【泡泡图灵智库】基于几何一致性网络的摄像机运动估计
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Geometric Correspondence Network for Camera Motion Estimation
作者:Jiexiong Tang John Folkesson Patric Jensfelt
来源:IEEE ROBOTICS AND AUTOMATION LETTERS
编译:万应才
审核:李雨昊
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——Geometric Correspondence Network for Camera Motion Estimation,该文章发表于IEEE ROBOTICS AND AUTOMATION LETTERS 2018。
本文提出了一种新的用于视觉里程测量的几何对应生成学习方案。将卷积神经网络(CNN)与循环神经网络(RNN)相结合训练,在一个统一的结构中检测关键点的位置并生成相应的描述符。通过刚体变换,将点从源帧映射到参考帧,对网络进行优化。从本质上讲,学习wrap。整个训练的重点是相机的运动,而不是图像中的运动,这将使匹配的一致性更好,最终更好的运动估计。实验结果表明,该方法比相关的深度学习方法和手工方法都有更好的效果。此外,为了证明我们方法的前景,我们使用了基于这些关键点的简单slam实现,并获得了与orb-slam相同的性能。
主要贡献
本文主要贡献是一个框架(GCN),用于同时学习针对摄像机运动估计任务优化的特征位置(用于运动估计)和描述符(用于匹配)。
算法流程
本文主要研究视觉里程测量(VO),即利用视觉传感器的信息进行帧间运动估计。研究了使用深度神经网络,以端到端的方式学习如何同时检测关键点以及如何使用RGB-D传感器匹配它们。我们只针对几何对应而不是语义对应进行优化。将卷积神经网络(CNN)和循环神经网络(RNN)训练在一个统一的结构中进行关键点检测和特征描述符生成,称之为几何对应网络(GCN)。为了训练网络,提取一幅图像中的高梯度点,并使用相机运动将其wrap到下一幅图像。

图1 使用我们提出的方法GCN,使用帧到帧相机运动估计(即,不使用关键帧和循环闭合)累积的RGB-D帧,用于关键点生成和匹配。数据是由一架绕着房间飞行的六架飞机上的RGB-D传感器收集的。
1.整体结构
GCN的整体网络结构如下图所示。一个深CNN的输出反馈到一个浅循环网络,以执行密集特征提取和关键点检测。众所周知,用于估计刚体变换的好点是图像中水平和垂直方向的高梯度点。因此,我们使用来自关键点探测器而非随机点的输入进行训练。然而,不能保证相同的关键点会出现在两幅图像中,尽管是连续的。为了在训练过程中解决这个问题,首先提取第一幅图像中的关键点,并使用已知的帧到帧转换将其弯曲到下一帧。通过这种方法,我们对网络进行了优化,在这种情况下,可以通过用刚体变换来弯曲点,而不是通过它们在第二帧中的外观来找到点的对应关系。该方法不匹配两幅图像中具有相似外观但实际上不是几何点的点,例如在不同深度相交边缘形成的线。
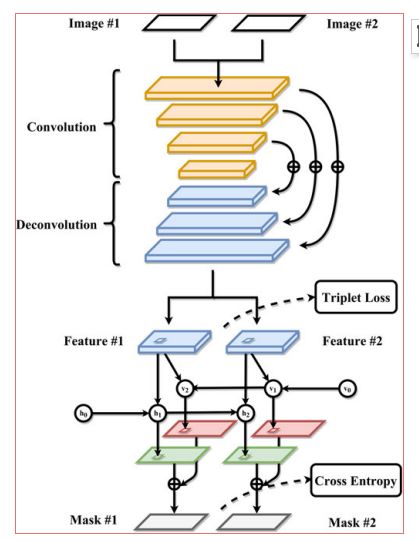
图2 GCN的整体学习方案和数据流以颜色表示不同的块。
上半部分是CNN,它提取特征以密集的方式。它包括用于多尺度特征表示的全卷积部分和用于细节细化的反卷积部分。下半部分是一个浅双向递归结构,用于预测两幅图像中关键点的位置。请注意,实际网络的隐藏层比绘制的要多。训练的目标函数分别是(5)和(9)中定义的三重损失和交叉熵。
2.稠密的特征点提取
通过ResNet50编码解码提取稠密特征点,并对此进行编码。用一个矩阵形式表示。
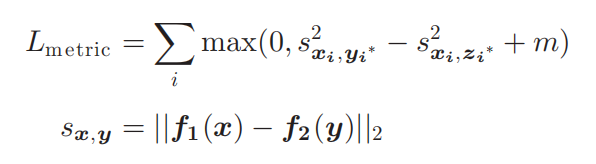
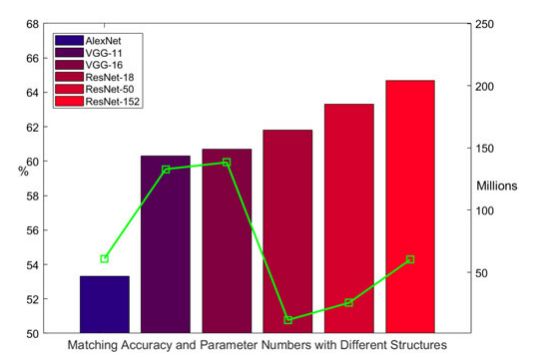
图3 对比使用Kitti Raw[44]道路场景的不同结构,我们使用序列[1、2、5、9]进行培训,并在本测试中使用[11、13]进行测试。条形图表示总体匹配精度,显示在左垂直轴上,绿点表示参数个数,显示在右垂直轴上。
3.Recurrent Mask Prediction
我们将关键点检测看作是一个以密集特征为输入的二值分类问题。为了同时预测两个输入图像的关键点位置,我们希望网络利用时间信息和空间信息。我们使用一个浅双向循环卷积网络(RCNN)来实现这一目标。关键点分类的目标是每个像素带有标签0或1的标记,以指示它是否为关键点。标记是通过给第一个图像中的关键点一个值1并将其扭曲到下一个图像来生成的。
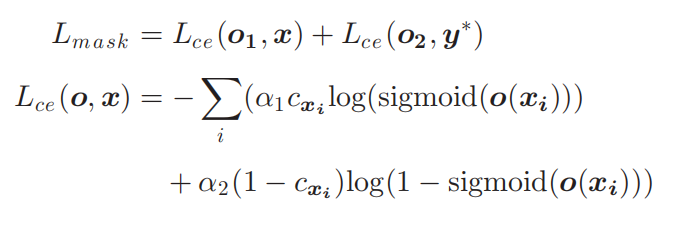

图3 使用GCN对TUM数据集进行关键点预测的示例[1]。这两个彩色图像是GCN的输入。在每一行中,这两列分别是原始的RGB图像和预测。对于地面实况,将丢弃图像边界之外没有深度或扭曲点的点
4.Multi-Task Training
最后要对Lmetric和Lmask进行联合训练。联合估计得权重是随机初始化的,除了resnet-50。特征向量的长度设置为64。使用更高的在我们的测试中,维特征向量很小,较短的特征向量导致训练不收敛。正如在微调中通常所做的,resnet-50的学习速率被设置为较小的随机初始化权重(在我们的例子中是10-4和10-3)。
主要结果
我们使用TUM的RGB-D和Kitti RAW基准评估框架的有效性。第一个实验将证明与使用相同帧到帧运动估计管道的其他特征相比,用于运动估计的特征的质量。第二个测试将证明GCN在未知场景下的泛化能力和与其他深度学习方法相比的性能。最后一个测试将为基于RGB-D的运动估计提供与现有和端到端解决方案的比较,以便对该任务的性能进行定量评估。
1. KITTI Raw上点云重建

图5 原始点云重建使用fr1-floor 和fr3-long。详情可查阅:www.cas.kth.se/gcn。
2.无闭环运动估计的估值
表II显示了使用每个序列的前200帧进行帧到帧跟踪的ATE。
与其他方法相比,GCN在所有序列上都达到了最佳性能。尤其是在场景fr3-nnf中,一种纹理很弱的墙,在这种墙中,GCN仍然能够产生可跟踪的特征,而其他的则无法跟踪。
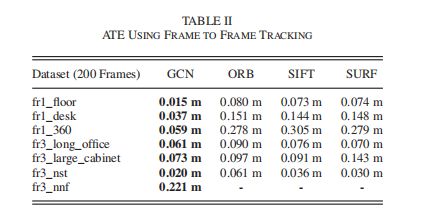
表2 使用帧到帧跟踪的ATE
3. 在数据集上回环检测效果
使用数据集中所有帧的ATE如表V所示,图5显示了两个原始点云重建示例。与其他方法相比,我们的方法获得了有竞争力的结果。

表4 Kitti原始数据的平均角度偏差和平移偏差
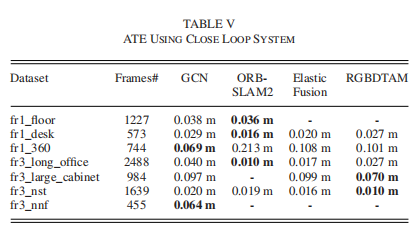
表5 使用闭环系统的ATE
Abstract
In this paper, we propose a new learning scheme for generating geometric correspondences to be used for visual odometry. A convolutional neural network (CNN) combined with a recurrent neural network RNN) are trained together to detect the location of keypoints as well as to generate corresponding descriptors in one unifified structure. The network is optimized by warping points from source frame to reference frame, with a rigid body transform. Essentially, learning from warping. The overall training is focused on movements of the camera rather than movements within the image, which leads to better consistency in the matching and ultimately better motion estimation. Experimental results show that the proposed method achieves better results than both related deep learning and hand crafted methods. Furthermore, as a demonstration of the promise of our method we use a naive SLAM implementation based on these keypoints and get a performance on par with ORB-SLAM.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




