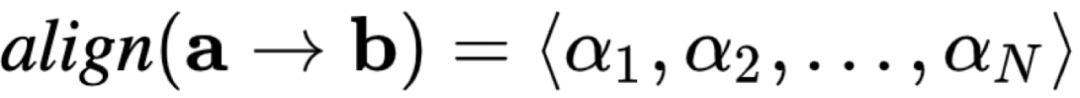长期以来,评价机器生成的文本比较困难。近日,CMU邢波(Eric Xing)教授和UCSD胡志挺(Zhiting Hu)教授的团队提出用一种运算符,统一各类生成任务的评价方式,为未来各种新任务、新要求提供了更加统一的指导。实验表明,基于统一框架设计的评价指标,在多个任务上超过了现有指标与人工评分的相似度,现在通过PyPI和GitHub可以直接调用。
自然语言生成(NLG)包括机器翻译、摘要生成、机器对话等自然语言处理 (NLP)任务。这些任务虽然都要求生成通顺的文本,但是最终的表达目标往往有很大的区别。比如说,
翻译任务
需要完整、精确地表达原文的含义;
摘要生成
需要简洁、准确地体现原文最重要的信息;
对话系统
则需要与用户进行生动、有用的对答。
过去几年间,研究人员在这些任务的建模方面,取得了很大的进步。然而,评价语言生成的结果,却依旧比较困难。人工评价最准确,但是非常昂贵耗时。自动评价则反过来,规模化比较容易,但在如何评价方面比较模糊。
传统上的评价方法是比较模型生成的文本与人写的参考文本,但近年的研究表明,随着模型的进步,这样的方法已经越来越难以区分文本的好坏。事实上,在AAAI 2021会议上的DSTC9对话系统比赛中,
人工评分已经不再考虑参考文本
,而是依靠评分员综合对话历史、知识情景和模型回答,作出评判。
同时,实际应用中的部署,也要求对生成模型作出多维度的评价,而这些是传统的单一指标做不到的。比如,2021年百度主办的「千言:面向事实一致性的生成评测比赛」中,除了传统的信息选择指标外,还考察了事实性指标,并为之设计了独立的评价流程。之前提到的DSTC9比赛的各个分赛也分别考察了3-8个不同的维度指标。
为了解决如上所述的新需求,相关工作提出了各种各样的评价方法和新指标,但是这些方法往往是针对具体的任务和目标而设计。
对于日新月异的各类任务,要评价什么?如何评价?目前还缺乏系统的指导
。
在这个方向上,
CMU(卡耐基梅隆大学)、Petuum Inc.、MBZUAI(穆罕默德·本·扎耶德人工智能大学)和UCSD(加州大学圣迭戈分校)的研究团队提出了一个自然语言生成评价的理论框架,为未来各种新任务和新要求,设计评估流程时,都提供了更加统一的指导
。
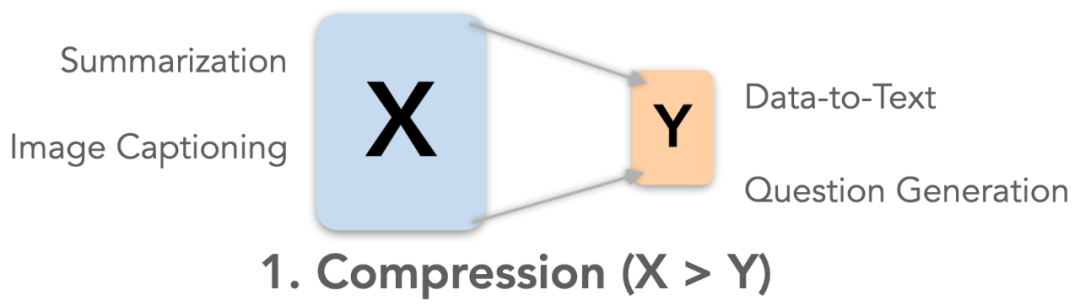
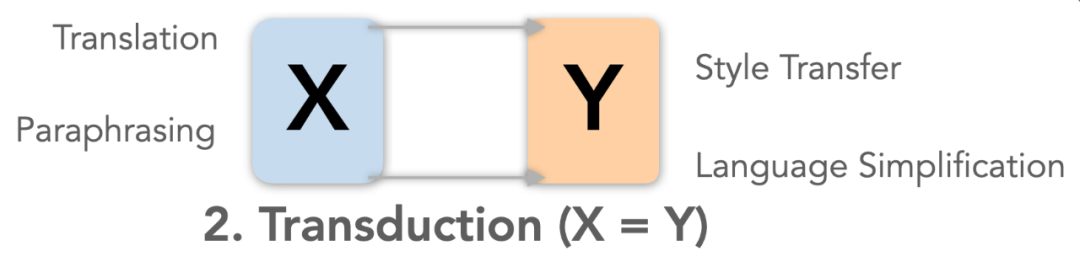
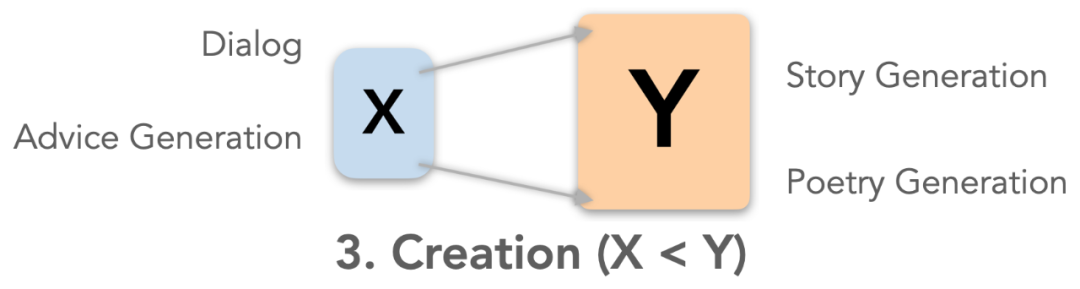
首先,研究人员根据信息从输入到输出的变化方式,把语言生成任务分为三大类,每类任务对输出提出不同的评价需求。通过给新任务归类,就可以对「评价什么」有所启发。
其次,他们用一种称为「信息对齐」的运算符统一了所有任务类别的评价方式,从信息对齐的角度出发设计评价指标,可以解决大量的「如何评价」问题。
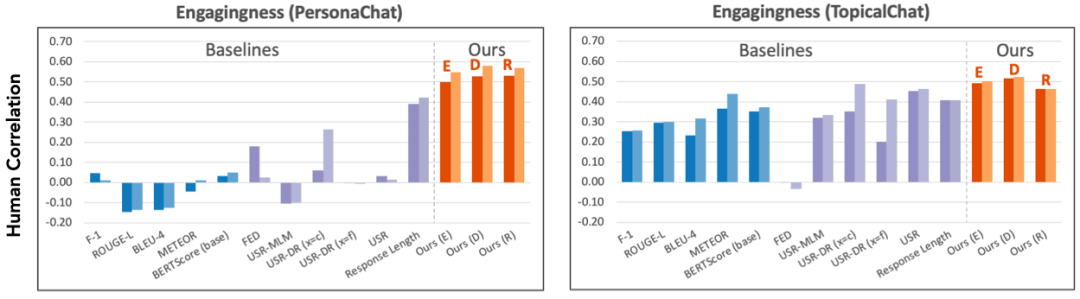
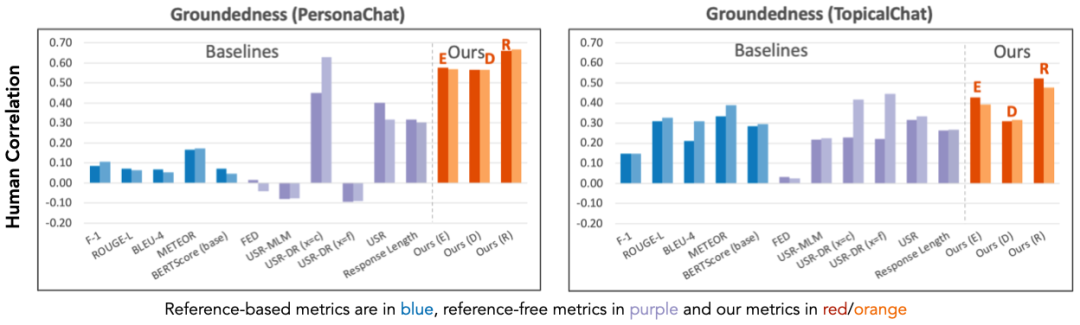
论文中基于信息对齐,统一设计了一系列评价指标,在评价多种任务(摘要生成、风格转换和知识对话)中与人类评分的相似度最高超过现有指标57.30%。
论文中设计的评价指标已经上传到Python库,用pip install就可以直接安装。研究人员在GitHub上也公开了代码,并提供了数种训练好的信息对齐模型,欢迎各位同学在研究中调用。
![]()
论文链接:https://arxiv.org/pdf/2109.06379.pdf
代码和API链接:https://github.com/tanyuqian/ctc-gen-eval
Python 安装:pip install ctc_score
根据任务输入(X)和输出(Y)文本中,信息量的关系,
研究者认为可以把语言生成任务分为三大类:压缩、转换和创建,分别对应输入大于、等于和小于输出
。每一类任务的目标都有区别,也对输出文本提出了各自的要求。
我们可以通过对新任务对分类
,对「评价什么」有所启发。
![]()
![]()
![]()
这里可以看到,评估的重点取决于任务中输入输出的信息量变化,因此,如果能够测量输入输出信息重合度,就可以评估所有类别的生成任务。
为了测量如上所述的重合度,
研究者引入了「信息对齐」这个运算符,这样就统一了所有生成任务的评价方式
。
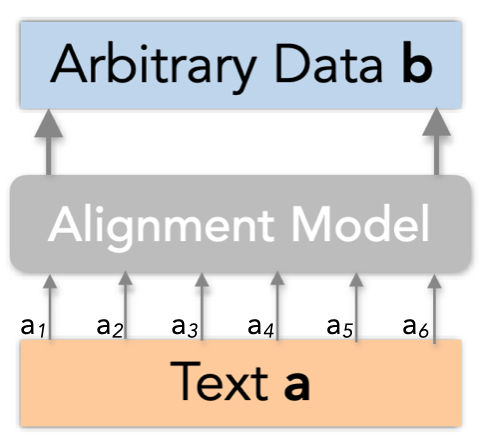
信息对齐是说,对于文字A和任何数据B,可以对于A的每个词都算出一个置信度,这个词的信息有没有在B中反映出来。具体的数学形式为如下所示的向量:
在实际中,这个数据B不一定要是文字,也可以是任何模态的数据,只要有一个模型(Alignment Model)能算出这个对齐的置信度。A、B、模型和对齐向量的关系如下图所示:
![]()
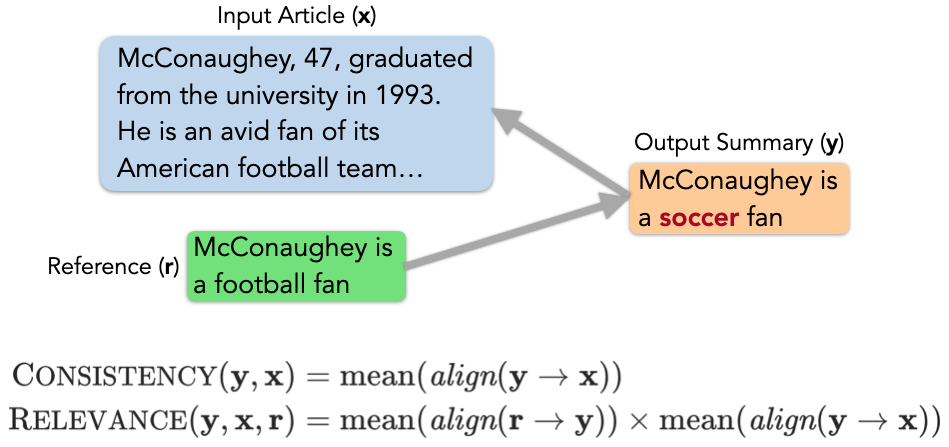
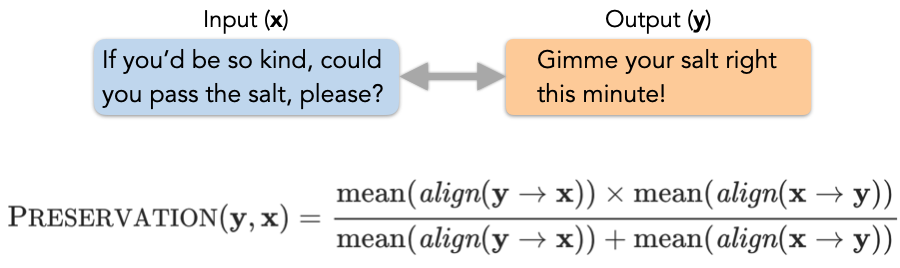
下面,研究者展示了如何统一地用信息对齐这个算符,来定义各种语言生成任务的评价指标。
![]()
![]()
![]()
现在已经用信息对齐运算符定义了这么多评估指标,下一步来看这个运算符是怎样实现的。
研究者把信息对齐当作一个预测问题建模,提出了三种基于预训练模型(Pretrained Language Models)的实现方法,普遍采用自监督学习
。模型准确度可以通过与人工标注比较来评价。
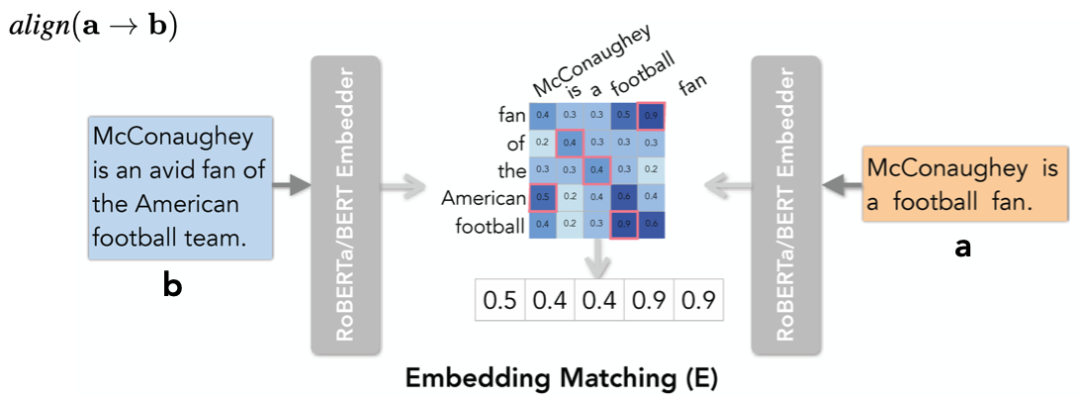
词向量召回(Embedding Matching)
![]()
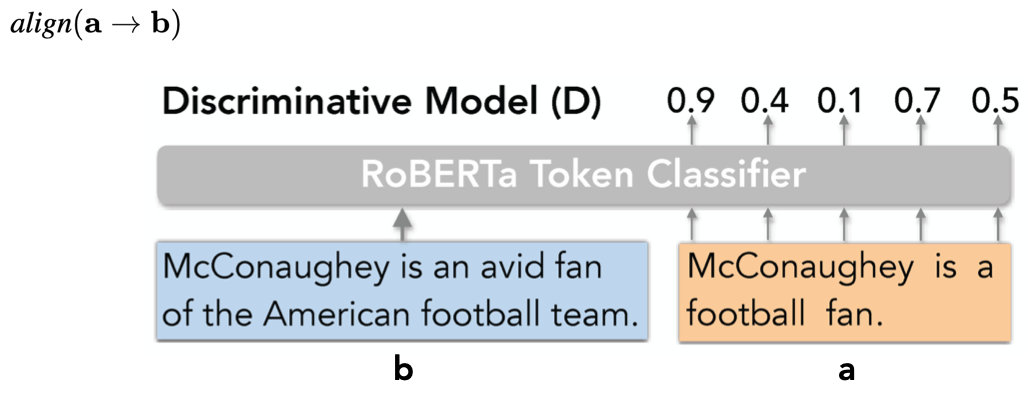
判别模型(Discriminative Model)
![]()
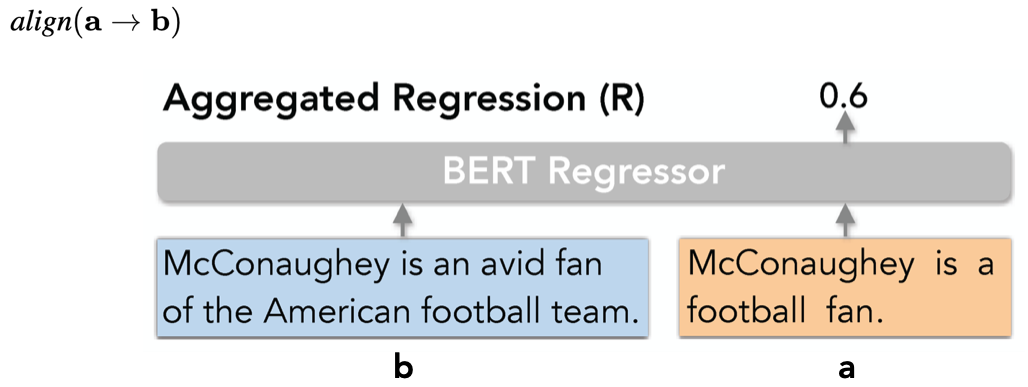
回归模型(Aggregated Regression)
![]()
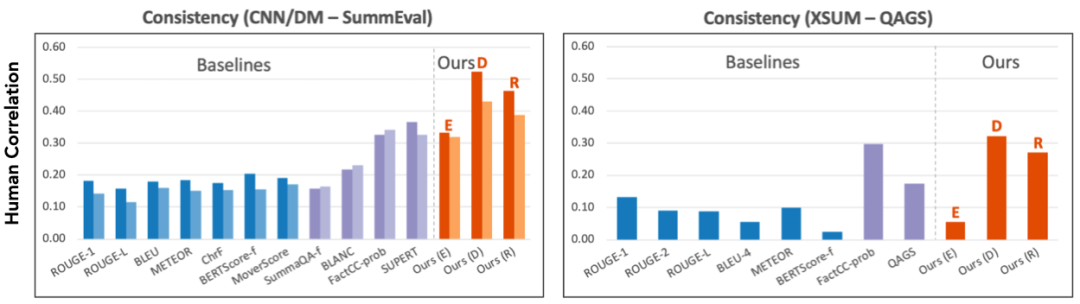
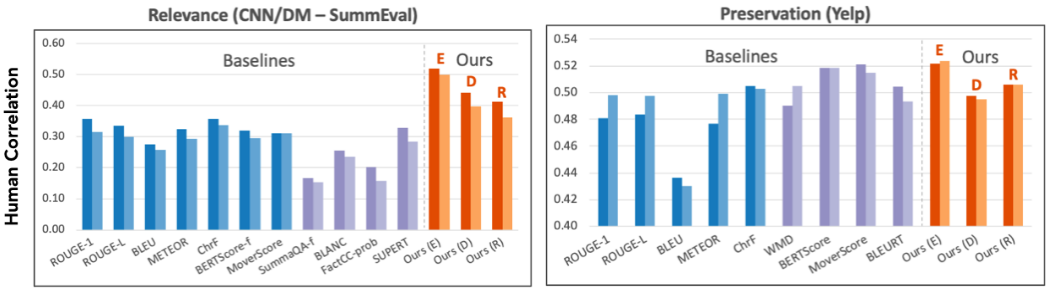
实验结果表明,研究者的统一设计的评价指标,与人工评分的相似度,超过之前的针对任务特别设计的指标,最高超过现有指标57.30%。另外,研究者发现,对齐模型预测准确度越好,他们的指标就越接近人的评价。
![]()
![]()
![]()
![]()
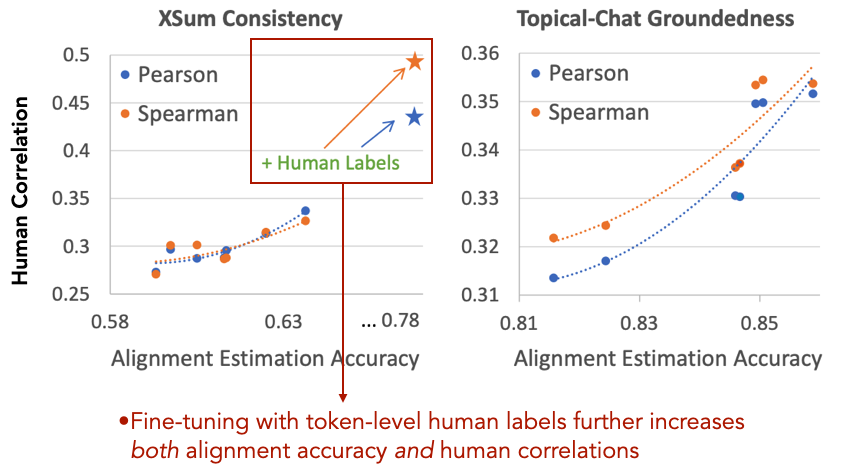
研究者的对齐模型普遍使用自监督学习,但使用人工标注训练可以有效提升准确度和以此实现的评价指标。与人工评分的相似度如下图所示:
![]()
这说明了:只要能够改善对齐预测模型,就能改善一大批评价指标。我们可以把对齐预测作为一个单独的任务,这个任务的进步直接提升评价语言生成的准确度。
这项工作开启了可组合(Composable)的文本评价流程。像软件工程一样,研究者表示可以把这个系统分为若干模块,这些模块可以独立地改进、规模化、和诊断,未来期待有更多的探索。
封面来源:https://soa.cmu.edu/
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com