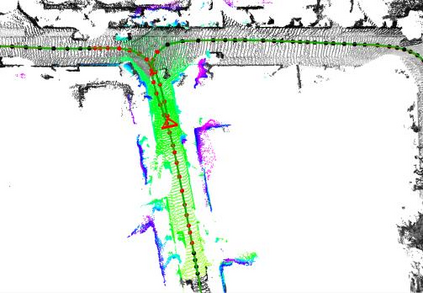
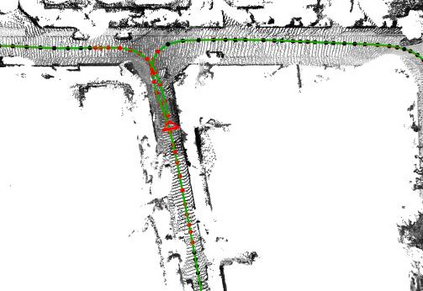
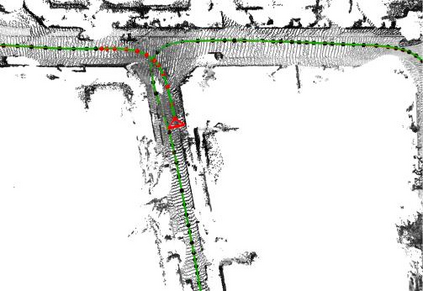
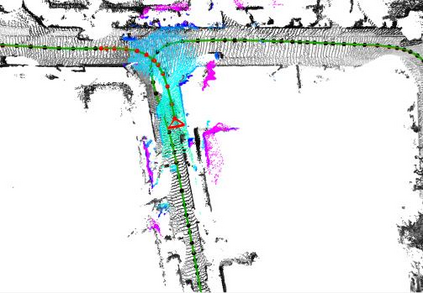
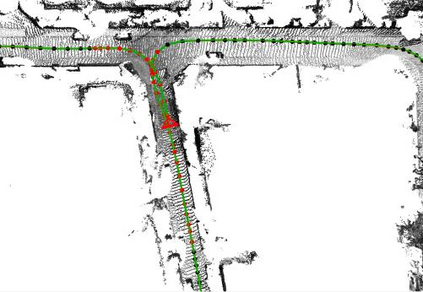
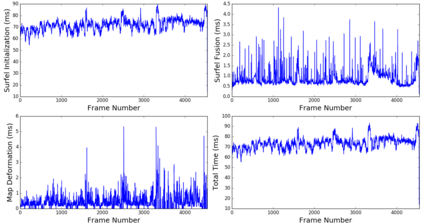
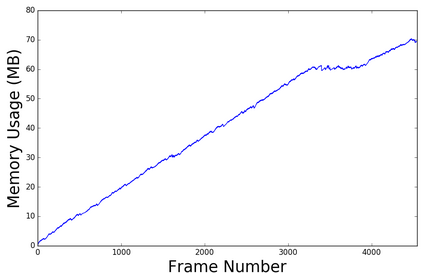
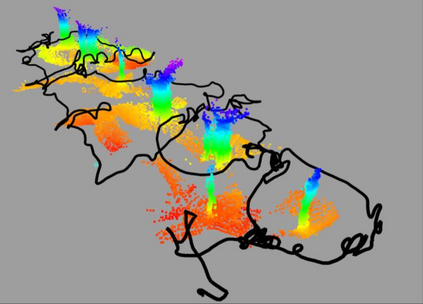
In this paper, we propose a novel dense surfel mapping system that scales well in different environments with only CPU computation. Using a sparse SLAM system to estimate camera poses, the proposed mapping system can fuse intensity images and depth images into a globally consistent model. The system is carefully designed so that it can build from room-scale environments to urban-scale environments using depth images from RGB-D cameras, stereo cameras or even a monocular camera. First, superpixels extracted from both intensity and depth images are used to model surfels in the system. superpixel-based surfels make our method both run-time efficient and memory efficient. Second, surfels are further organized according to the pose graph of the SLAM system to achieve $O(1)$ fusion time regardless of the scale of reconstructed models. Third, a fast map deformation using the optimized pose graph enables the map to achieve global consistency in real-time. The proposed surfel mapping system is compared with other state-of-the-art methods on synthetic datasets. The performances of urban-scale and room-scale reconstruction are demonstrated using the KITTI dataset and autonomous aggressive flights, respectively. The code is available for the benefit of the community.
翻译:在本文中,我们提出一个新的密度浓厚的冲浪成像系统,在不同环境中进行大比例测量,只有CPU计算。使用稀疏的 SLAM 系统来估计摄像头配置,拟议的绘图系统可以将强度图像和深度图像整合成一个全球一致的模式。这个系统经过仔细设计,以便利用RGB-D相机、立体相机甚至单摄像头的深度图像,从室内规模环境到城市规模的环境。首先,从强度和深度图像中提取的超级像素用于模拟系统中的冲浪。超级像素冲浪器使我们的方法在运行时效率高,记忆效率高。第二,冲浪机进一步按照SLAM系统的配置图进行组织,以达到1美元(无论重建模型的规模如何)的聚变时间。第三,使用最优化的造型图的快速变形图使地图能够实现实时的全球一致性。拟议的冲浪成像系统与其他最先进的合成数据集方法进行比较。使用KITTI数据集和自主的飞行分别展示了城市规模和房间规模重建的性能。