©作者 | 清华大学、DeepMind等
来源 | 机器之心
以 GPT-3 为代表的预训练语言模型的发展,引发对小样本自然语言理解任务的极大关注。各种方法不断发展并展现出日渐强大的小样本自然语言理解性能。然而,来自清华大学、DeepMind 等团队的研究者近期的一项研究指出:相同基准再评估结果表明,现有小样本学习方法并不足够稳定有效,小样本自然语言理解发展尚面临巨大挑战!
评价准则的差异极大阻碍了已有小样本学习方法基于统一的标准公平比较,也无法客观评价该领域的真实进展。近期,来自清华大学、DeepMind 等团队研究者在论文《FewNLU: Benchmarking State-of-the-Art Methods for Few-Shot Natural Language Understanding》中指出:现有小样本学习方法并不稳定有效,且目前已有工作不存在单一的小样本学习方法能够在大多数 NLU 任务上取得优势性能。小样本自然语言理解领域发展依然面临着严峻的挑战!该工作被 ACL 2022 主会接收。
![]()
论文标题:
FewNLU: Benchmarking State-of-the-Art Methods for Few-Shot Natural Language Understanding
https://arxiv.org/abs/2109.12742
https://github.com/THUDM/FewNLU
https://fewnlu.github.io/
1. 该研究提出了一个新的小样本自然语言理解评价框架 FewNLU,并且从三个关键方面(即测试集小样本学习性能、测试集和验证集相关性、以及稳定性) 量化评估该评价准则的优势;
2. 研究者对该领域相关工作进行重新评估,结果表明:已有工作未准确估计现有小样本学习方法的绝对性能和相对差距;目前尚不存在单一在大多数 NLU 任务取得优势性能的方法;不同方法的增益是优势互补的,最佳组合模型的性能接近于全监督 NLU 系统等关键结论;
3. 此外本文提出 FewNLU,并构建了 Leaderboard,希望帮助促进小样本自然语言理解领域未来研究工作的发展。
![]()
小样本自然语言理解评价框架
初步实验结果表明(如表格 1 所示),就如已有大多数工作那样基于一组(根据既往实验经验)预先固定的超参数的实验设置,并不是最佳选择。实验条件的细微变化或者扰动都会带来性能的急剧波动。基于小的验证集在不同实验中分别进行模型选择是不可或缺的。
基于上述结论,本文为小样本自然语言理解提出一种更稳健且有效的评价框架,如算法 1 所示。
该评价框架中有两个关键设计选择,分别是如何构建数据拆分以及确定关键搜索超参数。
本文首先提出数据拆分构建的三个关键指标:(1) 最终测试集小样本学习性能、 (2) 测试集和验证集关于一个超参数空间分布的相关性、以及 (3) 关于实验执行次数的稳定性。
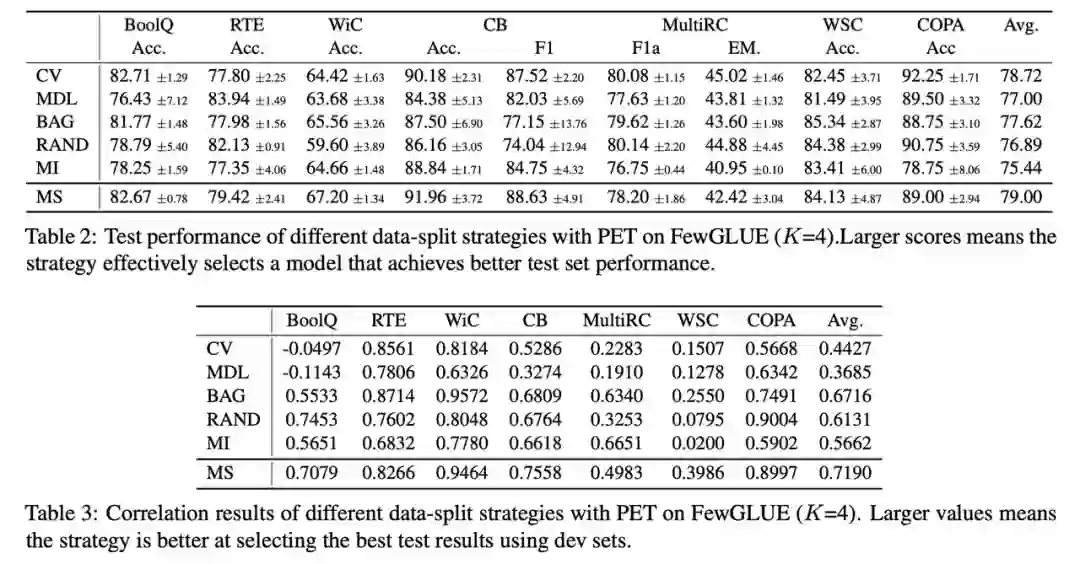
基于此,本文对多种不同的数据拆分策略进行了量化实验和讨论,包括 (1) K 折交叉验证 (K-Fold CV)[2], (2) 最短描述距离(MDL)[2],(3) Bagging [9], (4) 随机采样策略 (5) 模型指导的拆分策略 (6) 以及本文提出的多次数据划分(Multi-Splits)。
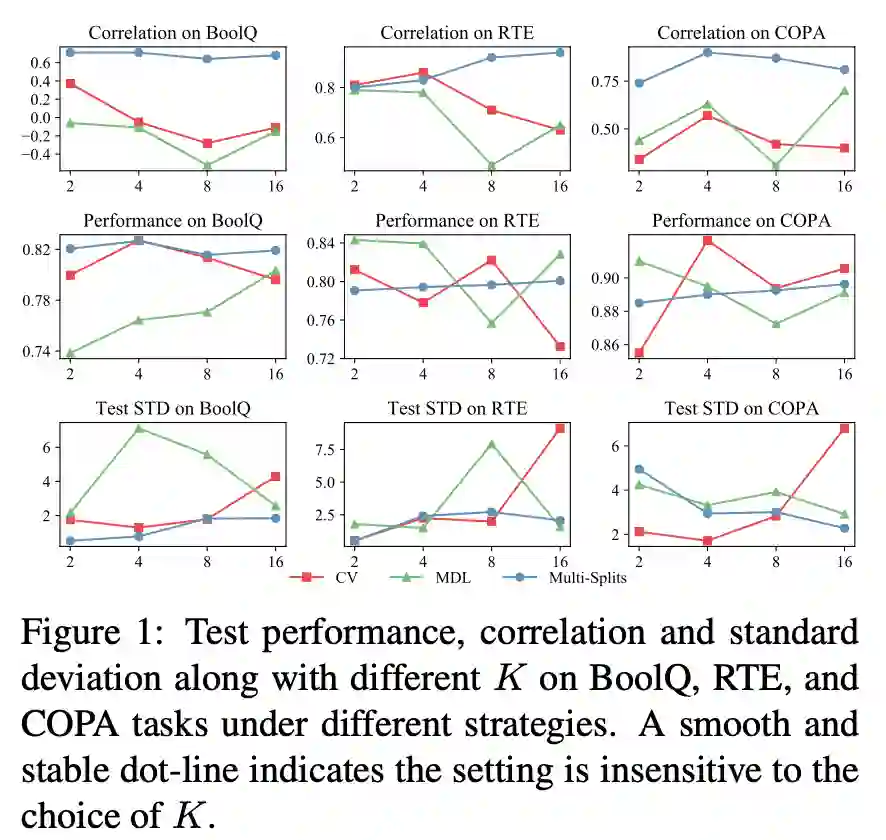
实验结果如表格 2、3 和图 1 所示。表格 2、3 的实验结果表明:从小样本性能和相关性看,多次数据划分 (Multi-Splits) 是比其他几个基准方案更好的数据拆分策略。
此外,由图 1 可知,Multi-Splits 的优势还源于增大执行次数 K 的取值并不会对训练集和验证集的数据量产生影响,相反会进一步增加该结果的置信度,故实验过程中总可以选择尽可能增大 K 的取值。然而对于 CV 和 MDL,较大的 K 值会导致失败 (Failure Mode),较小的 K 值导致高随机性不稳定的结果;同时在实践中很难先验地知道应该如何取值。故 Multi-Splits 是更具实际使用意义的数据拆分策略。
![]()
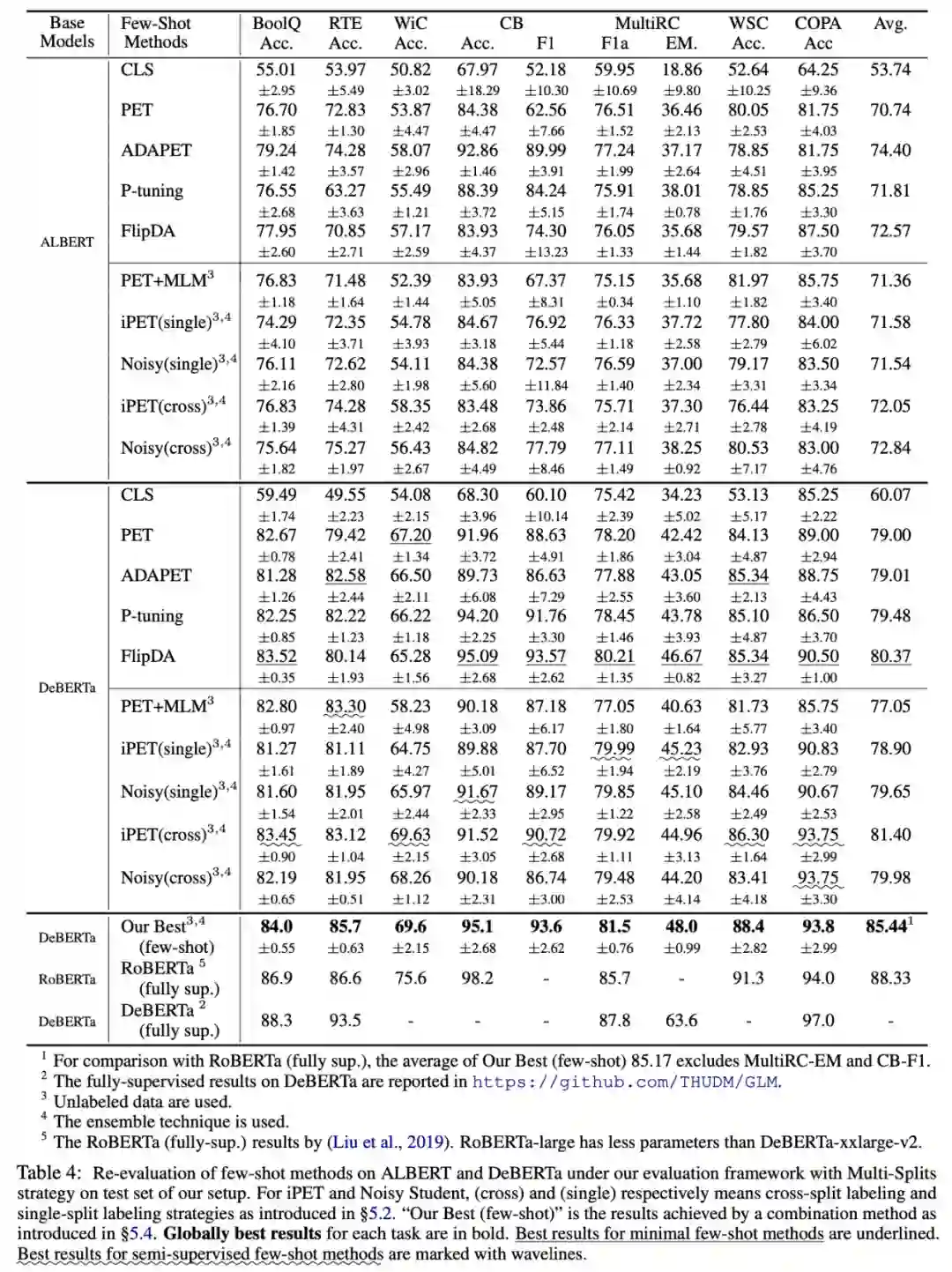
基于统一的评价框架下,本文对目前已有最先进的小样本学习方法进行重新评价。本文还尝试探索了多种不同小样本学习方法和技术组合可以实现的最佳性能(如表格 5 中的 "Our Best" 所示)。重新评价实验结果如表格所示。
结论 1:小样本学习方法的绝对性能和相对性能差异,在先前文献中未被准确估计。
此外小样本方法(例如 ADAPET)在像 DeBERTa 这样的大型模型上的优势会显著降低。
半监督小样本方法(例如 iPET 和 Noisy Student)增益在较大的模型也可以保持一致性。
结论 2:不同小样本学习方法的增益在很大程度上是互补的。
通过将目前各种先进方法加以组合,它们可以在很大程度上实现优于任意单一方法的小样本学习性能。
目前最佳组合方法的小样本学习性能,接近 RoBERTa 上实现的全监督性能;
然而和目前 DeBERTa 上实现的最优全监督性能相比,它仍然存在较大的差异性。
结论 3:目前已有相关工作中不存在单一的小样本学习方法能够在大多数 NLU 任务上取得主导性优势性能。
这为未来进一步开发出具有跨任务一致性和鲁棒性的小样本学习方法提出新的挑战。
[1] Timo Schick and Hinrich Schütze. 2021b. It’s not just size that matters: Small language models are also few-shot learners. pages 2339–2352.
[2] Ethan Perez, Douwe Kiela, and Kyunghyun Cho. 2021. True few-shot learning with language models. CoRR, abs/2105.11447.
[3] Rakesh R. Menon, Mohit Bansal, Shashank Srivastava, and Colin Raffel. 2021. Improving and simplifying pattern exploiting training. CoRR, abs/2103.11955.
[4] Timo Schick and Hinrich Schütze. 2021a. Exploiting cloze-questions for few-shot text classification and natural language inference. In EACL, pages 255–269. Association for Computational Linguistics.
[5] Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. 2021b. GPT understands, too. CoRR, abs/2103.10385.
[6] Qizhe Xie, Minh-Thang Luong, Eduard H. Hovy, and Quoc V. Le. 2020. Self-training with noisy student improves imagenet classification. In CVPR, pages 10684-10695. IEEE.
[7] Tianyu Gao, Adam Fisch, and Danqi Chen. 2020. Making pre-trained language models better few-shot learners. CoRR, abs/2012.15723.
[8] Tianyi Zhang, Felix Wu, Arzoo Katiyar, Kilian Q. Weinberger, and Yoav Artzi. 2020. Revisiting few-sample BERT fine-tuning. CoRR, abs/2006.05987.
[9] Leo Breiman. 1996. Bagging predictors. Mach. Learn., 24(2):123–140.
![]()
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()