本篇综述“A Survey of Pretrained Language Models Based Text Generation”的第一作者李军毅来自中国人民大学和加拿大蒙特利尔大学,指导教师为赵鑫教授(通讯作者)和聂建云教授。作者从数据、模型和优化方法三个角度切入,主要介绍了近年来预训练语言模型技术在文本生成领域的研究进展,以及相应的挑战和解决方案;然后陆续介绍了预训练语言模型在三个代表性的文本生成任务中的应用,包括机器翻译、文本摘要和对话系统,以及广泛采用的评测基准和评价指标;最后讨论提出了若干个未来的研究方向。本文梳理了2018年至今总计200余篇预训练语言模型研究工作,为后续研究者了解熟悉此领域提供巨大帮助。
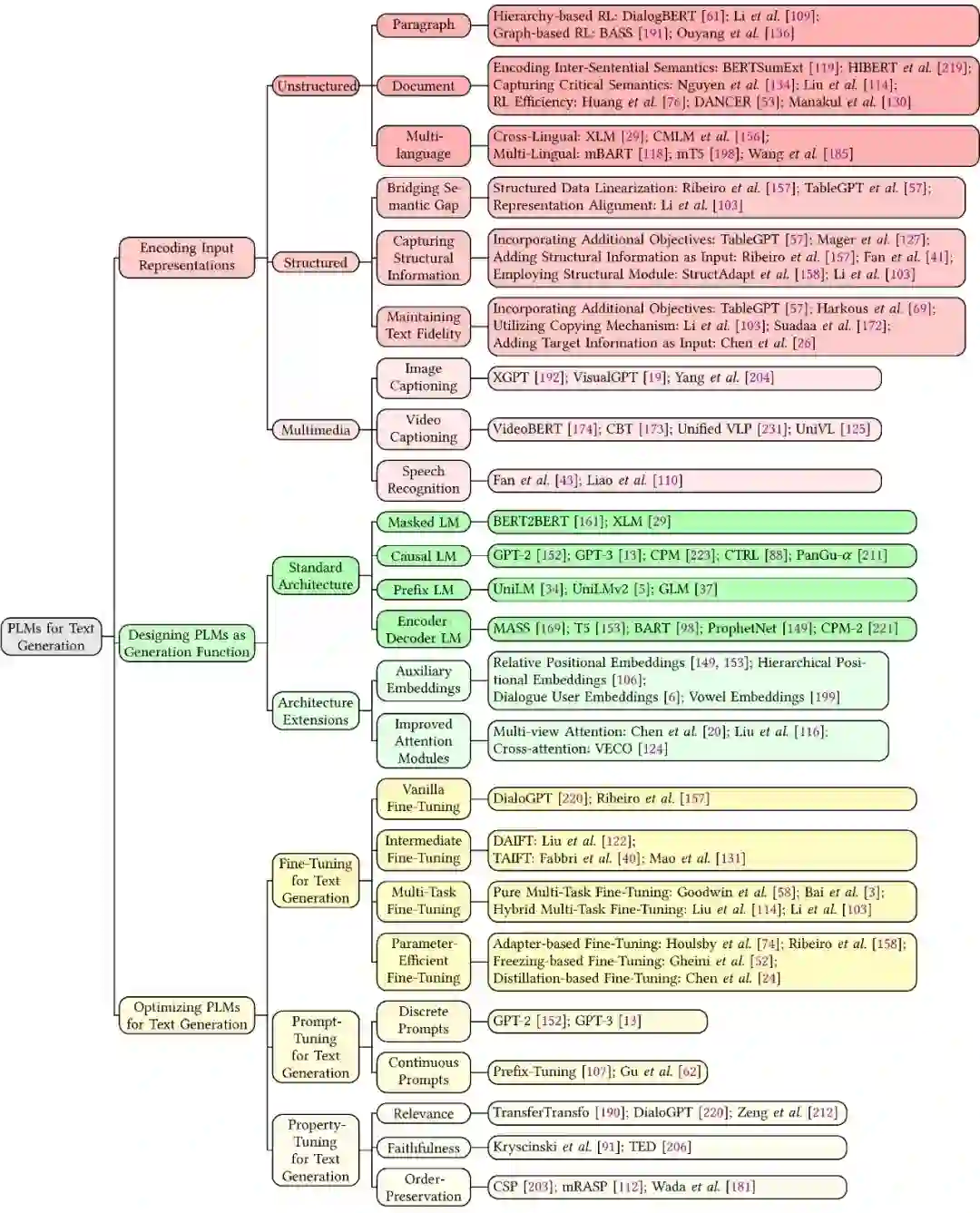
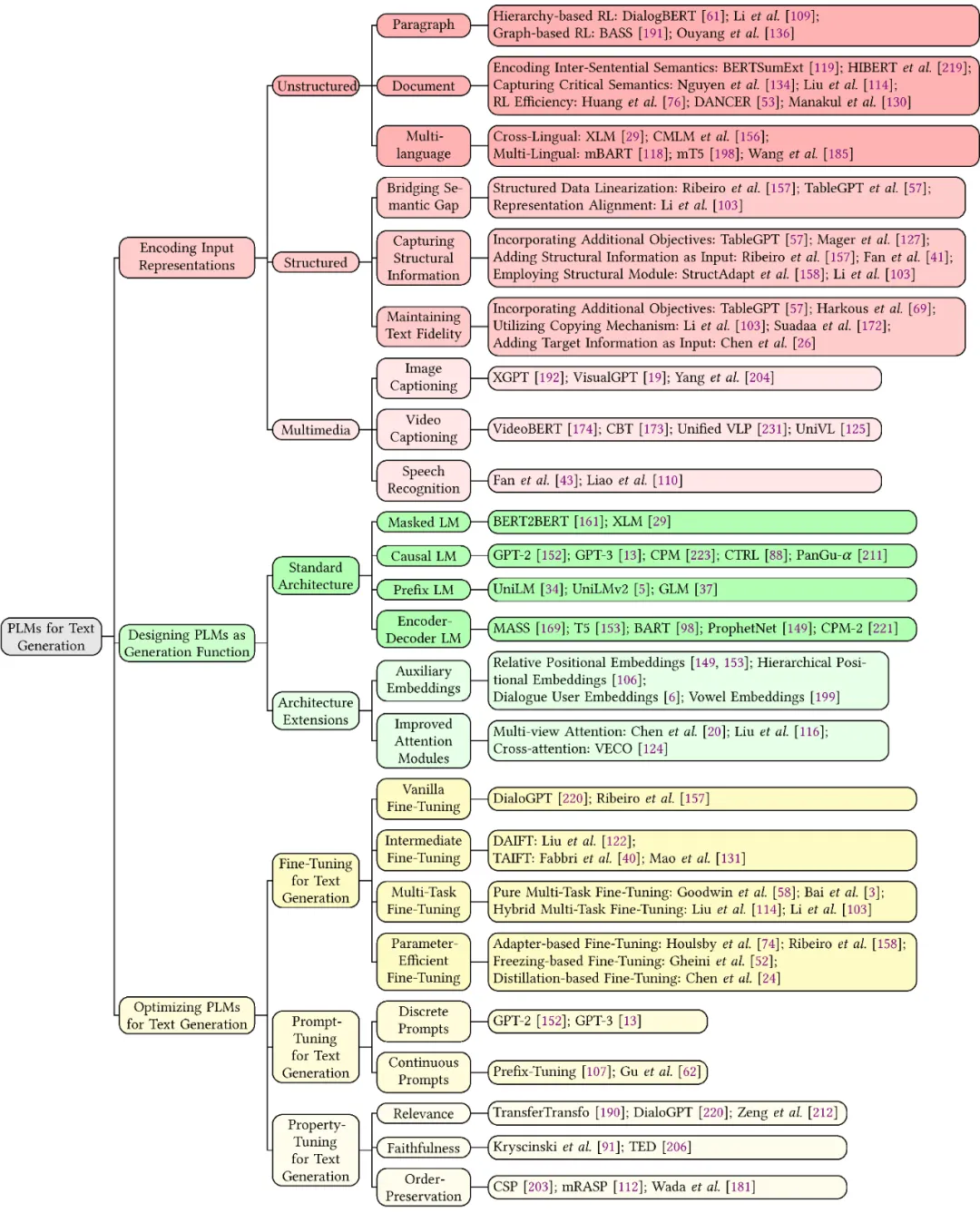
预训练语言模型技术解决文本生成任务主要考虑三个方面的挑战:1)如何有效地编码输入表示并保留其语义?本文第三章对输入数据的形态进行了划分,包括非结构化文本、结构化数据和多媒体数据,梳理了预训练语言模型针对不同类型输入的表示学习方法;2)如何设计有效的预训练语言模型作为生成函数?本文第四章介绍了四种预训练语言模型模式,包括Masked LM,Causal LM, Prefix LM和Encoder-Decoder LM,并在此基础上作出的拓展,例如增加额外的输入Embedding和Attention机制的创新;3)如何有效地优化预训练语言模型并保证输出文本满足某些语言属性?本文第五章介绍了三种针对文本生成任务的优化策略,包括传统的Fine-Tuning技术,新兴的Prompt-Tuning技术,以及针对特殊属性设计的Property-Tuning技术。
"妙笔"生花:一个易用、高效的文本生成开源库
关于预训练语言模型在文本生成任务上的应用,不得不提我们AI Box团队开发的文本生成工具包——TextBox,中文名“妙笔”。到目前为止,妙笔总共支持四个大类总计21个文本生成模型,其中就包括相关的预训练语言模型,比如GPT-2, BART, T5和ProphetNet等;同时我们也支持机器翻译、文本摘要、对话系统、data-to-text等主流生成任务和相应的测试。研究者可以方便地使用TextBox进行一站式训练,数据处理、数据加载、模型训练和测试等环节均可以由TextBox自动完成。
参考文献: [1] Li, J., Tang, T., Zhao, W.X., Nie, J. Y., & Wen, J. R. (2022). A Survey of Pretrained Language Models Based Text Generation. arXiv preprint arXiv:2201.05273.
[2] Li, J., Tang, T., He, G., Jiang, J., Hu, X.,Xie, P., ... & Wen, J. R. (2021). Textbox: A unified, modularized, and extensible framework for text generation. arXiv preprint arXiv:2101.02046.