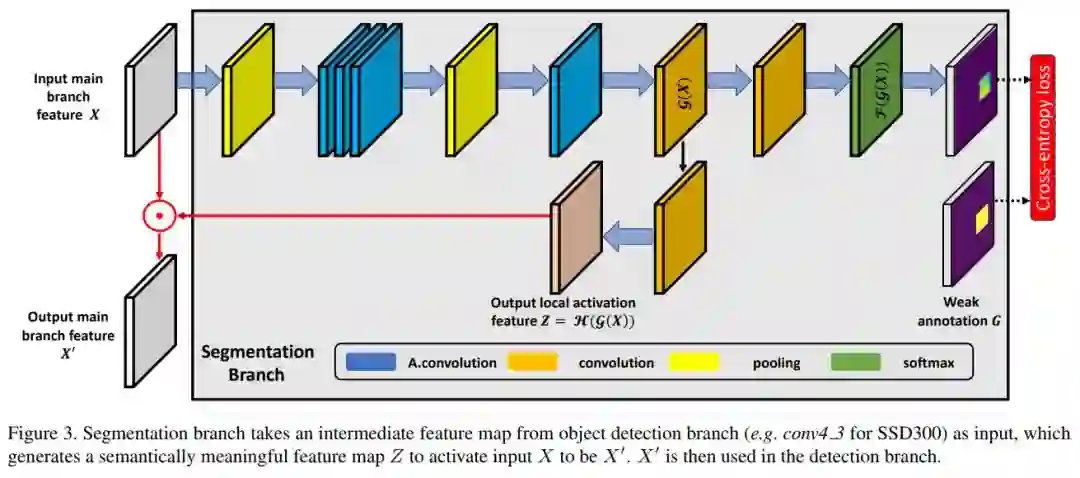
模块的输入为Conv4_3层的feature map,记为X∈R^(C×H×W),分割的ground-truth记为G∈{0,1,2…,N}^(H×W),其中N是类别数量。 图中黄色表示pooling层,kernel大小为3x3,步长为1,padding为1,因此输入输出大小相同。 蓝色的为空洞卷积层,使用3x3的kernel,前三个dilation rate为2,最后一个dilation rate为4。 通过1x1卷积,得到g(X)。接下来有两个分支,如图右侧的表示使用1x1的卷积,然后经过softmax层,预测的实例分割结果,表示为:
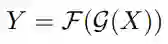
其中,Y∈R^((N+1)×H×W),满足:
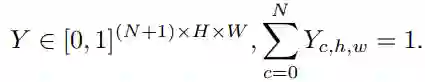
g(X)另一个分支用于生成带有语义信息的feature map,如图下半部分,使用1x1的卷积得到:
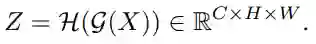
Z的尺寸和通道数与输入X相同,通过按元素相乘,得到语义信息丰富的X':
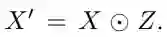
相乘可以理解为对像素进行激活。接下来用输出的X'替换原来的X,用于后续预测。
下图对语义分割的结果进行可视化:
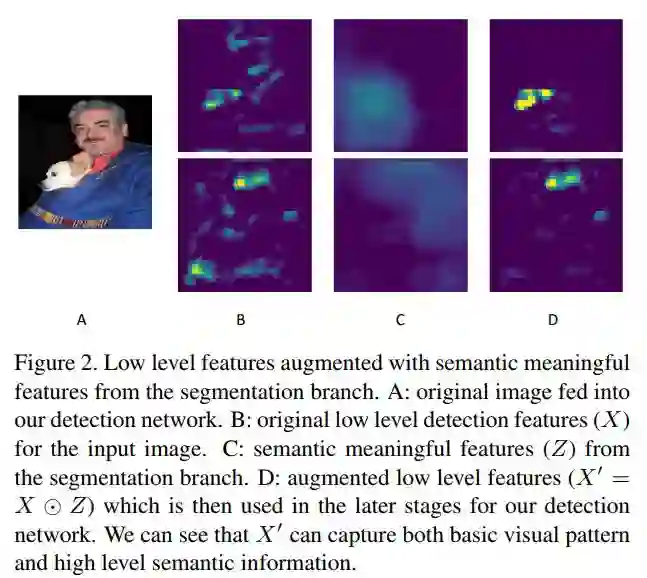
A表示原图;B表示输入feature map X,可以看出只是一些低层信息;C表示含有语义信息的feature map Z;D表示激活后的feature map X',包含基本的视觉信息和高层的语义信息。
如何生成ground-truth:当像素Ghw在一个bounding box内时,Ghw的标签与bbox相同;当Ghw的位置有超过一个bbox时,Ghw的标签与面积最小的bbox相同;其他的像素认为是背景。下图是一个简单的例子:

3.2 全局激活模块
作者在每一个预测层,都添加了一个全局激活模块,来学习通道与目标类别的关系。该方法在SENet中提出,流程如下图:
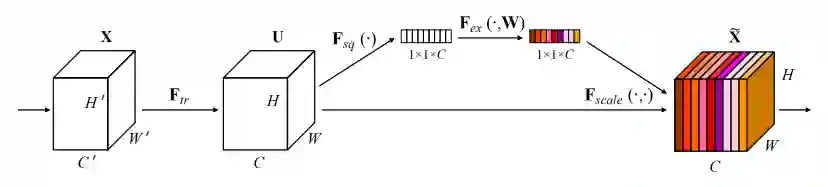
先对输入feature map X∈R^(C×H×W) 进行全局平均池化,得到Z∈R^C:
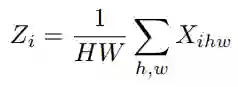
然后通过2个全连接层学习通道权重S:
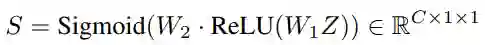
其中W2∈R^(C×C′),W1∈R^(C′×C) 。接下来S与对应通道中所有元素相乘得到X′∈R^(C×H×W),最后用输出X'代替检测分支中的X,作者设置C′=1/4 C。
3.3 多任务训练
分割部分使用交叉熵损失函数:
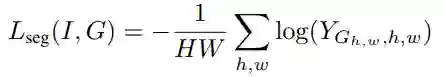
其中Y∈[0,1]^((N+1)×H×W) 是预测的分割结果,G∈{0,1,2,…,N}^(H×W) 是分割的ground-truth,N是目标类别个数。 整体的损失为:
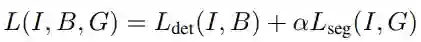
其中α为平衡因子。
4.实验
在VOC2007上的实验结果
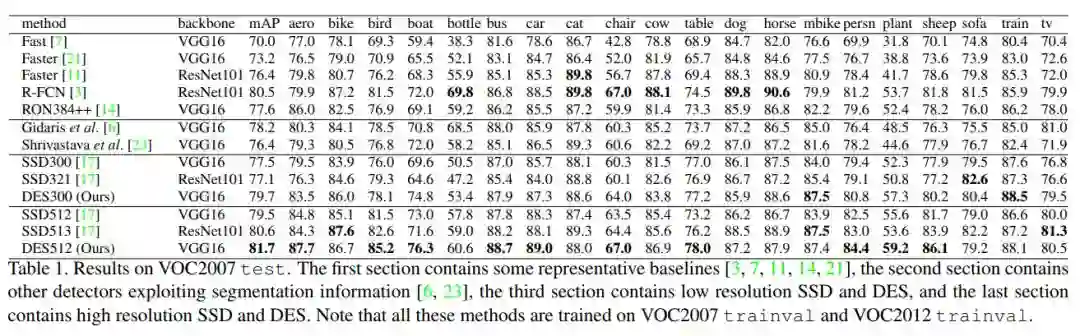
可以看出效果比使用ResNet101的SSD还要好。
在VOC2012上的实验结果
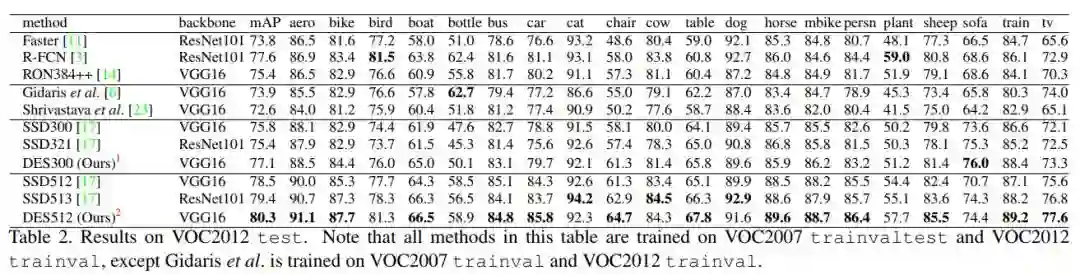
DES与SSD效果对比
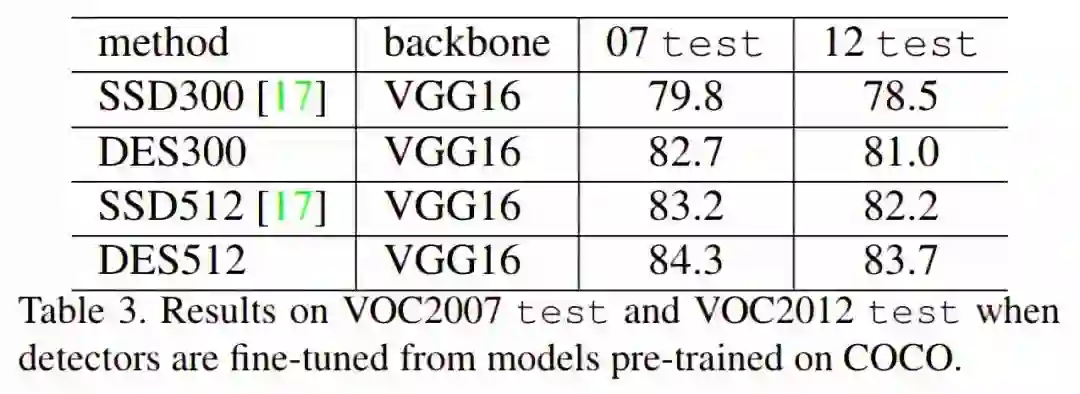
在COCO上的实验结果
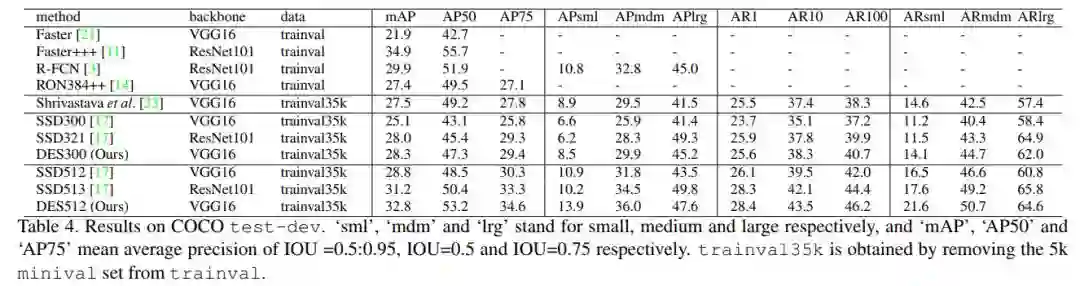
可以看出DES针对小目标检测进行的改进是有效果的。
方法有效性验证
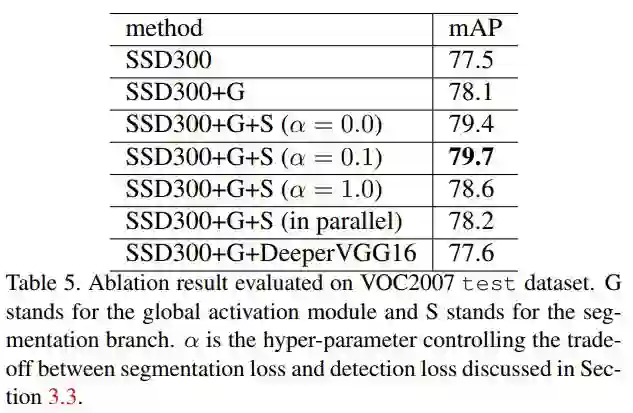
实验取α=0表示无监督的进行训练,作者发现α=0.1效果较好。说明对分割任务有监督训练效果要好,同时分割损失不能太大,因为最终任务是目标检测,而不是分割。 为验证分割模块中特征激活的有效性,作者模仿Mask R-CNN,同时输出目标检测和实例分割的结果,取消了特征激活的步骤。实验发现效果没有明显提升,因为分割的ground-truth不包含额外的信息。但是对检测任务来说,特征激活操作是有效果的。
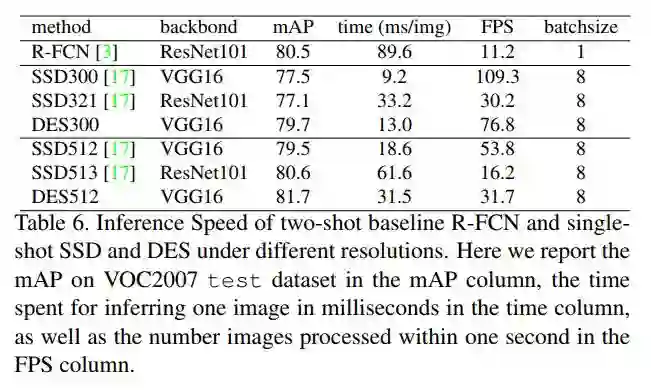
推理速度
检测结果展示

参考资料
[1] https://arxiv.org/abs/1512.02325
[2] https://arxiv.org/abs/1709.01507




