CornerNet: Detecting Objects as Paired Keypoints 论文笔记
ECCV 2018 论文 论文链接 https://arxiv.org/abs/1808.01244 代码链接 https://github.com/umich-vl/CornerNet
主要创新:将人体姿态估计中的方法应用到目标检测,将对anchor box的分类任务变为对物体bbox角的预测,分组任务。不需要借助多尺度feature map来预测不同大小的目标。
1.介绍
目前,大多数的目标检测方法都基于anchor,网络中预先设定的大小不同的anchor box作为目标候选。 基于anchor-box的检测器有两个缺点: (1)需要设定密集的anchor box,但仅有一小部分anchor box与gt box有足够的IoU,导致代表正负样本的anchor box数量不平衡。(解决:OHEM,Focal Loss) (2)基于anchor box的检测方法引入大量超参数。如anchor box数量,大小,比例。
本文提出的CornerNet不需要anchor box。通过一个卷积网络预测每个类别所有实例bbox的左上角和右下角的热图(heatmap),以及每个角的嵌入向量(embedding vector),属于相同目标的嵌入向量更相似。网络的预测流程如图:
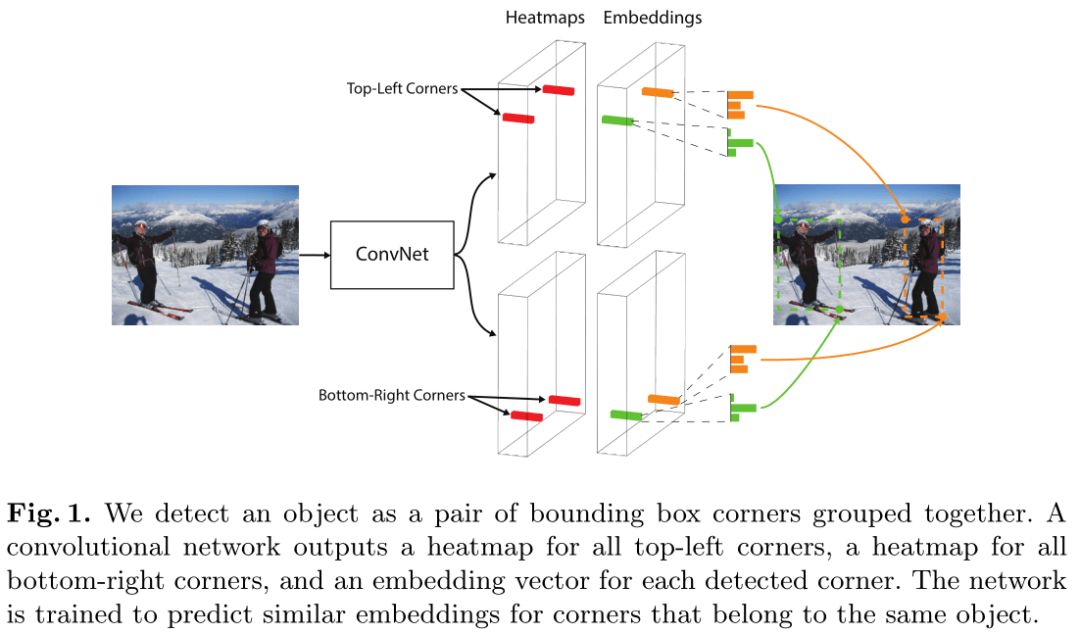
CornerNet中提出了一个corner pooling层,帮助网络更好的定位bbox的两个角。因为bbox的两个角通常在目标区域之外,如下图所示:
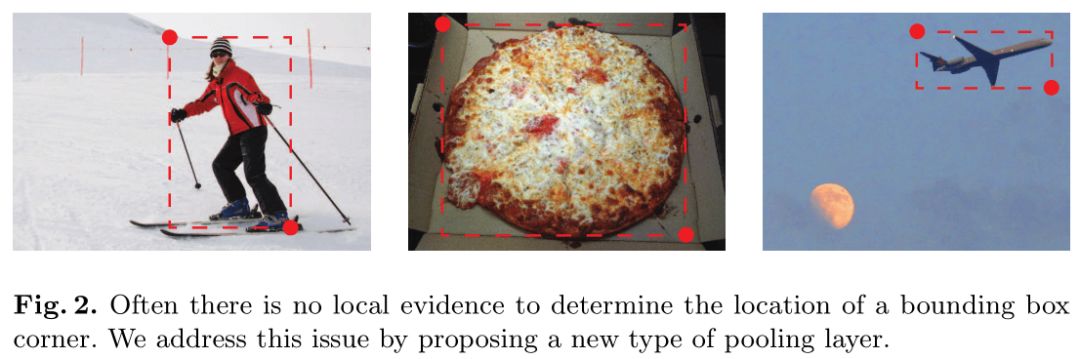
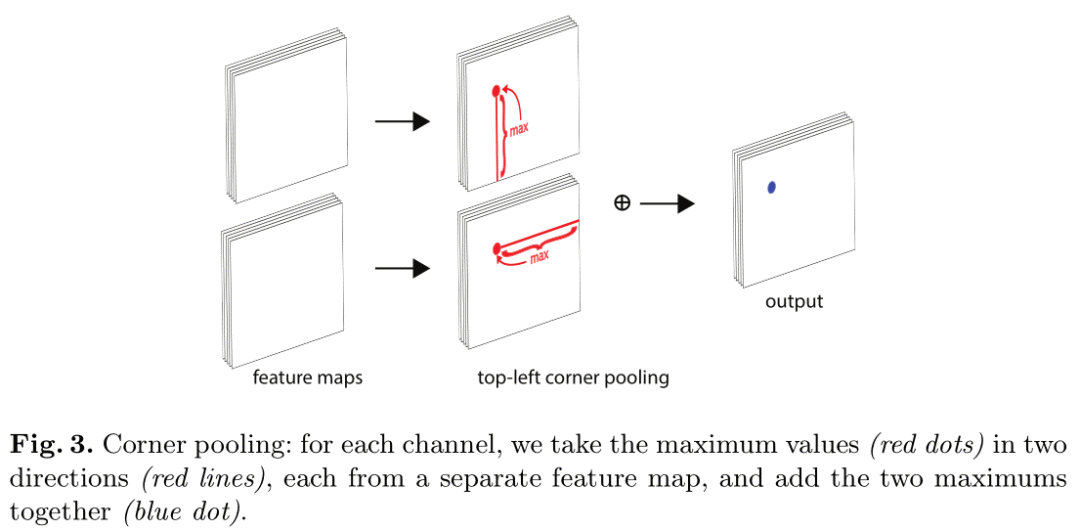
当判断某个像素位置是否为目标的左上角时,需要沿着水平方向向右看目标的上边界,沿着垂直方向向下看目标的左边界。corner pooling层基于此原理,输入两个feature map。对于第一个feature map,每个像素位置对其右侧所有向量进行最大池化;第二个feature map上每个像素位置对其下方所有向量进行最大池化,然后将两个池化后的feature map相加得到输出。过程如下图:
作者解释为什么检测bbox两个角比检测bbox中心好。作者认为bbox框的中心很难确定,因为它依赖4条边的信息,而检测每个角只需知道2条边的信息。而且通过corner pooling,结果包含了关于“角的定义”的先验知识。
2.方法
2.1 CornerNet
CornerNet结构如下:
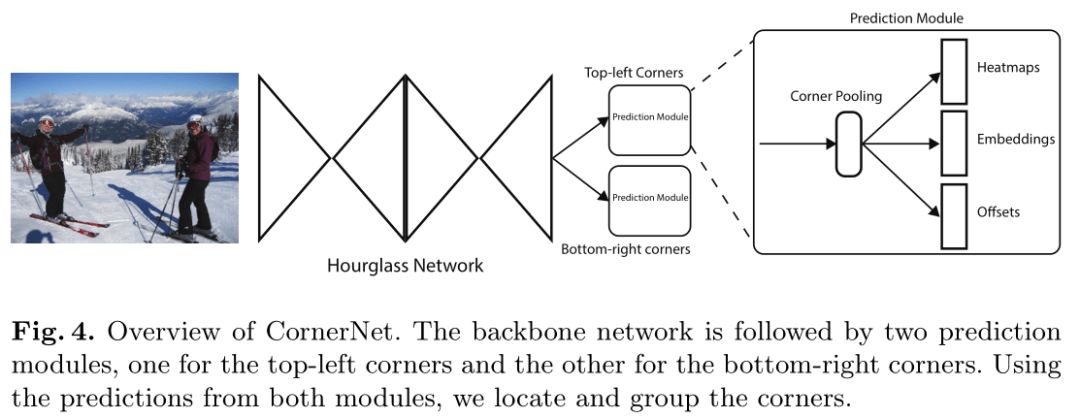
骨干网络使用hourglass网络,其后是两个预测模块,一个负责预测左上角,一个负责预测右下角。每个模块内都有自己的corner pooling层,池化之后预测热图,嵌入向量和偏移。CornerNet仅适用最后一层进行预测,没有使用不同尺寸的feature map来预测不同大小的目标。
2.2 检测角
网络预测两组热图,每组热图的通道数为C,C为目标类别数,不包含背景,大小为H×W。每一个通道是一个二进制掩码,表示一个类别的角的位置。 对于每个角,只有一个点为ground truth,其他位置的点都为负样本。在预测时,预测的角的位置稍有偏差,其bbox与ground truth的IoU通常也会很大,如下图所示:

因此在训练期间,当负样本角的位置在ground truth位置某个半径范围内时,减少其受到的惩罚(减小损失)。半径的大小与目标bbox大小有关,只要保证预测的bbox与ground truth的IoU>t即可,作者设置t=0.7。给定半径,减少受到惩罚的计算公式是一个二维高斯函数:exp(−(x^2+y^2)/(2σ^2 )),其坐标中心为角的正样本位置,设置σ为1/3半径。
记pcij为类别c在热图(i,j)位置上的得分,ycij为带有高斯函数的ground truth热图,检测的损失函数基于Focal Loss:
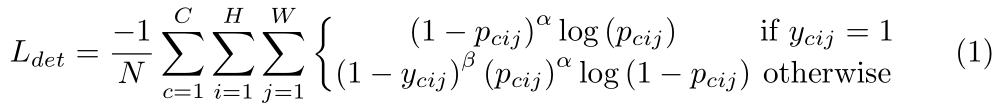
其中,N是图片中目标个数,α,β为控制热图上每个点损失的超参数,作者设置为α=2,β=4。(1−ycij )^β减小了正样本点附近的惩罚。
通常全卷积的网络的输出会对输入图像下采样n倍,原图上的点(x,y)在热图上的坐标为(⌊x/n⌋,⌊y/n⌋)。当将热图上的点对应到原图上时,可能会损失精度。因此网络还预测了每个点恢复后的偏移:
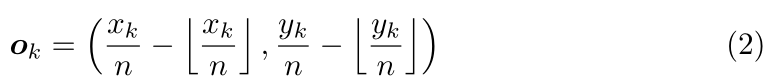
其中ok为偏移,xk,nk为第k个角在原图的坐标。网络分别为为所有类别的左上角和右下角各输出一组预测偏移,仅有正样本点有损失,损失函数为smooth L1:
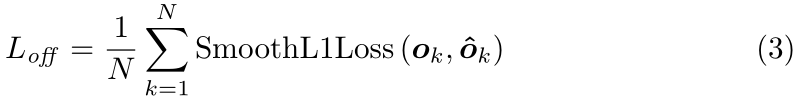
2.3 角分组
通过预测每个角的嵌入向量判断某个预测的左上角和右下角是否属于同一个目标。属于相同目标的嵌入向量距离近,因此之后可以根据向量距离给角分组。 作者使用1维的嵌入向量。记etk为物体k左上角的嵌入向量,ebk为右下角的嵌入向量。使用"pull"损失使目标的两个角距离近,使用"push"损失使不同目标的角距离远:
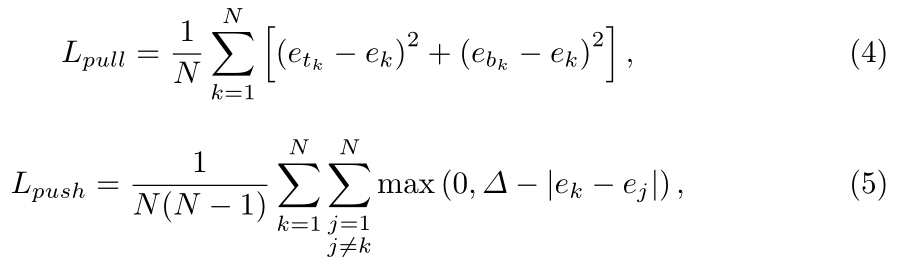
其中ek为etk和ebk的均值,作者设置Δ=1,目的是使|ek−ej|>Δ。仅有正样本点有损失。
2.4 Corner Pooling
以左上角的corner pooling为例,记输入到corner pooling的两个feature map为ft,fl,ftij,flij为(i,j)处的向量。feature map大小为H×W,corner pooling 层先将ft中(i,j)到(H,j)间的向量最大池化为tij,再将fl中(i,j)到(i,W)间的向量最大池化为lij,然后将tij,lij相加。公式如下:
流程如图:
右下角的corner pooling层类似,分别最大池化(0,j)到(i,j)和(i,0)到(i,j)间的向量。
Corner pooling层用在预测模块中,模块结构如图:
3.实验
3.1 训练细节
网络输入大小为511×511,输出大小为128×128。为了减少过拟合,使用了数据增广。如随机翻转,缩放,裁剪,颜色抖动(color jittering),包括亮度,饱和度和对比度。然后使用PCA处理图像。使用Adam优化算法,整体损失为:
作者设置α=0.1,β=0.1,γ=1。作者发现α,β>1影响精度。 使用10张显卡进行训练,作者在GitHub上说训练时间超过2周。。。
测试时,单张图片在Titan X上的的平均推理时间为244ms。
3.2 实验结果
实验在COCO数据集上进行。
验证Corner Pooling有效性
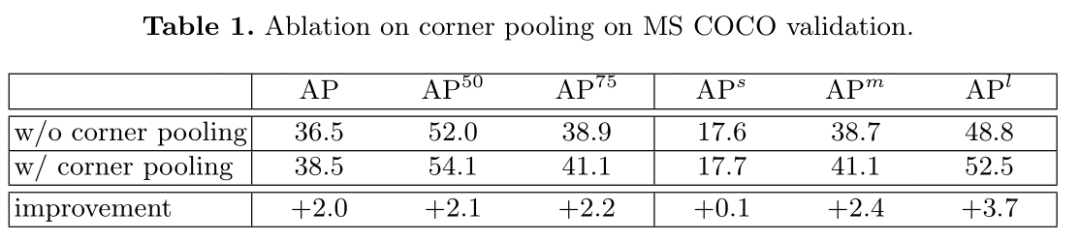
Corner Pooling对预测中,大尺寸目标很有帮助。
减少负样本角位置的惩罚
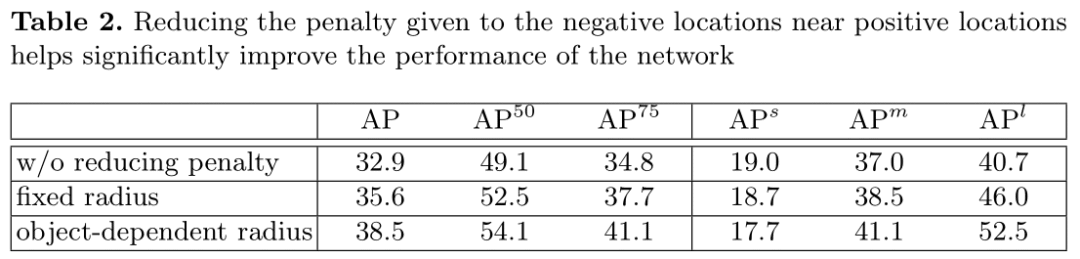
固定半径设为2.5。减少负样本角惩罚对预测中,大尺寸目标帮助较大。
误差分析 网络同时预测了热图,偏移和嵌入向量。每一项都会影响检测精度。通过用ground truth热图和偏移替换预测值来评估每部分的误差。
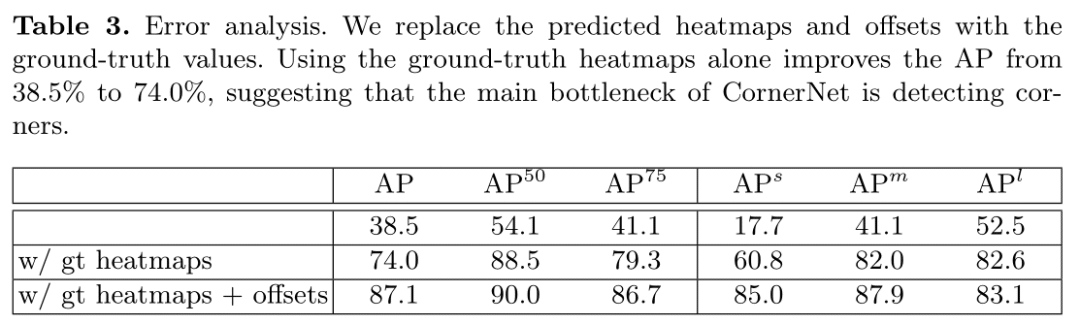
这说明角检测和分组的方法还有很大的提升空间,主要瓶颈在角检测部分。
下图是角检测热图放在原图上的结果:

与其他检测器对比
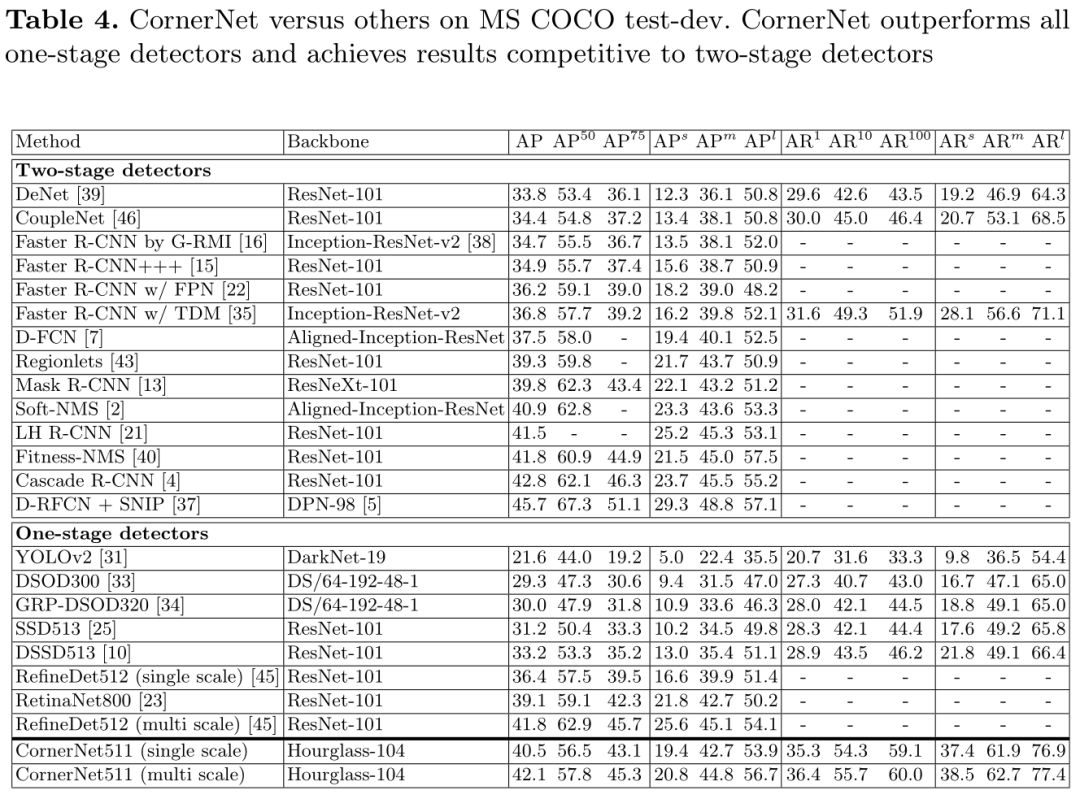
CornerNet使用多尺度预测,在COCO数据集上的AP为42.1%,优于其他one-stage检测器。
相关论文 作者的想法来自这篇 人体姿态估计 论文 Associative Embedding: End-to-End Learning for Joint Detection and Grouping(NIPS 2017) https://arxiv.org/abs/1611.05424
网络Backbone:Hourglass network Stacked Hourglass Networks for Human Pose Estimation(ECCV 2016) https://arxiv.org/abs/1603.06937
"pull push" loss Pixels to Graphs by Associative Embedding(NIPS 2017) https://arxiv.org/abs/1706.07365

