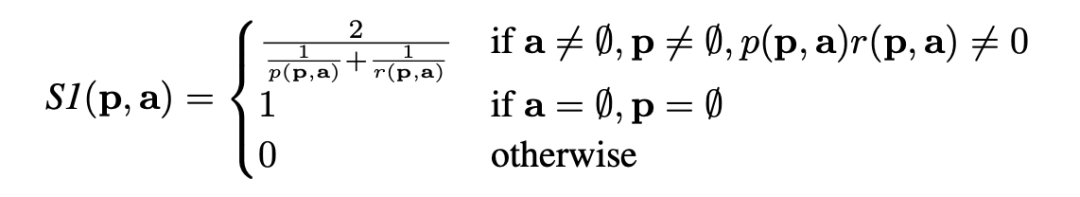![]()
©作者 | 雪麓
单位 | 北京邮电大学
研究方向 | 序列标注
自然语言理解 (NLU) 的最新进展部分是由 GLUE、SuperGLUE、SQuAD 等基准驱动的。事实上,许多 NLU 模型现在在这些 benchmark 中的许多任务上已经达到或超过了“人类水平”的性能。然而,这些 benchmark 中的大多数都允许模型访问相对大量的标记数据以进行训练。因此,模型提供的数据远多于人类实现强大性能所需的数据。这激发了一系列专注于提高 NLU 模型的少样本学习性能的工作。然而,由于少样本 NLU 缺乏标准化的评估 benchmark,导致不同论文中的实验设置不同。
本文作者证明,虽然最近的模型在访问大量标记数据时达到了人类的表现,但在大多数任务的少样本设置中,性能存在巨大差距。作者还在少样本设置中展示了可选的模型系列和适应技术之间的差异。最后,作者讨论了设计用于评估“真实” few-shot 学习性能的实验设置的几个原则和选择,并提出了一种统一的标准化方法来进行 few-shot 学习评估。作者的目标是鼓励大家对于能够使用少量样本就能泛化到新任务的 NLU 模型研究。
论文标题:
CLUES: Few-Shot Learning Evaluation in Natural Language Understanding
https://arxiv.org/pdf/2111.02570.pdf
https://github.com/microsoft/CLUES
Introduction
benchmark 为研究人员提供了明确定义的挑战和明确的指标,并推动了自然语言理解 (NLU) 的重大进展。事实上,最近的几个 benchmark,如 GLUE 和 SuperGLUE 已经清楚地表明,许多当前的大型模型可以在这些 benchmark 中可以相比或超过 NLU 任务的“人类水平”性能。
但当前的 NLU benchmarks 有很大的局限性。首先,任务通常仅限于那些可以很容易地表示为分类任务的任务。其次,也是最重要的,在大多数这些 benchmark 中,给定大量特定于任务的标记训练数据,有些模型可以相比或超过“人类水平”的表现。相比之下,人类只需几次演示就可以执行复杂的任务。这些限制严重破坏了在 NLU 任务上实现广泛的人类水平表现的主张。在这方面,CLUES benchmark 通过给出一些跨不同任务的训练示例提供了一个公平的设置来比较机器和人类的表现。
创建此 benchmark 的目标之一是创建一种标准化方法来评估 NLU 任务的少样本学习方法。现在出现了各种各样的 NLU 任务方法;许多方法依赖于大型的预训练自编码、自回归和 seq2seq 模型。为了适应不同的模型类型和句子分类之外的更广泛的任务集,作者将 CLUES 中的所有任务(包括句子分类任务)作为“sets of spans”提取任务;其中模型输出一组文本 span。这使我们能够为基准中包含的多个任务(例如句子分类、问答和命名实体识别)提供一种新颖的统一度量标准。
在 CLUES benchmark 中包含任务的关键标准之一是人类和机器性能之间存在明显差距。作者提供了所有任务的人类和机器性能结果。人工评估表明,当仅给出少数标记示例甚至是在仅给出任务描述的零样本设置时,人们能够以高水平的性能执行所有任务。
为了评估机器性能,作者考虑了一系列模型架构、一系列模型大小以及一组可选的适应技术。适应技术包括经典的全模型 fine-tuning、新颖的特定任务 prompt-tuning 和 GPT-3 情况下的上下文学习。虽然出现了一些有趣的性能模式,但关键结果是当前模型与 CLUES 基准中任务的人类水平性能之间存在显著差距,这突出表明需要研究改进 NLU 任务的小样本学习。作者希望这种基准将鼓励 NLU 研究方法,这些方法可以通过少量示例学习和泛化到新任务。
CLUES
作者尝试对不同的少样本学习方法提供标准化的评估,并证明人类和机器在 NLU 任务的少样本学习性能方面存在显著差距。作者的目标是促进在弥合这一差距方面取得进展。特别是,CLUES 旨在评估少样本设置中跨不同 NLU 任务的通用模型。值得注意的是,作者没有解决其他研究的主题的多任务或跨任务少样本学习。
2.1 Benchmark Composition
对于每种任务
,包含一个自然语言任务描述
,带有不同数量训练样本的训练集
,以及一个测试集
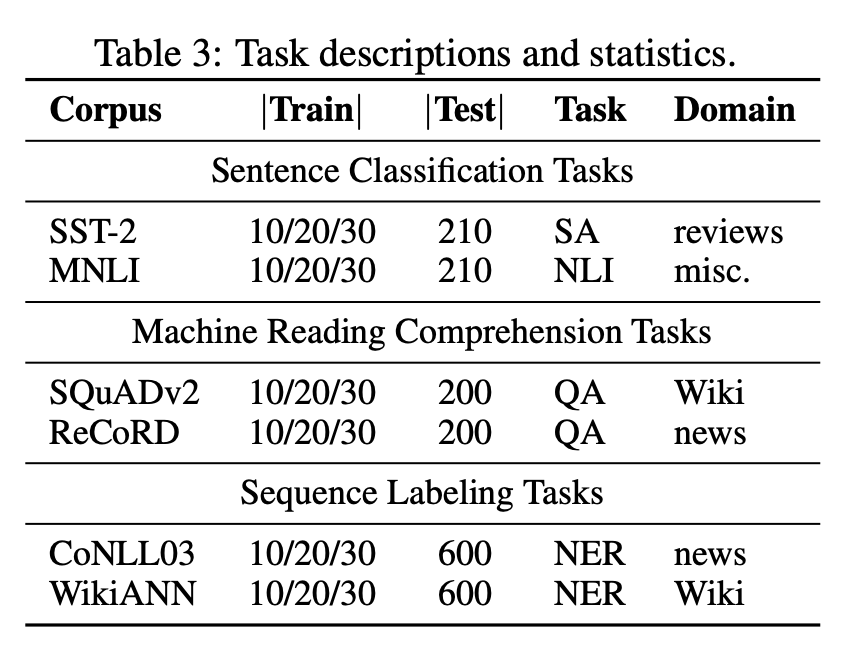
。每个训练样本包括一段自然语言文本,一个自然语言问题以及可以为空的一系列候选答案(span)。在实验中每个任务的训练样本为 30,当然也可以执行 10-shot 20-shot 的设置。
![]()
作者将这组任务分为三个不同的类别,即分类、序列标记和机器阅读理解,以涵盖广泛的 NLU 场景。作者通过将它们视为“span 提取”问题,进一步将所有这些任务统一为单一格式。
对于分类,作者同时关注句子分类和句子对分类;与实例级分类任务相反,序列标注由于专注于 token 级分类和不同 token 之间的依赖关系而更具挑战性。作者考虑了 NER 任务;最后,作为任务的第三个子类,作者考虑机器阅读理解(MRC)。MRC 任务需要机器根据给定的上下文回答问题。考虑到自然语言理解和(常识)知识推理的要求,这是一项具有挑战性的任务。
遵循表 2 中的任务制定原则,接下来描述作者如何从可用数据集中采样和修改示例以形成我们的基准。
Unifying NLU Tasks with a Single Format
预训练的语言模型通过在编码器顶部添加特定于任务的预测层,利用单个基础编码器来执行所有任务。这需要针对不同任务格式的不同预测层,例如,用于问答和其他 MRC 任务的 span 解码器,以及用于文本分类任务的分类层。这进一步需要针对不同任务的不同训练策略。
为了应对这些挑战,作者将所有任务格式统一为给定问题和上下文作为输入的一组 span 提取任务,其中该集合也可能为空。span 将从上下文或问题中提取。虽然像 MNLI 或 SQuAD 这样的大多数任务都有唯一的跨度(即大小为 1 的集合)作为答案,但其他像 CoNLL03 这样的任务也可以有一个空集或一组超过 1 个元素的集作为答案。
Sampling of Training and Test Data
在这个 benchmark 中,作者对少样本学习能力感兴趣,因此我们只需要足够的数据来可靠地估计它们的性能。为此,作者为每个任务使用现有的数据集,并使用带标签的样本来适应设置。
值得注意的是,为了为这个基准建立一个真正的小样本学习设置,我们不包括任何任务的单独验证集。这是为了防止用户使用验证集进行训练,这会极大地改变可用监督和模型性能的数量 ,并相应地使不同模型的比较变得困难。
鉴于大型预训练模型在不同随机种子和训练示例的小样本设置中的性能差异很大,我们为满足上述子集包含标准的每个样本提供五个不同的训练分割。
Other sampling strategies
除了随机抽样,作者还考虑通过对抗性扰动上下文/提示或通过选择与参考模型(例如 BERT 或 RoBERTa)相关的难题来创建更困难的任务版本。然而,作者没有采用这些方法,原因如下:
1)我们观察到,来自这种对抗方法的扰动示例通常是不自然的,人类无法阅读。
2)对抗性扰动和选择都需要参考模型,这违反了我们在表中的模型不可知任务制定原则。
因为作者将所有任务统一为 span 提取,因此作者设计了一个统一 p,r 度量标准,可用于评估基准中的所有任务:
![]()
p,a 分别表示模型预测的 span 集合以及对应的 groud-truth 答案集合;函数 p,r 分别表示准确率和召回率;这个指标 S1 根据元素之间的精确字符串匹配计算基于实例的分数。对于由多个实例组成的测试集,整体 S1score 计算为所有实例的 S1scores 的平均值。对于分类任务,预测和真实答案集由单个元素组成,这使得 S1 分数相当于此类任务的准确性。在整篇论文中,我们报告了 benchmark 中所有任务的 S1scores。
![]()
人类表现已经在几个 NLU 任务上得到了报告,然而,用于估计人类表现的注释方法在向人类提供多少关于任务的信息方面并不总是一致的。我们估计人类的表现,使其在不同的任务中保持一致,并且与机器学习模型在少样本设置中的表现相当。我们为非专家注释者提供了一些示例和简短的任务描述。在零样本场景中,注释者没有收到任何示例。
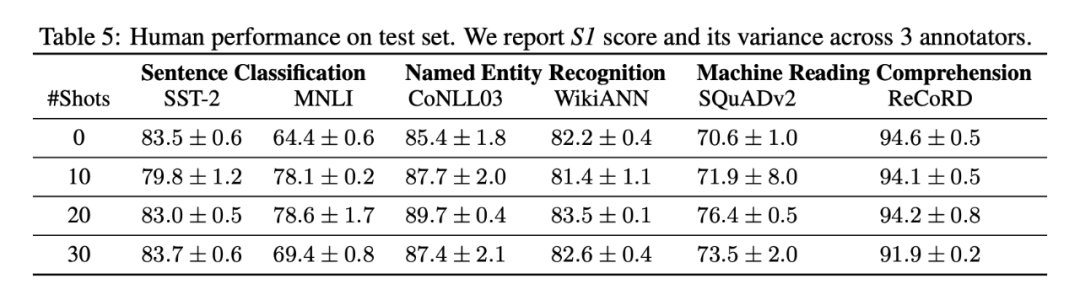
3.1 Human Performance Estimates
为了计算人类的表现,我们测量了每个注释者的表现,并报告了三个众包工作者的平均值和标准差。我们的测试集上的人类表现如下表所示:
![]()
与零样本设置相比,SST 和 ReCoRD 任务在少样本设置中没有表现出任何改进或改进非常小。这意味着人类注释者主要依靠他们自己的知识和简短的任务描述来完成这些任务。
另外,虽然平均而言,在大多数任务的训练步骤中,随着更多数据,人类表现往往会提高,但我们观察到,在某些情况下,人类表现往往会下降当训练示例的数量从 20 增加到 30 时,任务会变得很有趣。这是一个有趣且令人惊讶的观察结果,并表明需要进行额外的研究来更好地了解人类如何利用所提供的示例以及是否有一点,超过这一点,提供更多示例可能会导致没有甚至是负值。
![]()
Results and Discussions
![]()
![]()
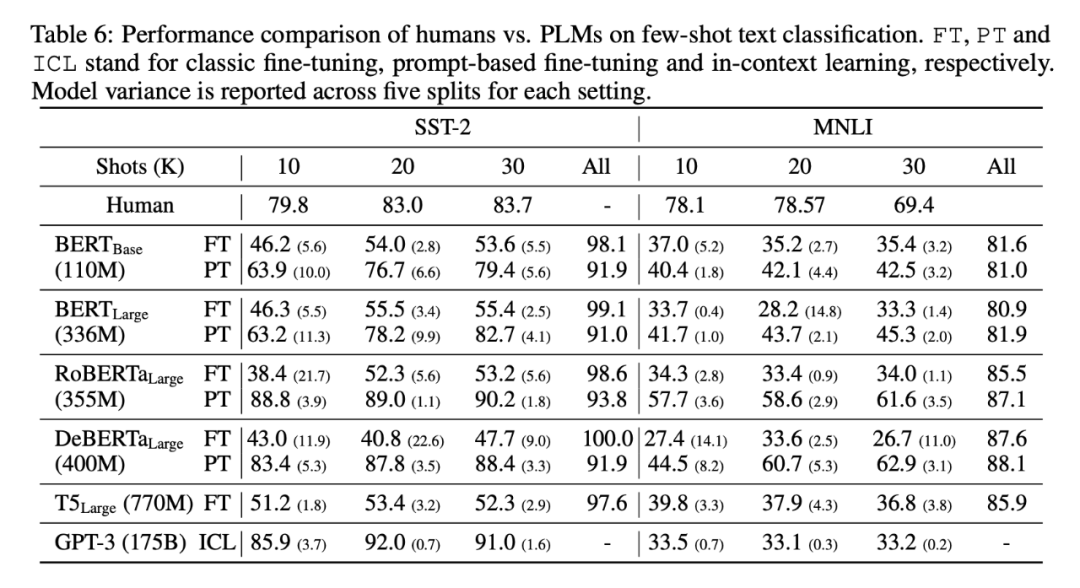
Fine-tuning strategies:
对于分类任务(SST-2 和 MNLI),我们发现基于提示的微调在整体上明显优于其经典的微调对应物。然而,这种优势在两种策略表现相似的完全监督设置中消失了。
Model capacity:
在具有足够训练数据的全监督设置中,不同模型的性能通常随着模型大小的增加而提高。然而,对于小样本设置,我们没有观察到模型大小对经典模型性能的任何一致趋势或影响。
Training labels:
小样本设置和完全监督设置之间存在显着的性能差距。对于经典的微调,增加了一些训练样例并没有一致的性能提升趋势;而有限的额外标记示例可以通过基于提示的微调来提高模型性能——这表明后一种方法在为小样本设置利用额外的标记示例方面更有效。
Model variance:
对于经典的微调,观察到更大的模型在不同的训练分割上具有显着更高的性能差异,BERTBase(考虑的最小模型)在所有任务中表现出最小的差异 6。有趣的是,对于基于提示的微调,较大的模型具有较小的方差,因为它们可能会通过预训练的语言建模头更有效地学习。
Task difficulty:
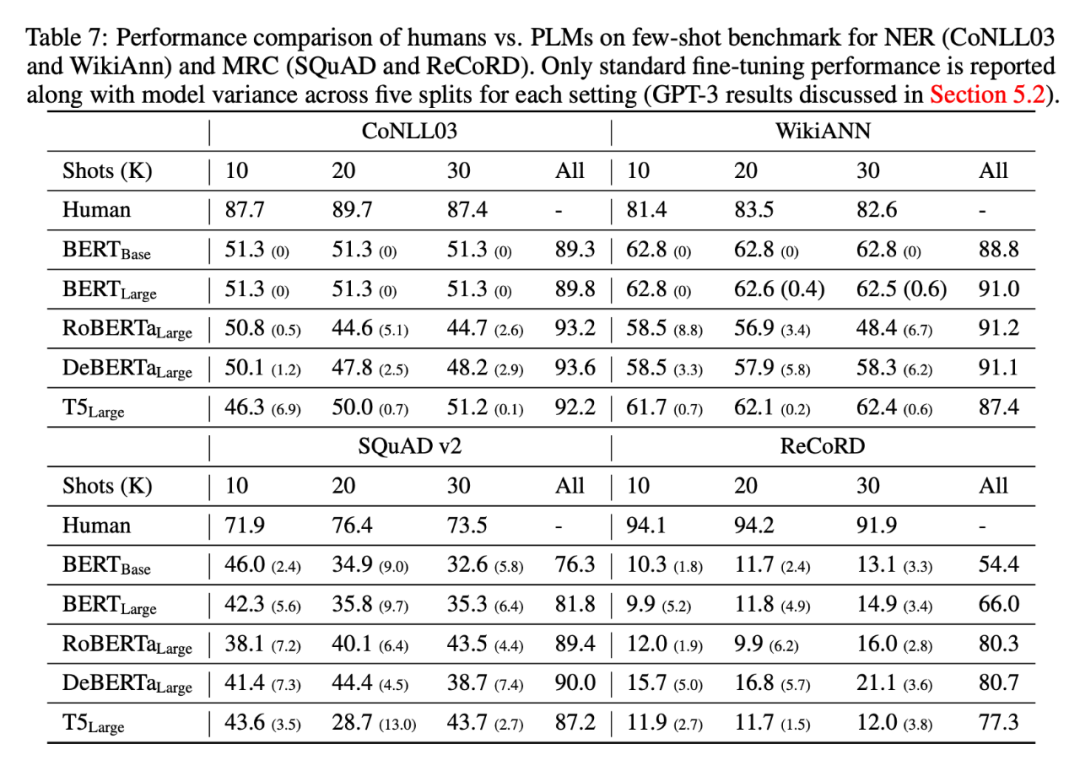
对于像 SST-2 这样的简单任务,基于提示的调优和基于 GPT-3 的上下文学习的少镜头性能非常具有竞争力,并且接近(甚至优于)人类性能。相比之下,对于 NER 和 MRC 等更复杂的任务,大多数不同大小的预训练模型获得接近随机的性能。因此,为此类任务开发更有效的小样本学习方法非常重要。
Model vs. human performance:
在完全监督的设置中,所有模型在所有考虑的任务上都大大超过了人类的表现。然而,在少镜头设置中,模型性能与人类性能之间存在巨大差距。唯一的例外是 SST-2,其中很少有 GPT-3 的表现优于人类。我们仍然保留这项任务,因为我们观察到人类与所有其他模型之间存在显着的少镜头性能差距。此外,对于更复杂的任务,如 NER 和 MRC,这种差距更为明显,其中人类仅使用少数示范性示例就表现得很好,而所有 PLM 的表现都接近随机。
Conclusion and Future Work
这项工作的动机是缺乏标准化的基准和原则来评估少样本 NLU 模型。更重要的是,该 benchmark 旨在公平比较人类和机器在不同 NLU 任务上的表现,给出一些示范性示例。
在这项工作中,我们的重点仅限于自然语言理解,我们只为人类和机器提供文本信息以进行性能比较。虽然人类从包括视觉线索和自然语言在内的多种模态中获取知识,但预训练的语言模型只能访问文本信息。因此,这项工作的自然延伸是在多模态设置中对模型和机器的小样本学习能力进行基准测试。
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()