【泡泡图灵智库】多传感器深度连续融合的三维目标检测方法
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Deep Continuous Fusion for Multi-Sensor 3D Object Detection
作者:Ming Liang, Bin Yang,Shenlong Wang and Raquel Urtasun
来源:ECCV 2018
播音员:
编译:张晶
审核:焦阳
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——多传感器深度连续融合的三维目标检测方法,该文章发表于ECCV 2018。
本文提出了一种新的3D目标检测器,它可以利用LIDAR和摄像头进行高精度定位。为了实现这个目标,本文设计了一个端到端的可学习架构,它利用连续卷积在多个尺度下融合图像和LIDAR特征图。本文提出使用连续融合层来编码离散状态的图像特征和连续的几何信息。这使得本文能够设计一种新颖、可靠和高效的基于多传感器的端到端可学习的3D目标检测器。在KITTI和大型3D目标检测基准的实验评价显示出其对现有先进技术的显著改进。
主要贡献
1、提出了一种3D目标检测器,它可以在鸟瞰图(BEV)中进行推理,并通过学习将图像特征投影到BEV空间来进行特征融合。
2、设计了一个端到端的可学习架构,利用连续卷积来融合不同分辨率的图像和LIDAR特征图。
3、提出的连续融合层能够对两种模态下位置间的稠密精确的几何关系进行编码。
算法流程
总体架构包括两个流(图1),一个流提取图像特征,另一个从LIDAR BEV中提取特征。为了实现多传感器多尺度融合,使用连续融合层来桥接两侧的多个中间层,并在BEV空间生成最终检测结果。
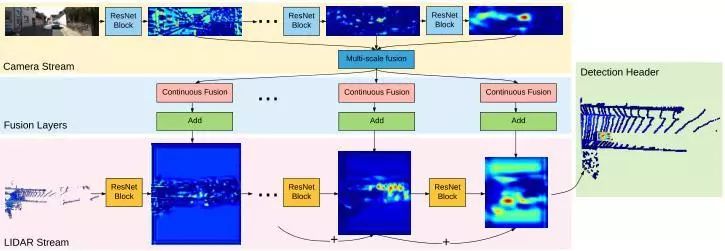
图1 本文模型的架构
1、 连续融合层:在BEV图像上给定目标像素,首先提取K个最近的LIDAR点。然后将3D点投影到相机平面,检索对应的图像特征。最后将图像特征和连续几何偏移输入到多层感知器(MPL)中,以生成目标像素的特征。整个计算过程如图2所示。

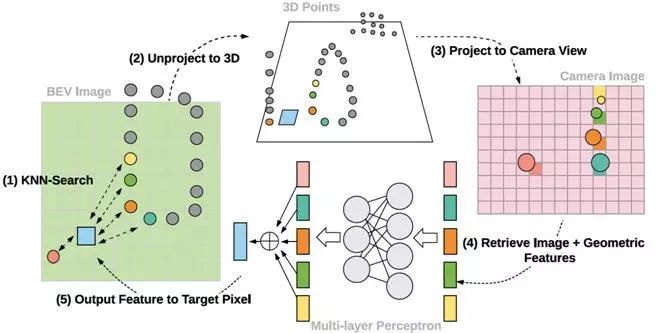
图2 连续融合层
2、 多传感器目标检测网络由图像特征网络和BEV网络组成。骨干网络采用轻量化的ResNet18,使用4个连续融合层将多尺度图像特征融合到BEV网络中。检测结果处每个锚点的输出包括每个像素类的置信度及其相关框的中心位置、大小和方向。基于结果图的非最大抑制(NMS)层用来生成最终目标框。其损失函数定义为分类和回归损失之和。
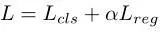
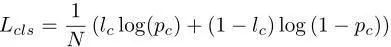
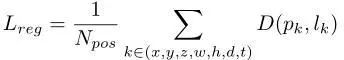
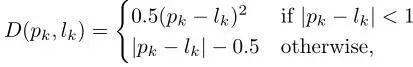
随机选择5%的负锚点(negative anchors),然后根据分类得分仅使用其中的top-k进行训练。使用ImageNet预先训练的权重初始化图像网络,并用Xavier初始化BEV网络和连续融合层。整个网络通过反向传播进行端到端的训练。
主要结果
本文在KITTI和TOR4D数据集上评估其多传感器3D目标检测方法。在KITTI数据集上,与现有的先进方法在3D目标检测和BEV目标检测等方面进行比较,并进行了模型简化测试,对比了不同的模型设计。在TOR4D数据集上,本方法在远距离(>60m)检测中特别有效,这在自动驾驶的时机目标检测系统中起着重要作用。
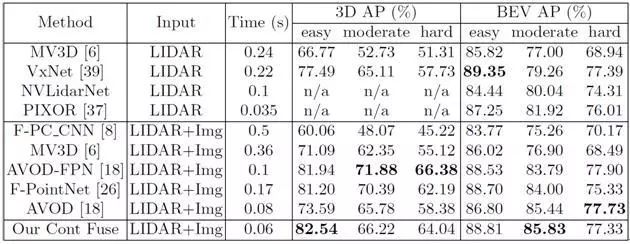
1、对于BEV检测,此模型优于所有其他方法(通过moderate AP测量)。对于3D检测,该模型排第三,但在easy子集下具有最优的AP。在保持高检测精度的同时,该模型能够实时高效运行。检测器以每秒大于15帧的速度运行,比其他基于LIDAR和基于融合的方法快得多。具体比较结果如表1所示。
表1:KITTI 3D和鸟瞰(BEV)目标检测基准上的评估
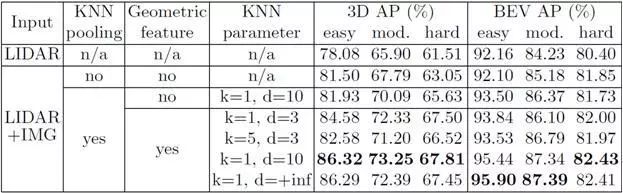
2、连续融合有两个组件,使得图像与LIDAR之间能够稠密精确融合。第一个是KNN polling,它通过稀疏的相邻点来收集稠密BEV像素的图像特征输入。第二个是输入到MLP的几何特征,它补偿两个模态匹配位置对之间的连续偏移。如表2所示,将连续融合模型与仅LIDAR模型(LIDAR输入),稀疏融合模型(无KNN pooling),离散融合模型(无几何特征)进行比较,证明了KNN pooling插值的重要性。
表2 KITTI 3D和鸟瞰(BEV)目标检测基准上的模型简化测试
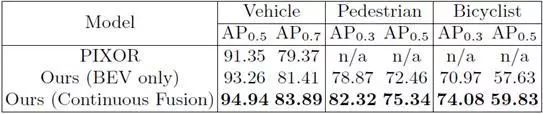
3、在TOR4D数据集上评估多类别BEV目标检测,如表3所示。将连续融合模型与BEV基准以及最近的基于LIDAR检测器的PIXOR进行了比较,其在所有类别上明显优于其他两种基于LIDAR的方法。
表3 TOR4D数据集上多类别BEV目标检测的评估
通过对以上三个类别计算基于距离的piecewise AP(图3),说明连续融合模型在远程检测中能获得更多增益。
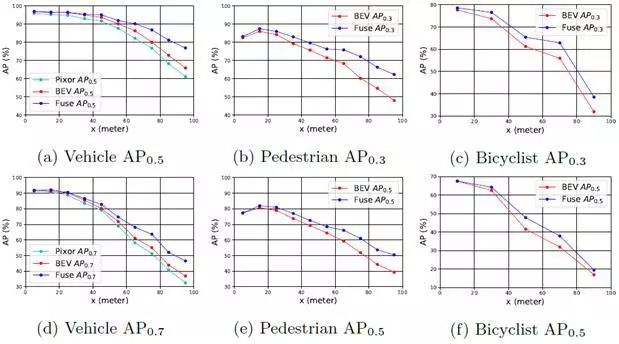
图3 TOR4D数据集上多类别DEV对象检测的Piecewise AP
4、KITTI上的定性检测结果如图4所示。即便是在汽车很远或者严重遮挡的场景,该模型也能很好地检测到汽车。

图4 KITTI数据集上的定性结果。BEV上对象的边界框和图像以相同的颜色显示
5、图5显示了TOR4D数据集上的多类别定性结果,展示出本方法具有出色的可扩展性以及在远距离检测中的卓越性能。

图5 TOR4D数据集上的多类别定性结果

Abstract
In this paper, we propose a novel 3D object detector that can exploit both LIDAR as well as cameras to perform very accurate localization. Towards this goal, we design an end-to-end learnable architecture that exploits continuous convolutions to fuse image and LIDAR feature maps at different levels of resolution. Our proposed continuous fusion layer encode both discrete-state image features as well as continuous geometric information. This enables us to design a novel, reliable and efficient end-to-end learnable 3D object detector based on multiple sensors. Our experimental evaluation on both KITTI as well as a large scale 3D object detection benchmark shows significant improvements over the state of the art.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



