【泡泡图灵智库】LEGO:一种同时进行边缘提取、深度和法线估计的深度神经网络
泡泡图灵智库,带你精读机器人顶级会议文章
标题:LEGO: Learning Edge with Geometry all at Once by Watching Videos
作者:Zhenheng Yang、 Peng Wang2、Yang Wang、Wei Xu、 Ram Nevatia
来源:arXiv2018
播音员:包子
编译:杨小育
审核:皮燕燕
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——LEGO:一种同时进行边缘提取、深度和法线估计的深度神经网络,该文章发表于arXiv2018。
基于深度卷积神经网络方法,通过学习未经标记的视频序列来估计单幅图像中的3D几何信息引起了学者们的广泛关注。这篇文章提出了3D-ASAP理念,来对边缘和三维场景进行同时估计,从而使得细节部分估计的准确度得到了显著提升。具体来说,3D-ASAP的核心思想是指恢复出来的3D点之间如果没有边缘,则它们应属于同一平面。该论文设计了一个无监督学习网络,来同时对边缘、深度信息和法线进行学习。所估计出来的边缘被应用到深度和法线的估计过程,那些不属于边缘的像素被用来约束该先验。在该算法中,深度估计、法线估计和边缘估计始终关联,可提升算法的预估效果。最后进行该论文进行了实验验证,在KITTI数据集上进行了几何信息估计的实验,在CitySpaces数据集上进行边缘估计实验,实验结果表明该算法优于现有的方法。
主要贡献
1、提出了一个无监督学习框架LEGO(learn edge and geometry all at once),来同时对三维几何信息和边缘信息进行估计,
2、提出3D-ASAP(as smooth as possible in 3D)思想,即恢复出来的3D点之间如果没有边缘则它们应属于同一平面,这样使得几何信息和边信息互相约束,达到很好的估计效果。
算法流程
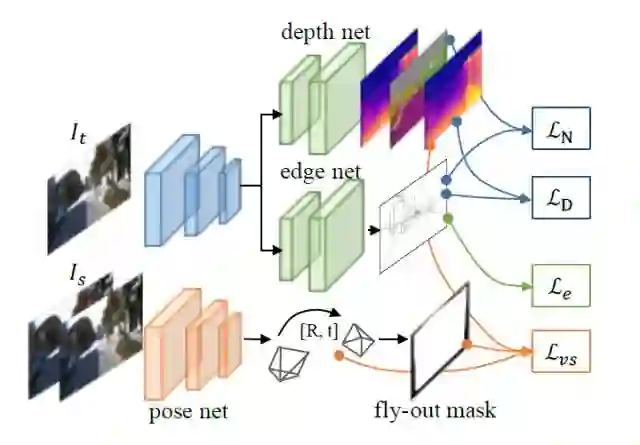
图1:本文的算法框架,视觉合成损失函数Lvs,深度损失函数Ld,边缘损失函数Le,法线损失函数Ln
1.3D-ASAP的思想
假设一:在三维空间中,空间中任意一点应满足公式1,即一条直线上的所有点都属于这条直线所在的平面。
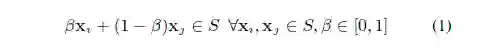
假设二:处于同一个连续的表面上的任意两点,它们的法线应是一样的,所以可以得到法线的算式函数。
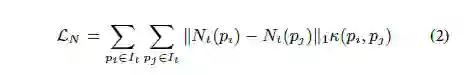
pi和pj是同一连续表面上的点,κ(pi, pj )为一个相似度指数,pi, pj在同一个面上是其值为1,否则为0。
对深度损失函数进行如下的定义:
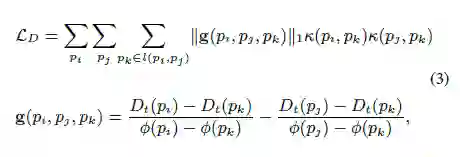
其中K为相机的内参 。
在一幅图像中有大量的像素点需要进行相似度κ(pi, pj )的计算,这是不切实际的,因此需要进行近似处理。对于每一像素点pi,沿着三维空间中的x和y方向寻找其N=1,2,4,8邻域的像素点,最终得到16个相邻像素,这便得到了修正后的公式2和3。
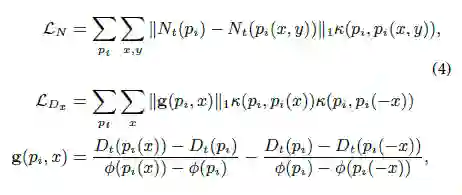
2. 边缘的学习
边缘的损失函数为公式5。
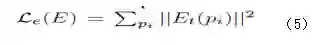
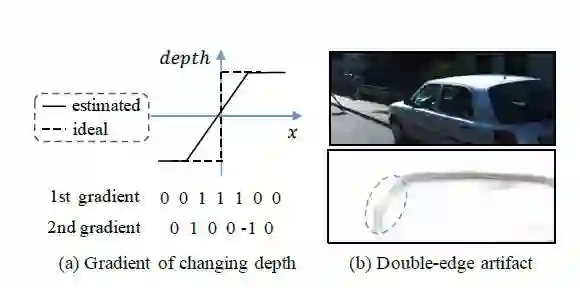
图2 边缘估计存在的双边缘问题
为了解决双边缘的问题,对公式4中的g(pi, ∗)进行如下的修正。
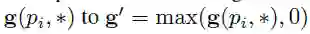
3. 剔除无效的像素点和避免局部渐变

图3 相机从Lt移动到Ls2时,部分场景会超出边界,引起无效的梯度
如图3所示,当相机从Lt移动到Ls2时,部分场景会超出边界,引起无效的梯度,因此需要提前设置蒙版,对这部分像素点进行剔除。
为了避免局部渐变,对上述损失函数进行如下定义,如公式6所示。
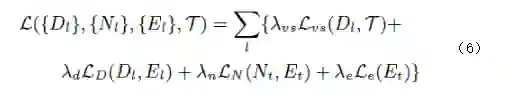
其中λvs, λd, λn, λe 为各个损失函数的权重
主要结果
1.在KITTI数据集上进行了深度估计和法线估计的实验,实验结果过如下图所示。
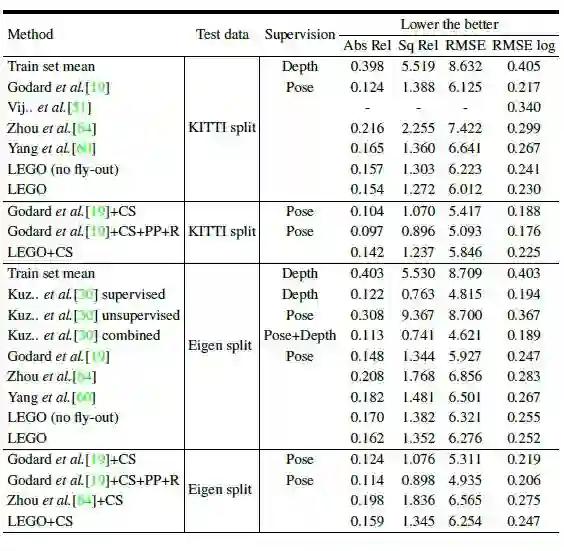
图4 KITTI数据上的深度估计实验结果
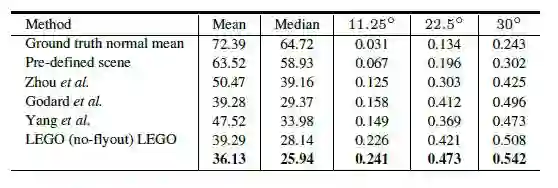
图5 KITTI数据上的法线估计实验结果
2. 在Cityscapes数据集上进行边缘估计实验,实验结果如下图所示
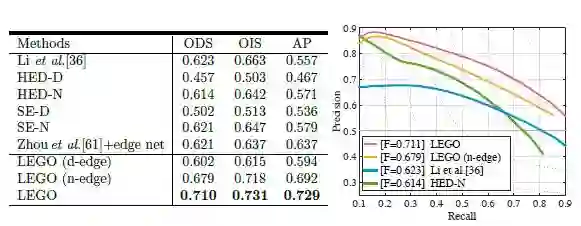
图6 Cityscapes数据集的边缘估计实验结果

Abstract
Learning to estimate 3D geometry in a single image by watching unlabeled videos via deep convolutional network is attracting significant attention. In this paper, we intro-duce a “3D as-smooth-as-possible (3D-ASAP)” prior in-side the pipeline, which enables joint estimation of edges and 3D scene, yielding results with significant improve-ment in accuracy for fine detailed structures. Specifically, we define the 3D-ASAP prior by requiring that any two points recovered in 3D from an image should lie on an ex-isting planar surface if no other cues provided. We design an unsupervised framework that Learns Edges and Geom-etry (depth, normal) all at Once (LEGO). The predicted edges are embedded into depth and surface normal smooth-ness terms, where pixels without edges in-between are con-strained to satisfy the prior. In our framework, the predicted depths, normals and edges are forced to be consistent all the time. We conduct experiments on KITTI to evaluate our es-timated geometry and CityScapes to perform edge evalua-tion. We show that in all of the tasks, i.e.depth, normal and edge, our algorithm vastly outperforms other state-of-the-art (SOTA) algorithms, demonstrating the benefits of our approach.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



