Relation Networks for Object Detection 论文笔记
CVPR 2018 论文 论文链接 https://arxiv.org/abs/1711.11575
本文亮点:
将《Attention Is All You Need》中的 Attention 机制应用到目标检测领域,设计出的目标关系模块很容易的集成到任意网络中。
用目标关系模块代替传统NMS算法进行去重,检测网络完全可以端到端训练。
1.摘要
在视觉领域,我们都知道,建模物体间的关系,有利于目标识别任务。但是在深度学习领域,很少有利用物体关系进行目标识别任务的。本文提出了一种目标关系模块(Object Relation Module),它同时处理一组目标,对目标之间的外观特征关系和位置关系进行建模。该模块的输入输出维度相同(in-place),不需要额外的监督,因此很容嵌入到已有网络中。实验表明,在目标检测网络的目标识别和去重两个阶段添加目标关系模块,可以提高检测精度,并实现完全的端到端目标检测器。
2.介绍
目标关系模块使用了 Attention 机制,基本思想来源于 Google 的一篇 NLP 方向的文章《Attention Is All You Need》(链接:https://arxiv.org/abs/1706.03762)。作者设计的 Attention 权重由两部分组成,外观特征关系权重和空间关系权重。 作者将目标关系模块应用到区域特征提取后的 FC 层,使目标特征包含物体间的关系信息,增强目标识别能力。作者还将目标关系模块应用到去重阶段,代替传统的 NMS 算法,提高网络识别精度,同时可以使网络进行端到端的训练,如图1所示。
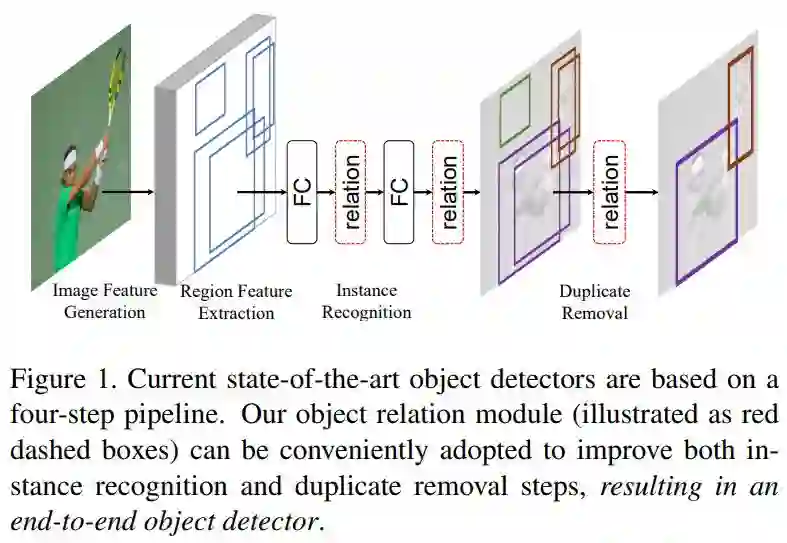
图1 目标关系模块(红框)应用到实例识别和去重阶段
3.目标关系模块
在 Google 的文章中,称这种 Attention 机制为“Scaled Dot-Product Attention”。计算过程用公式1表示:
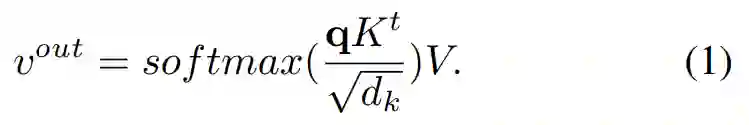
输入一个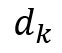
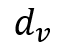
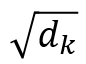
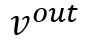
下面看一下本文是如何将上述公式应用到关系模块的: 物体的特征由两部分组成,空间特征

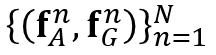
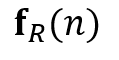
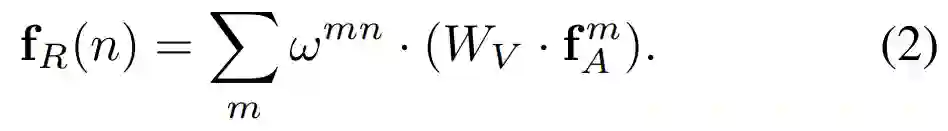
输出是所有外观特征的加权和。

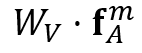
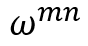
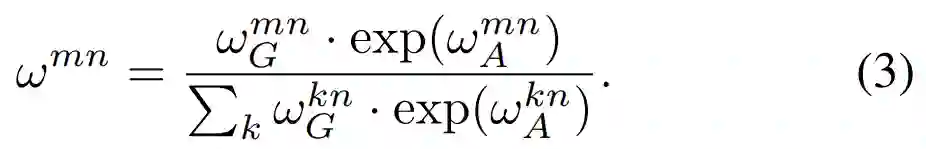
分母是一个归一化项。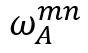
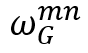
外观权重的计算公式为:
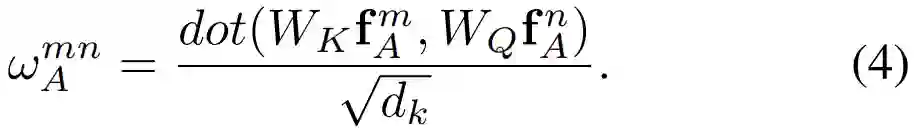
其中

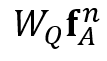
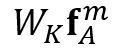
空间权重的计算公式为:
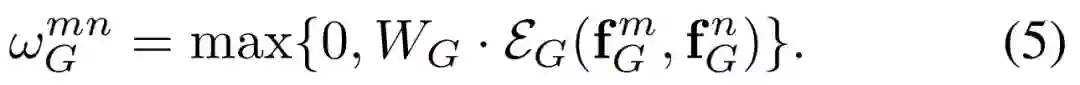
分为两步。第一步,先计算两个物体之间的相关空间特征:
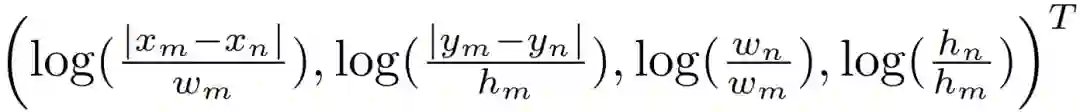
上式类似于边界框回归时的计算目标,保证了平移、缩放不变性。接下来使用《Attention Is All You Need》中的方法将4维的相关空间特征嵌入(Embedding)到高维,得到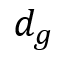
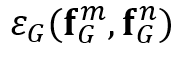
第二步,将嵌入的特征与
在目标关系模块中,作者将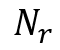
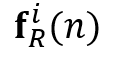

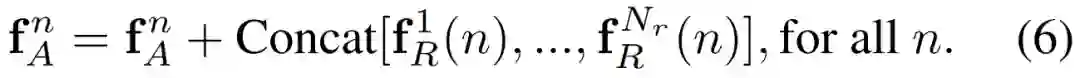
这里,假设外观特征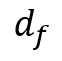
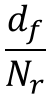
图2展示了目标关系模块的整个计算流程,蓝色标记的是特征或矩阵的维度大小。
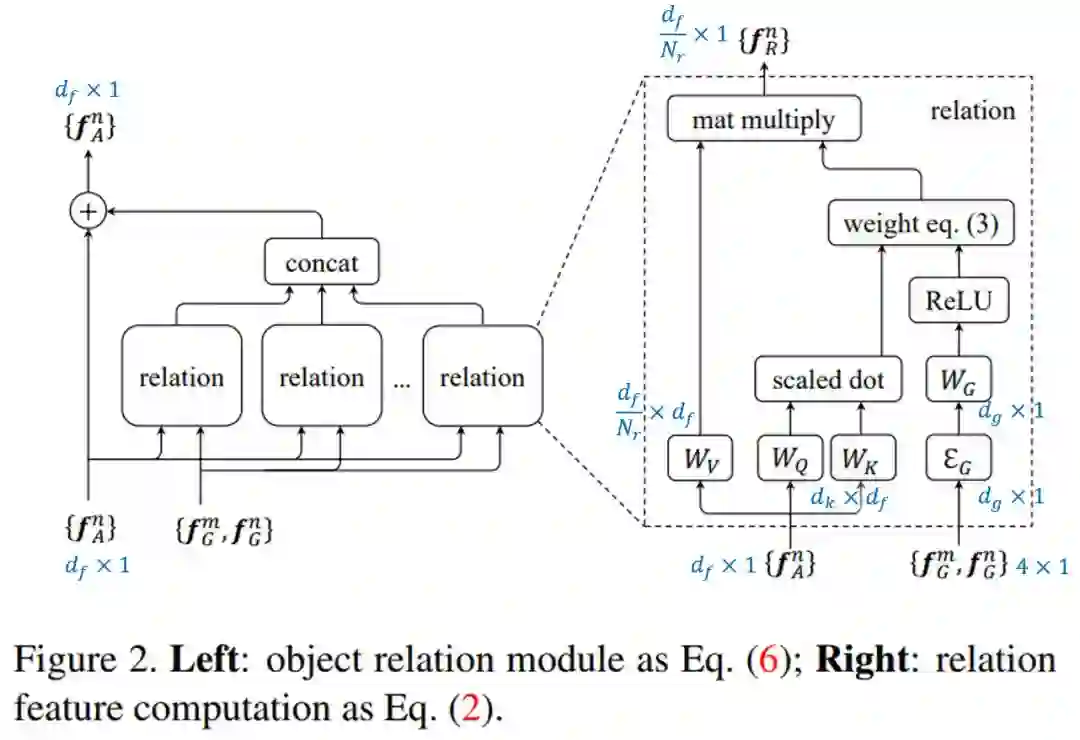
图2 目标关系模块
图中共有
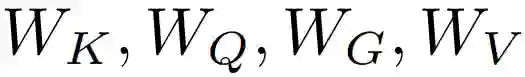
因此,一个目标关系模块,参数个数为:
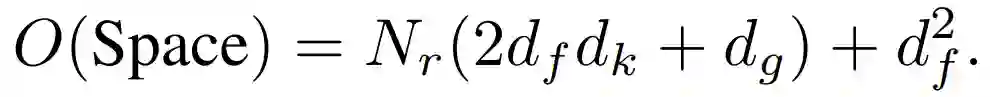
本文中,作者设置
4.应用到目标检测
实例检测阶段
Faster R-CNN,FPN,DCN 等目标检测网络,RoI Pooling 层输出的特征都会与2个全连接层相连,然后预测类别得分和边界框回归。大致流程如图3所示,这里 FC 层输出的维度大小为1024。
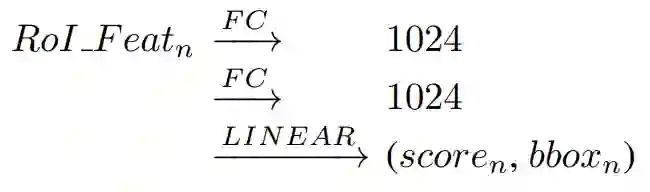
图3 目标检测网络分类回归阶段流程
作者在每个 FC 层后,加入目标关系模块,保证输入 N 个 proposals 前后,特征维度不发生变化。大致流程如图4所示。
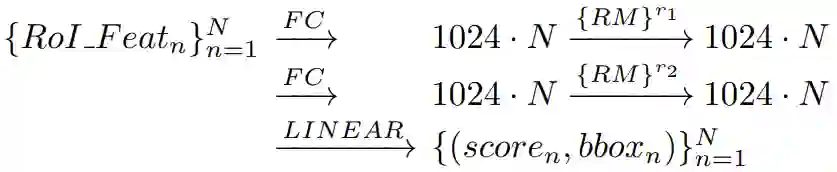
图4 加入目标关系模块后的流程
网络的检测部分,由 2fc 变为了 2fc+RM(Relation module),网络结构如图5所示。
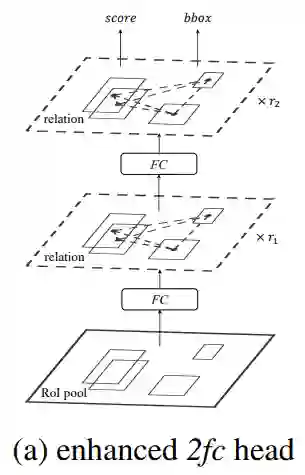
图5 2fc+RM
去重阶段
作者将去重看作一个二分类问题,其流程如图6所示:
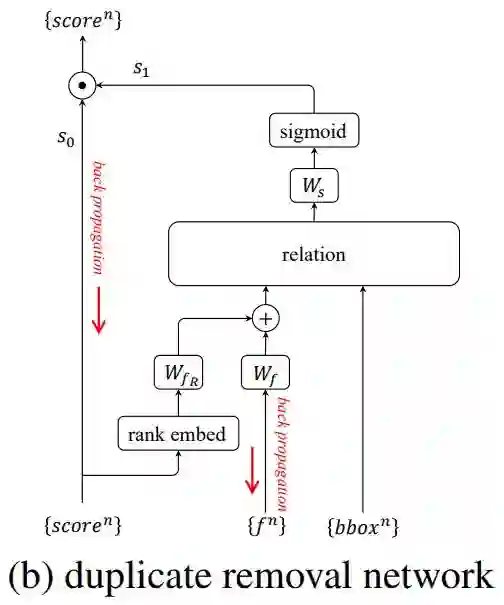
图6 去重阶段流程
在分类和边界框回归分支,网络输出了分类得分 s0 和预测的边界框 bbox。作者先将 N 个物体的得分从大到小排序,每一个物体排序的序号(rank)∈[1,N]。与


去重阶段正负样本选取:对于每一个 ground truth box,选取边界框回归阶段 IoU ≥η 的框中得分最高的为正样本,其他为负样本。
s0*s1 的设计很巧妙,避免了正负样本不平衡的问题,对于负样本,损失函数为:
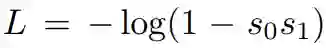
反向传播的梯度为:

由于负样本 s0 很小,因此对优化目标影响很小。
在实践中,去重网络使用 GPU 执行,耗时约为 2ms。NMS 和 Soft NMS 使用 CPU 执行,耗时约为 5ms。
5.实验
验证检测阶段的效果
作者将使用两个FC层的网络设为baseline。
(1)空间特征 为了验证空间特征的有效性,作者设计了3组实验。将空间关系权重
(2)关系数量
结果如表1(b)所示。
(3)关系模块的数量 分别在两个FC层后添加不同数量的关系模块,实验结果如表1(c)所示。

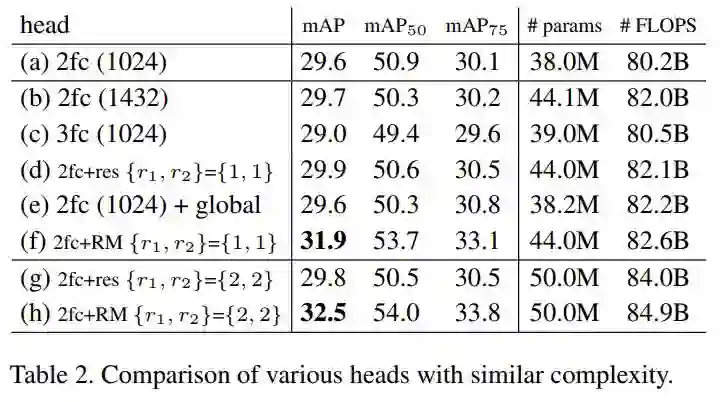
效果的提升是来自参数和层数的增加吗?
表2对比了不同深度,宽度的网络结构。
验证去重阶段效果
表3验证了去重网络所使用的特征是否有效。可以看出rank特征和bbox特征起了很重要的作用。
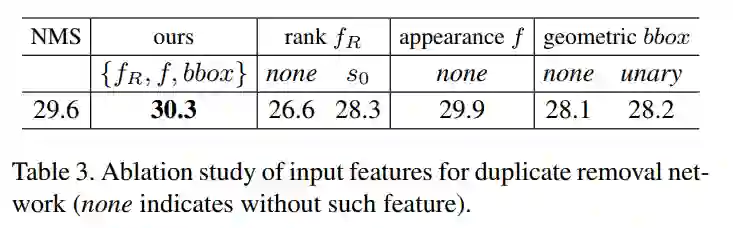
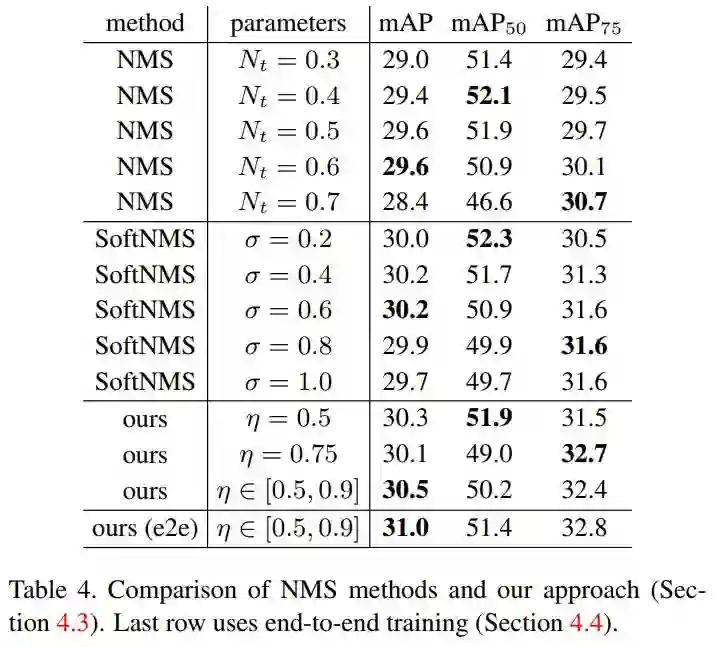
表4与NMS算法进行对比
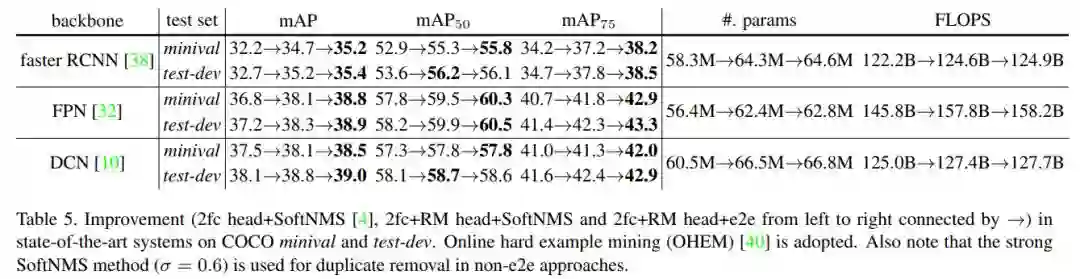
端到端的目标识别
作者使用不同的检测框架,进行对比。每一个网络框架,分别使用了 2fc head+SoftNMS -> 2fc+RM head+SoftNMS -> 2fc+RM head+e2e(end-to-end)三种网络结构。实验结果如表5所示。