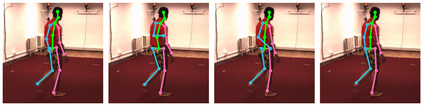
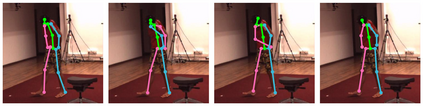
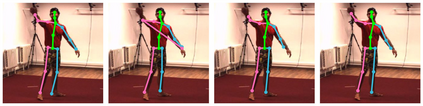
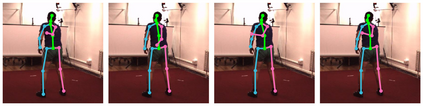
Cross view feature fusion is the key to address the occlusion problem in human pose estimation. The current fusion methods need to train a separate model for every pair of cameras making them difficult to scale. In this work, we introduce MetaFuse, a pre-trained fusion model learned from a large number of cameras in the Panoptic dataset. The model can be efficiently adapted or finetuned for a new pair of cameras using a small number of labeled images. The strong adaptation power of MetaFuse is due in large part to the proposed factorization of the original fusion model into two parts (1) a generic fusion model shared by all cameras, and (2) lightweight camera-dependent transformations. Furthermore, the generic model is learned from many cameras by a meta-learning style algorithm to maximize its adaptation capability to various camera poses. We observe in experiments that MetaFuse finetuned on the public datasets outperforms the state-of-the-arts by a large margin which validates its value in practice.
翻译:交叉视图特征聚合是解决人类表面估计中的封闭问题的关键。 当前的聚合方法需要为每对照相机培养一个单独的模型, 使其难以缩放。 在这项工作中, 我们引入了MetaFuse, 这是在全光数据集中从大量照相机中学习的预先训练的聚合模型。 这个模型可以用少量标签图像对一对新的照相机进行高效的改造或微调。 MetaFuse 的强大适应能力在很大程度上是由于将最初的聚合模型分为两部分 (1) 一个由所有照相机共享的通用聚合模型, (2) 轻量相机依赖变形。 此外, 通用模型是通过一个元化学习式的算法从许多照相机中学习的, 以最大限度地使其适应各种照相机的配置能力。 我们在实验中观察到, MetaFuse对公共数据集的微调超越了在实际中证实其价值的优势。