CVPR2019 | FSAF:来自CMU的Single-Shot目标检测算法
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~

作者 | ywsun
来源 | https://zhuanlan.zhihu.com/p/58508985
论文地址 | https://arxiv.org/abs/1903.00621
今天介绍CVPR2019的一篇single-stage detection的文章,来自CMU。
Motivation
目标检测中物体尺度问题一直是个难解决的问题,目前为止主要是从网络结构设计、损失函数、训练方式等方面去缓解尺度带来的烦恼,特别是小物体检测,至今没有一个好的解决方案。在这些方法中,最常见的非Feature Pyramid Network(FPN)莫属了,它利用多级的feature map去预测不同尺度大小的物体,其中高层特征带有高级语义信息和较大的感受野,适合检测大物体,浅层特征带有低级的细节语义信息和较小的感受野,适合检测小物体。FPN逐步融合深层特和浅层特征,使得逐步增加浅层的特征的高级语义信息来提高特征表达能力,提升检测效果。得益于其强大的特征表达能力带来的性能提升,现在FPN结构已经成为检测框架的一个标配组件。
在经典的带有FPN的框架中,有这样一个隐藏操作在里面:选择一层合适的feature map负责检测物体。比如在two-stage里面,会有RoI pooling,将物体对应的feature抠出来送入不同分支完成分类和位置回归。Faster R-CNN用的是RoI pooling,Mask R-CNN用的是RoIAlign,这个地方改进是为了解决pooling操作带来的misalignment问题,但不是本文关注的重点。本文关注的是如何“合理”地选择feature来检测物体,并且针对的是single-stage这一类模型。但single-stage没有roi pooling这一操作,何来选择feature这一说呢?
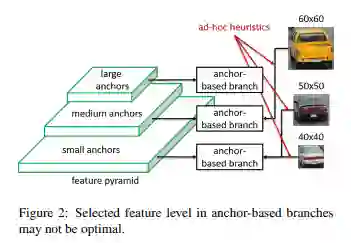
在single-stage模型中,我们会定义一系列稠密的均匀分布的anchor,这些anchor会根据其不同的尺寸大小和不同的feature map联系起来。在带有FPN的backbone中,高层的feature map分辨率高,得到的anchor数量多尺寸小,浅层的feature map分辨率低,得到的anchor数量少尺寸大,anchor的生成是根据feature map不同而定义的。在anchor match gt阶段,gt与anchor匹配,确定gt归属于哪些anchor,这个过程隐式的决定了gt会由哪层feature map负责预测。不管是生成anchor还是gt match 过程,都是由size这个变量决定,虽然我们会设定先验的规则来选择最好的feature map,但存在的问题是,仅仅利用size来决定哪些feature map来检测物体是一种暴力的做法。如下图所示,60x60大小的car和50x50大小的car被分在了不同feature map,50x50和40x40的被分在了同一级feature map,谁也不能证明这种做法不好,但谁也不能证明这种做法就是最好,那么何不让模型自动学习选择合适的feature 去做预测呢?
Method
Feature Selective Anchor-Free Module (FSAF)
文章提出FSAF模块让每个instance自动的选择最合适的feature,在这个模块中,anchor box的大小不再决定选择哪些feature进行预测,也就是说anchor (instance) size成为了一个无关的变量,这也就是anchor-free的由来。因此,feature 选择的依据有原来的instance size变成了instance content,实现了模型自动化学习选择feature。
先来看看FSAF的结构。文章提出的FSAF以RetinaNet为主要结构,添加一个FSAF分支和原来的classification subnet、regression subnet并行,可以不改变原有结构的基础上实现完全的end-to-end training,特别是,FSAF还可以集成到其他single-stage模型中,比如SSD、DSSD等。
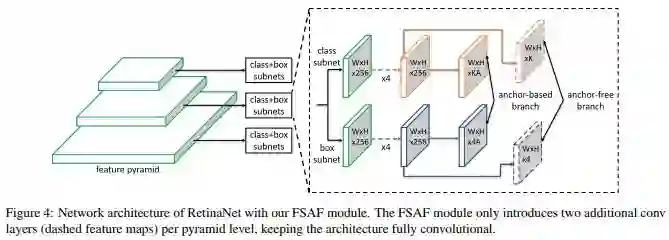
FSAF同样包含classification和box regression两个分支,分别得到predict box所属的类别和坐标值。
Ground-truth和loss的设计

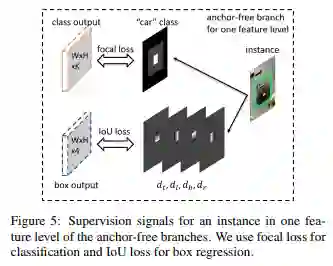
classification output是一个WxHxK大小的feature map,K表示物体类别数,那么在坐标为(i,j)的点上是一个长度为K的向量,表示属于每个类别的概率。分支对应的gt是图中白色区域内值为1,表示正样本,黑色区域内值为0,表示负样本,灰色区域是忽略区域不回传梯度。分支采用Focal Loss,整个classification loss是非忽略区域的focal loss之和,然后除以有效区域内像素个数之和来正则化一下。

值得注意的是,FSAF模块没有了anchor scale、aspect ratio等概念,是一个anchor-free的检测方法(和CornerNet不同)。
Online Feature Selection
FSAF的设计就是为了达到自动选择最佳Feature的目的,最佳Feature是由各个feature level共同决定。
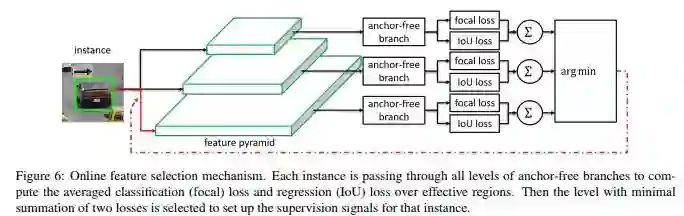
选择过程如下:
每个feature level计算classification loss和box regression loss
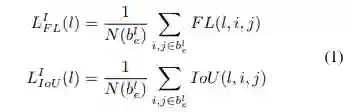
所有feature level中选择loss最小的作为梯度反传。
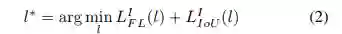
为了验证自动特征选择的有效性,文章同时对比了heuristic feature selection,该方法就是经典FPN中所采用人工定义方法:
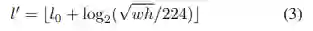
关于training和inference,
在inference中,FSAF可以单独作为一个分支输出预测结果,也可以和原来的anchor-based分支同时输出预测结果。两者都存在时,两个分支的输出结果merge然后NMS得到最后预测结果。
在training中,采用multi-task loss,即 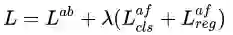
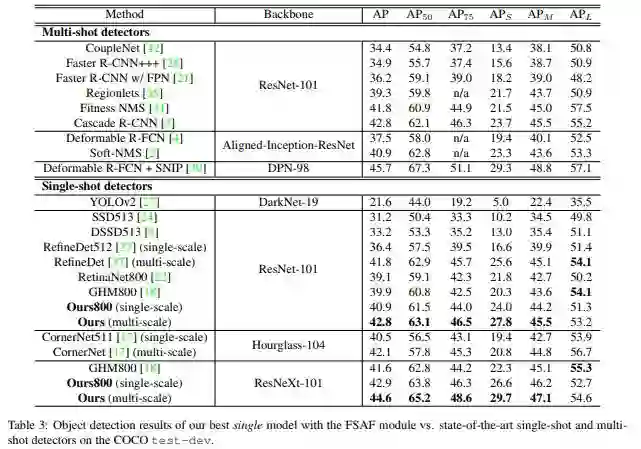
Experiments
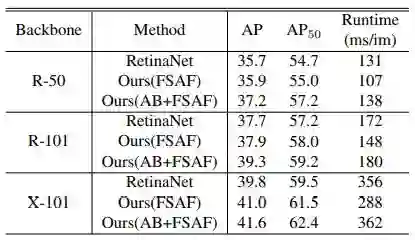
作者在ablation study部分分析了anchor-free的必要性,online feature selection的重要性,以及选择的feature level是不是最优的。同时还指出FSAF非常robust和efficient,在多种backbone条件下,都有稳定的涨点。在ResNext-101中,FSAF超过anchor-based1.2个点,同时快了68ms,在AB+FSAF情况下,超过RetinaNet1.8个点,只慢了6ms,效果也是非常显著的。
总结
文章从feature selection角度设计了新的FSAF module来提升性能,个人认为其实从loss角度来看,提升了梯度反传的效率,有点类似于SNIP,只更新特定scale内物体对应的梯度,但又和SNIP不一样,效率比SNIP高。
但想补充一点,关于有效区域和忽略区域的比例是不是应该再分析一下,感觉对实验结果是有影响的。
ps.CVPR2019 accepted list已经放出,极市已将目前收集到的公开论文总结到github上(目前已收集121篇),后续会不断更新,欢迎关注,也欢迎大家提交自己的论文:
https://github.com/extreme-assistant/cvpr2019
*延伸阅读
CVPR2019 | 目标检测新文:Generalized Intersection over Union
聊聊目标检测中的多尺度检测(Multi-Scale),从 YOLO到FPN,SNIPER,SSD 填坑贴和极大极小目标识别
小Tips:如何查看和检索历史文章?
有不少小伙伴提问如何号内搜文章,其实很简单,在“极市平台”公众号后台菜单点击极市干货-历史文章,或直接搜索“极市平台”公众号查看全部消息,即可在如下搜索框查找往期文章哦~
ps.可以输入CVPR2019/目标检测/语义分割等等,快去探索宝藏吧~~
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~

觉得有用麻烦给个好看啦~

