有效且稳健的数据增强小样本学习 | 论文荐读
论文标题:
FlipDA: Effective and Robust Data Augmentation for Few-Shot Learning (ACL'22)
作者:
Jing Zhou*, Yanan Zheng*, Jie Tang, Jian Li, and Zhilin Yang
论文链接:
https://arxiv.org/abs/2108.06332
论文代码和数据:
https://github.com/zhouj8553/FlipDA
数据增强在图像识别等诸多领域被证明是行之有效的提升性能的方式,也是普遍用于提升小样本学习性能的方式。然而大多数以前的文本数据增强的方法存在严重缺陷:(1)对于包括替换、插入、删除等基本操作在内的大多数数据增强方法只能带来极少的边际收益,并且对于大多数的任务不奏效;(2)其次在很多情况下,使用数据增强方法进行小样本学习的性能非常不稳定,甚至进入故障模式(Failure Mode),即小样本学习的性能会因使用预训练模型以及执行任务的不同,而产生严重下降或者波动。这些缺陷都导致已有数据增强的方法无法在小样本学习的任务中实际使用。
为了应对这一挑战,我们在一种更加严苛的设定下,即困难任务的数据增强(即小样本自然语言理解)和强基线(即具有超过一个亿参数的预训练模型),提出了一种新的数据增强方法 FlipDA,它联合使用生成模型和分类器来生成标签翻转数据。FlipDA 关键是发现了生成标签翻转(Label-Flipped)数据对性能提升更重要而不是生成标签保留(Label-Preserved)的数据。FlipDA 实现了有效性和稳健性之间的良好折衷——它大大提高了许多任务的性能,同时不会对其他任务产生负面影响。
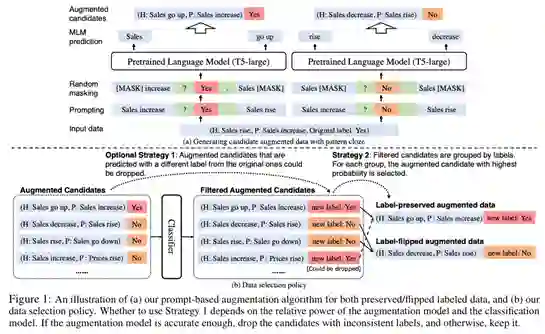
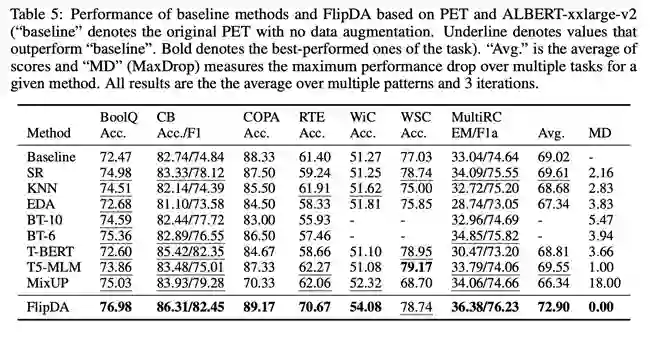
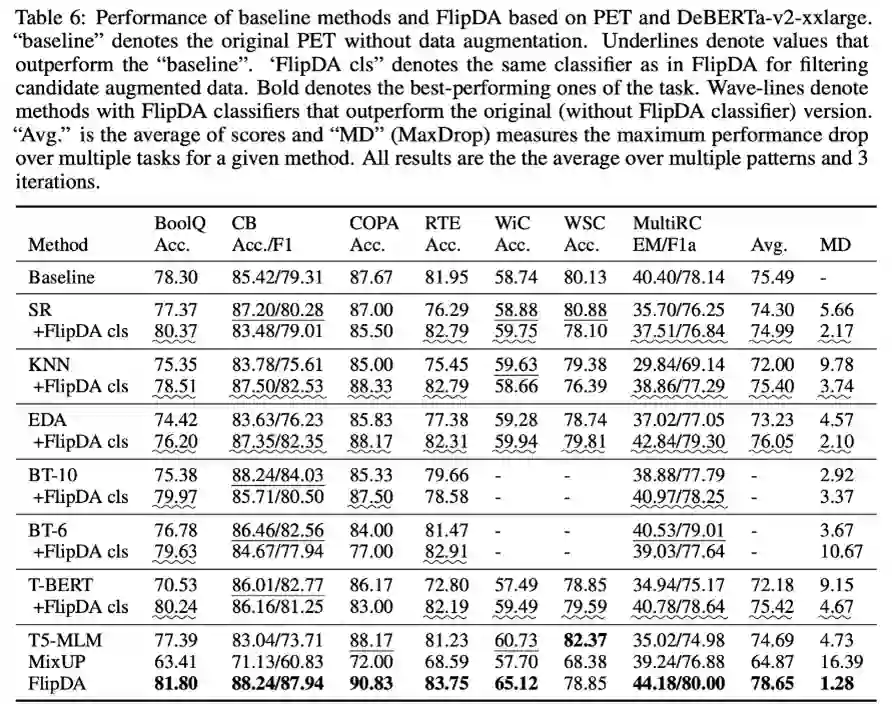
我们在包含大量困难小样本自然语言理解任务的基准数据集 SuperGLUE、以及不同规模的预训练模型(ALBERT和DeBERTa)上进行了大量实验。实验结果表明,相较于已有最优数据扩增方法,FlipDA 的平均性能有了显著提升;此外 FlipDA 在不同的预训练模型和不同任务中都表现出显著鲁棒性,避免了故障模式。
点击【阅读原文】查看paper





