论文笔记之Feature Selective Networks for Object Detection
本文发表于CVPR2018
论文链接:
https://arxiv.org/abs/1711.08879
目前基于神经网络的检测算法大致可以归类于两类框架:
一阶段目标检测框架
两阶段目标检测框架
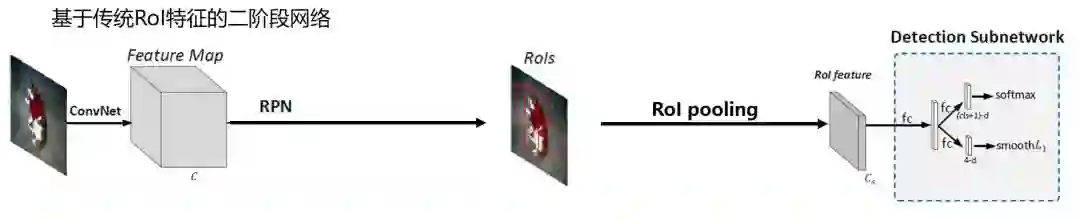
基本上大多数的state-of-the-art目标检测器都采用二阶段目标检测框架,二阶段的检测框架为:将输入图像输入卷积神经网络提取整张图像的特征,然后通过RPN网络得到候选区域(即RoI边界框),通过RoI pooling得到候选区域固定长度的特征,然后输入检测子网络中得到检测结果。因此目标的检测依赖于对RoI特征,因此除了寄希望于基网络,也就是深度卷积神经网络,能够取得更鲁邦和更具判别性的特征以外,研究者也在研究如何生成更强有力及更具信息的RoI特征来增加检测的精度。但是之前的研究都基于原始RoIpooling层。原始的RoI pooling过程如下:

但是,在目标检测中,物体位于不同的区域或者具有不同表观比时,其特征是不同的,提取的RoI特征应强调平移变化特征,显然,RoI pooling在此方面做的不足。
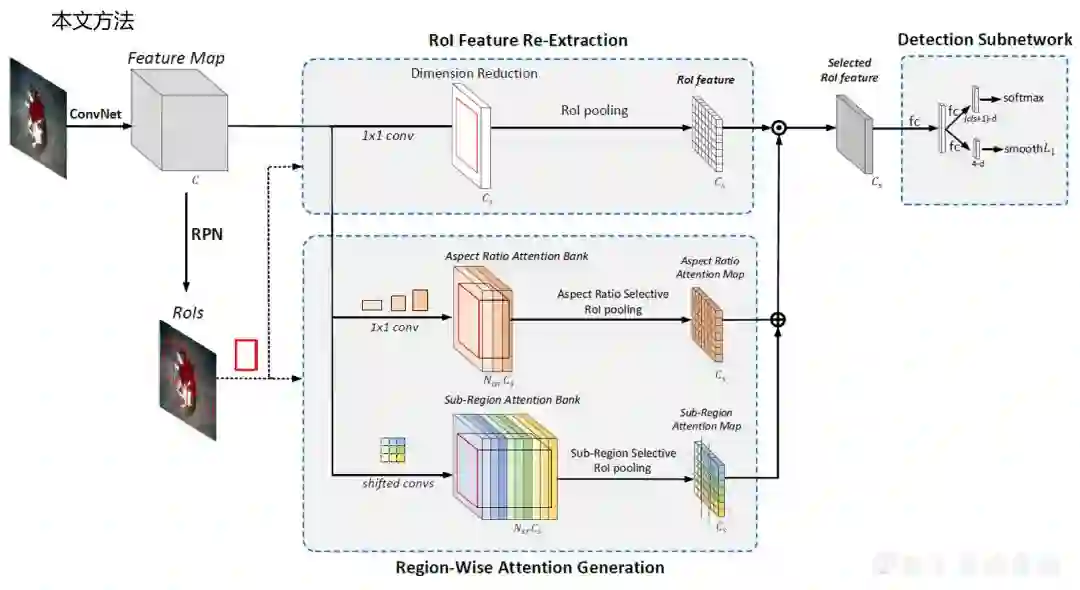
本文作者希望从具有平移不变性的卷积特征中提取有效的RoI特征,即,对于给定的整幅图像的卷积特征和候选区域之后的RoI特征的提取工作。为此,作者提出feature selective networks通过探测位于不同区域或者具有不同表观比的感兴趣区域的不同,重新形成感兴趣区域的特征表示,即将原始的RoI pooling提取感兴趣区域的过程改为用feature selective networks提取感兴趣区域的过程。feature selective networks过程如下:
feature selective networks首先为整幅图像生成sub-region attention bank和aspect ratio attention bank,;
分别对这两个banks使用aspect ratio selective RoI pooling和sub-region selective RoI pooling生成对应的aspect ratio attention map和sub-region attention map;
用的到的两个maps改善原始的RoI特征。
使用RoI pooling的二阶段网络结构图:
本文方法,使用feature selective networks的二阶段网络结构图:
本文通过以下几个方面解读此篇论文:
动机:传统RoI pooling提取的特征存在的问题;
方法:算法总览;
方法:feature seletive networks的网络结构的详细设计过程;
降维
Attention banks
sub-region attention bank
aspect ratio attention bank
Attention maps
检测子网络
实验。
RoI pooling之后得到的RoI特征存在以下几个问题:
RoI特征来自于原始的卷积特征,原始的卷积特征的通道个数都很大,因此RoI特征的维度也特别高,导致后续的网络参数规模大,推理时间长。有人可能有疑问,区域分类和回归是否需要如此多通道的RoI特征呢?通常,由于精确的提议生成,大多数RoI都覆盖了目标的大部分区域,这意味着通过RoI特征的重新提取来突出显示深度特征中具有判别式的特征成分是有可能的。
通过传统的RoI pooling层得到的RoI特征具有平移不变性,卷积神经网络在特征图的所有位置共享权重,形成了整幅图像的平移不变特征表示。举个例子来说,一个物体的边界部分需要更多描述边缘或者轮廓的特征来用于定位,而一个物体的中间部分需要更多描述纹理的特征来用于分类,所以对于一个RoI中的边缘部分应该更多的提取与边缘和轮廓相关的特征,其中间部分应该更多的提取与纹理相关的特征,但是现在的深度特征没有关注某个部分是位于一个物体的边缘还是中间,所以提取的不同位置的特征对于不同信息的关注度是相同的。
另外,来源于不同的类别或者所观察的视角不同的目标应该保持不同的表观比,然而,在传统的RoIpooling中,RoI特征的提取是独立于不同子区域与不同表观比的,不同子区域的特征通过将卷积特征的所有通道池化得到,没有强调与位置和表观比相关的信息。
算法总览:
RoI特征提取:
1. 在region-wiseattention 生成以前,先采用1×1的卷积层对通道进行降维,降维到Cs维,然后池化这些紧凑的RoI特征。
逐区域注意力生成:
2. 然后得到region-wise attention:
为了生成定制的sub-regionattention map,假设每个RoI被划分成Nsr个子区域(Nsr=3×3),因此通过一组设计的shifted convolution层将整幅图像生成一个Nsr*Cs维的sub-regionattention bank;
同样的,为了生成aspectratio attention map,将不同表观比的RoI划分成Nar类( Nar=3"),然后生成Nar*Cs维的aspect ratio attention bank;
3. 一旦提供了RoI的详细信息,两个设计的selective RoI pooling层分别最大池化sub-regionattention bank和aspectratio attention bank中的active attention maps,得到sub-regionattention map Msr和aspectratio attention map Mar。为什么叫active attention map呢,因为对于任意一个位置的特征,它的特征选择取决于它位于当前RoI的哪块子区域以及当前RoI的表观比,所以相同位置的特征的选取是动态的根据当前RoI的信息决定的。
4. 将sub-regionattention map Msr和aspectratio attention map Mar逐元素相加得到translate-variantattention map。
最终的RoI特征:
5. 然后将translate-variantattention map和compactedRoI特征通过逐元素相乘得到最终的RoI特征。
接下来分别介绍:
降维
Attention banks
Sub-region attention bank
Aspect attention bank
Attention maps
Selective RoI pooling
检测子网络
降维:
传统RoI pooling层就是个可以生成固定长度RoI特征的特征提取器,而得到的RoI特征的维度很高,相比于之前的网络,作者重新提取RoI特征,此RoI特征具有明显较小的通道数。通过采用1×1的卷积层将通道数量从C降为Cs,然后通过max pooling生成紧凑的RoI特征,这些紧凑的RoI特征通过后续的平移变化特征优化。
Attention banks:
为了实现平移可变特征的选择,需要预测attention banks,attention banks中存储了空间点位于RoI的不同子区域或者具有不同表观比时所有可能的attention maps。attention banks包括:Sub-region attention bank 和Aspect ratio attention bank。
Sub-region attention bank :
目标位于RoI不同的子区域中通常具有明显不同的空间特征,比如位于边界的区域其边缘特征比较突出,而位于中间的区域其纹理特征比较突出,然而通过RoI pooling提取的特征是位置独立的。作者通过生成一个sub-region attention bank来解决这个问题。在sub-region attention bank中,每个位置的attention向量由与他所在的RoI子区域的位置相关成分组成。
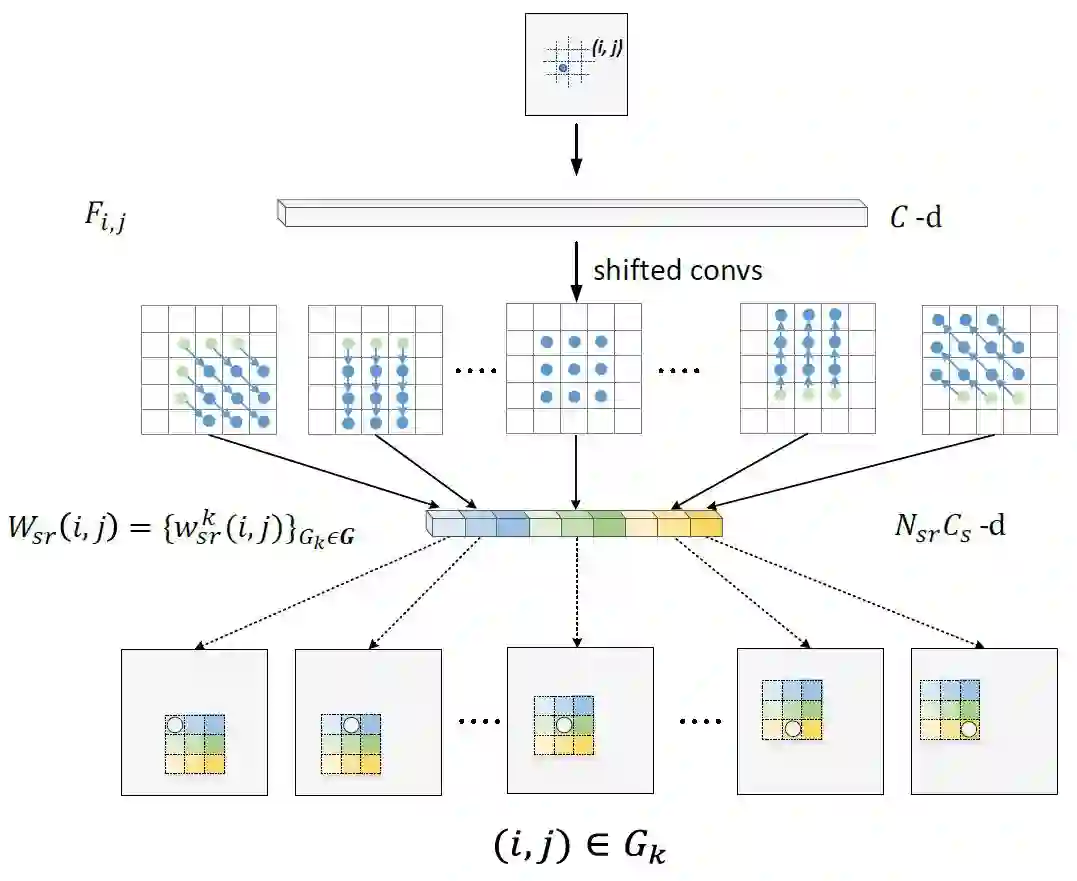
输入图像经过ConvNet得到全图的卷积特征,其特征维度为C*M*N,在(i,j)个位置的特征为Fij,长度为C,如果该区域位于RoI中的第k个子区域,那么该区域在active sub-region attention中的特征为Pij-k,长度为Cs,Pij-k=Gk(Fij)。
Gk表示特征注意力提取器,通过第k个平移卷积层实现,其参数通过反向传播学习得到。假设该区域分别位于RoI中不同的子区域,得到不同的Pij-k,将这些Pij-k在通道方向连接起来得到Pij。假设一个RoI分成3*3个子区域,那么最后得到的Wij的长度为9*Cs。整个P的维度为(9Cs)*M*N。
shifted convolution:
作者设计了一组shifted convolutional layers,通过其作用在整个图像的特征上得到sub-region aware attention bank。这个shifted convolution可以看作deformable convolution的一个特例,而不同于deformable convolution,特征图中不同位置的shifted convolution具有相同的2D偏移,如上图。平移的方向与到ROI中心的方向一致。
Aspect ratio attention bank:
除了考虑位置信息,该网络还考虑表观信息,实际中,不同类别的物体具有不同的表观,相同类别的物体在不同的视角下或者因其不同的姿势也呈现不同的表观。比如人站立的时候与坐着的时候的表观是不同的,因此表观信息也应该考虑在RoI 特征提取中。传统的RoI pooling为所有的RoI生成固定大小的特征表示,忽略了他们之间的表观不同。
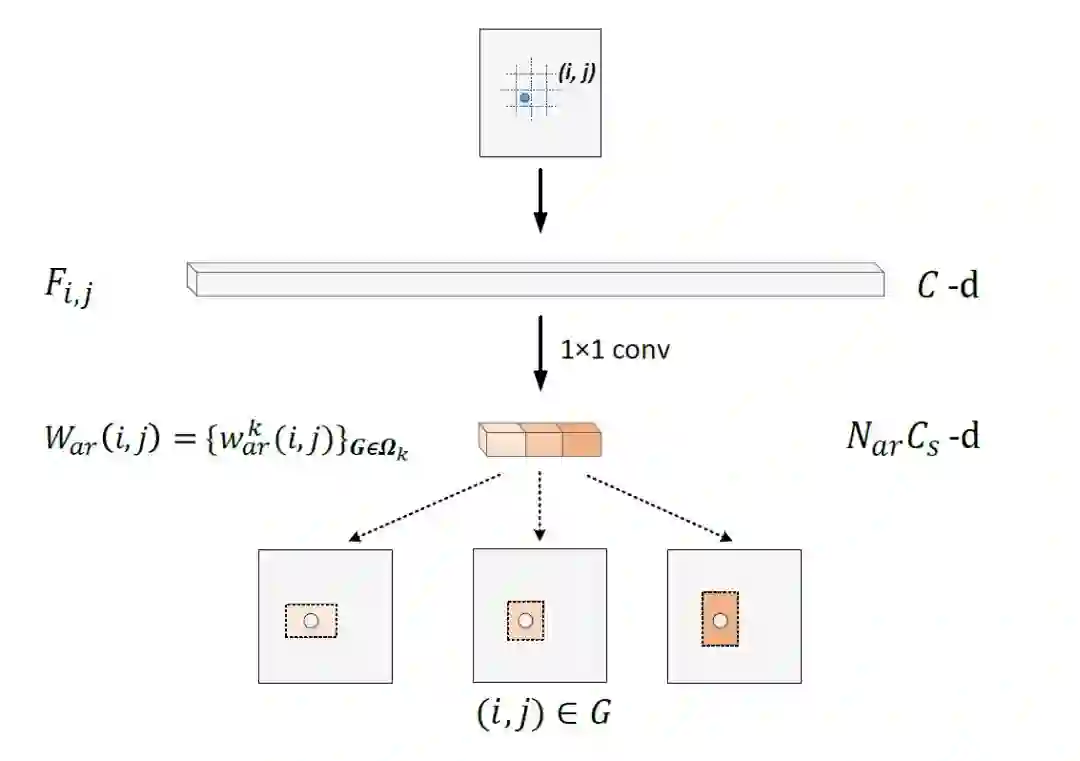
为了解决这个问题,该网络利用表观信息生成aspect ratio attention bank。与sub-region attention bank类似,通过一个1*1的卷积层得到每个空间位置的表观注意力成分。如果某区域(i,j)所在的RoI属于第k类,那么该区域在active sub-region attention为Qij-k,即通过一个1*1的卷积核作用于Fij上得到长度为Cs的特征Qij-k。假设该区域所在的RoI具有不同的表观比,得到不同的Qij-k,将这些Qij-k在通道方向连接起来得到Qij。
假设将不同的表观比分为3类,ratio<0.75的作为一类,ratio>1.3的作为一类,其他的作为一类。那么最后得到的Qij的长度为3Cs,对应的Q的维度为3Cs*M*N。
Attention maps:
在feature selective network中,attention banks揭露不同子区域和不同表观比的特别的和不同的表征。一旦RPN给出候选感兴趣区域,那么就可以通过将sub-region 和aspect ratio的详细信息通过selective RoI pooling层得到translation-variant attention maps。selective RoI pooling层通过利用max pooling将在attention banks中的RoI映射为一个固定长度的attention vector(e.g. Cs*7*7)。
Selective RoI pooling:
特定的,对于一个RoI窗口,第(m,n)-pooling bin分别对应着sub-region attention bank和aspect attention bank中的第ksr和kar个索引。特别的,如果对于sub-region attention bank,索引ksr为当前pooling bin中像素位于最多的那个子区域所对应的索引,对于aspect ration attention map,索引kar为所属于的RoIaspect ratio对应的索引。
得到索引以后通过下式进行特征提取:
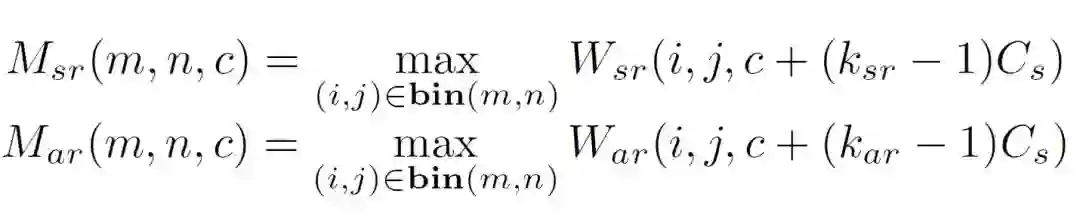
对于sub-region attention map:
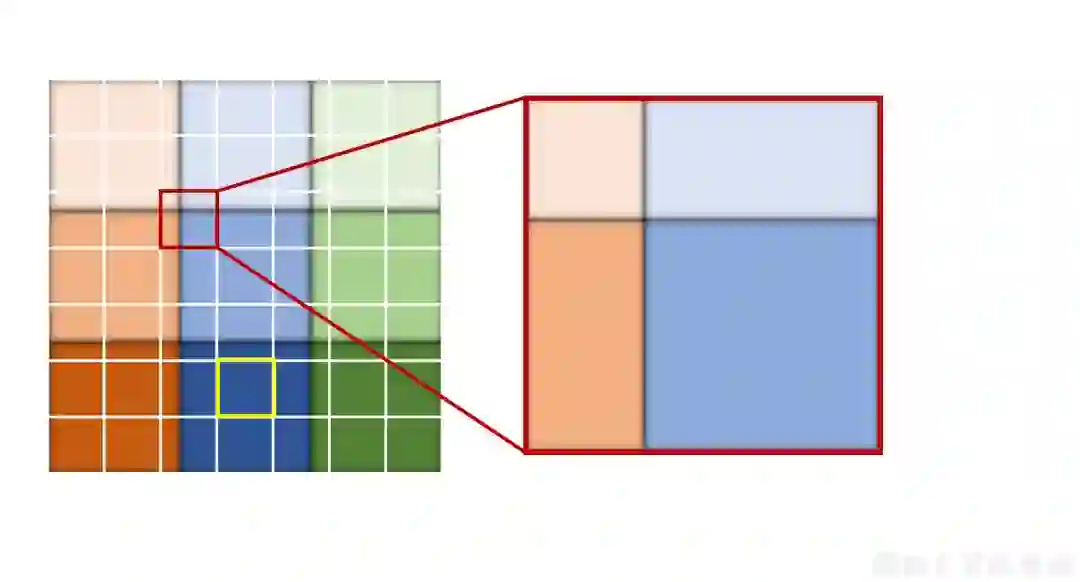
比如说该RoI中的pooling bin中的像素位于sub-region attention bank中的第k块子区域那么就取对应区域的(k-1)Cs+1:(k-1)*Cs通道的特征,如下图中黄色方框的pooling bin中的像素都属于同一个子区域。如果该pooling bin中的像素属于RoI中的不同子区域,那么以该pooling bin中的像素位于最多的那个子区域所对应的通道块取,如下图中红色的方框的pooling bin中的像素位于RoI中不同的子区域,但是其中属于红色框中右下角对应的子区域的像素最多,所以该pooling bin取红色方框右下角对应子区域对应的通道块。
对于aspect ration attention map:
假如RoI属于表观比分类中的第k类,那么该RoI的aspect ration attention map对应着aspect ration attention bank 中的第(k-1)Cs+1:k*Cs通道的特征。
检测子网络:
通常,两阶段检测器的检测子网络都特别深或者是容量特别大(4096-d),因为简明且信息丰富的RoI特征提取器,可以简化检测子网络为一个单一的低容量(500d)fc层。
实验:
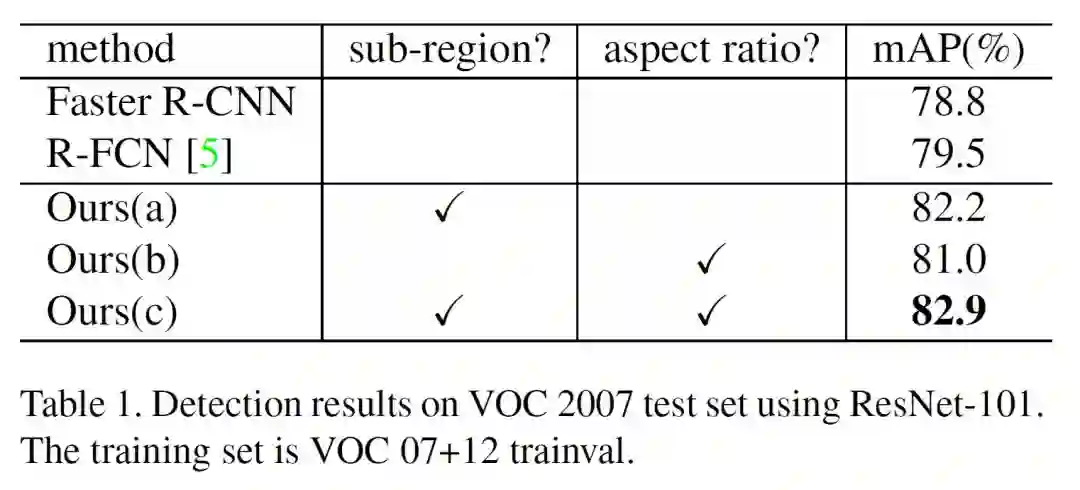
上表:基网络为ResNet-101,a表示只用sub-region,b表示只用aspect ratio,c表示同时使用sub-region和aspect ratio。
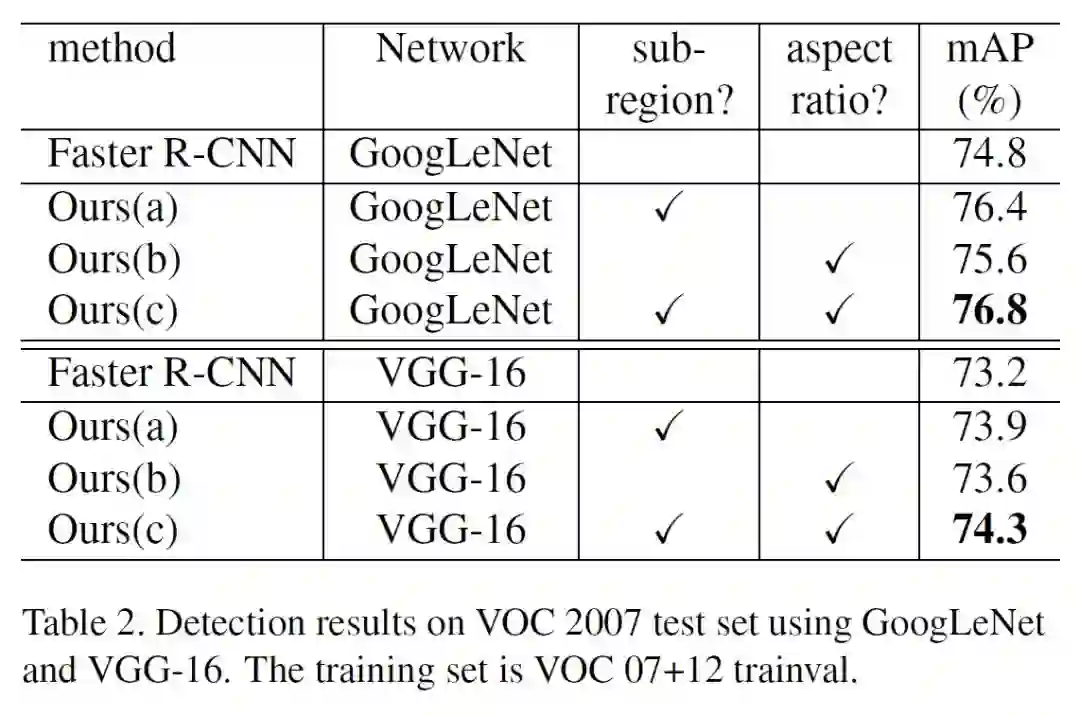
上表:基网络为GooLeNet和VGG-16。
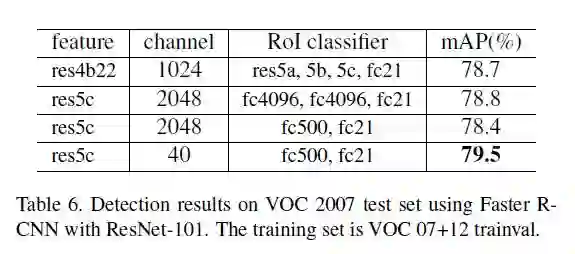
上表:降维实验对比。
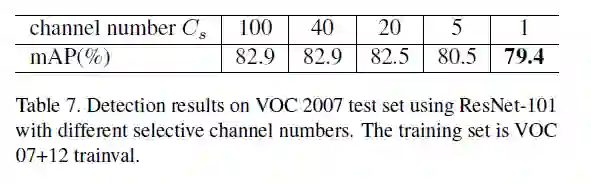
上表:不同的Cs实验对比。
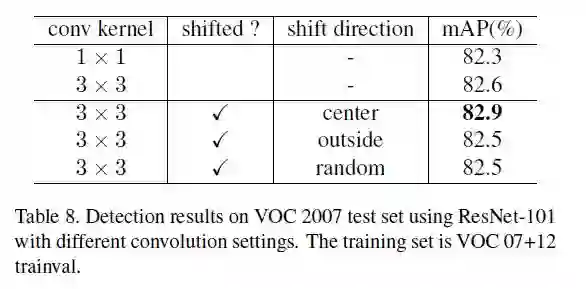
上表:shifted convolution对比实验。



