
题目:
SEED: Semantics Enhanced Encoder-Decoder Framework for Scene Text Recognition
简介:
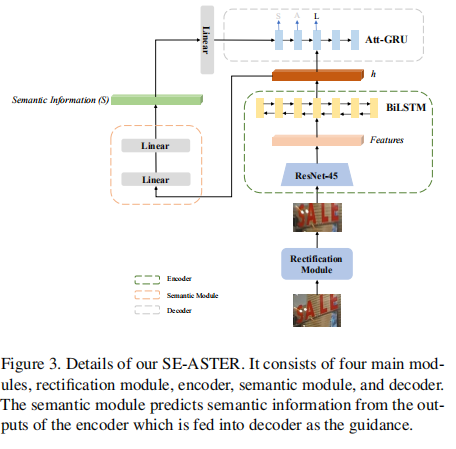
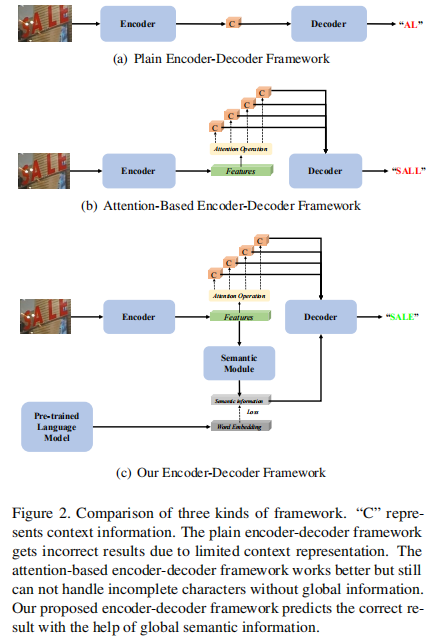
场景文本识别是计算机视觉中的一个热门研究主题。近来,已经提出了许多基于编码-解码器框架的识别方法,它们可以处理透视失真和曲线形状的场景文本。尽管如此,他们仍然面临许多挑战,例如图像模糊,照明不均匀和字符不完整。我们认为,大多数编码器/解码器方法都是基于局部视觉特征而没有明确的全局语义信息。在这项工作中,我们提出了一种语义增强的编码器-解码器框架,以可靠地识别低质量的场景文本。语义信息在编码器模块中用于监视,在解码器模块中用于初始化。特别是,将最新的ASTER方法作为示例集成到所提出的框架中。大量的实验表明,所提出的框架对于低质量的文本图像更健壮,并且在多个基准数据集上都达到了最新的结果。
成为VIP会员查看完整内容
相关内容

专知会员服务
29+阅读 · 2020年3月27日
专知会员服务
39+阅读 · 2020年3月19日
Arxiv
5+阅读 · 2018年9月6日


相关VIP内容
专知会员服务
29+阅读 · 2020年3月27日
专知会员服务
39+阅读 · 2020年3月19日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年9月6日