NLP数据增广不故障!清华大学提出FlipDA,轻松解决小样本任务|ACL 2022
新智元报道
新智元报道
作者:zhoujing zhengyanan
编辑:好困
【新智元导读】数据增广是通过自动生成新的训练数据来提升模型性能的方法,而现有方法多基于简单问题设置。然而,在极限问题场景下,这些方法会全部失效。
针对数据增广方法在困难任务(小样本自然语言理解任务)以及更强的基线模型(超过1亿参数量的大规模预训练模型)条件下的「故障模式(Failure Modes)」问题。
清华大学的团队提出了一个全新的方法——「FlipDA: Effective and Robust Data Augmentation for Few-Shot Learning」,不仅实现了小样本学习性能和鲁棒性的提升,同时还能有效避免「故障模式」的发生。
目前,该工作已被ACL2022主会接收。

论文地址:https://arxiv.org/abs/2108.06332
项目地址:https://github.com/zhouj8553/FlipDA
小样本学习数据增广
数据增广需求:有效性和鲁棒性
小样本学习设置下,数据增广主要有两方面关键需求:有效性和鲁棒性。
有效性强调数据增广方法应该至少在某些任务上有大幅提升;鲁棒性则要求数据增广方法不会在任何情况下陷入「故障模式 (Failure Modes)」,即因为某些微小条件变化或者扰动造成的性能大幅度下降。
有效性:手动数据增广可以大幅提升模型性能
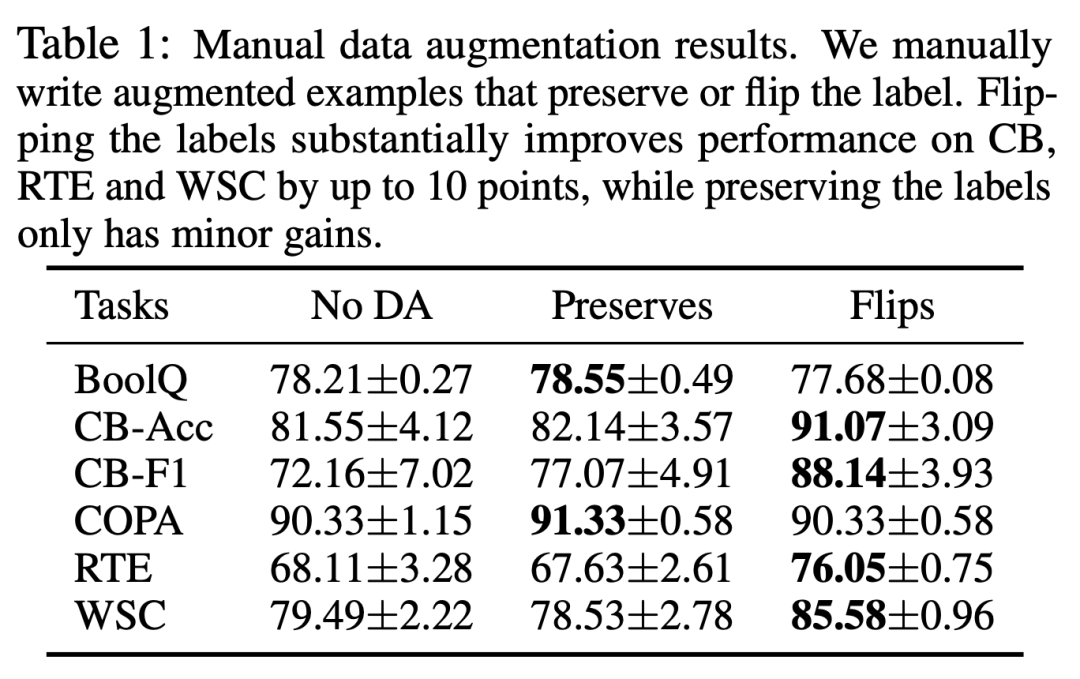
我们首先通过手动数据增广,分别构造出了,改变数据标签和保持数据标签两种不同的增广样本。数据增广后的小样本学习性能结果如表格所示。
结果表明:改变数据标签的增广样本可以在某些任务上带来近10个点的提升,而保持数据标签的增广样本只能带来少量提升。
这个手动增广结果给我们带来启发,构造改变标签的增广数据对于提升性能是至关重要的。
鲁棒性: 什么导致了故障模式?
通过观察已有增广方法的失败样例我们发现:增删词以及改变关键词会改变数据标签,导致了增广数据和标签对的不一致。
从而让使用EDA方法增广数据后性能发生了显著下降,结果如下表所示。

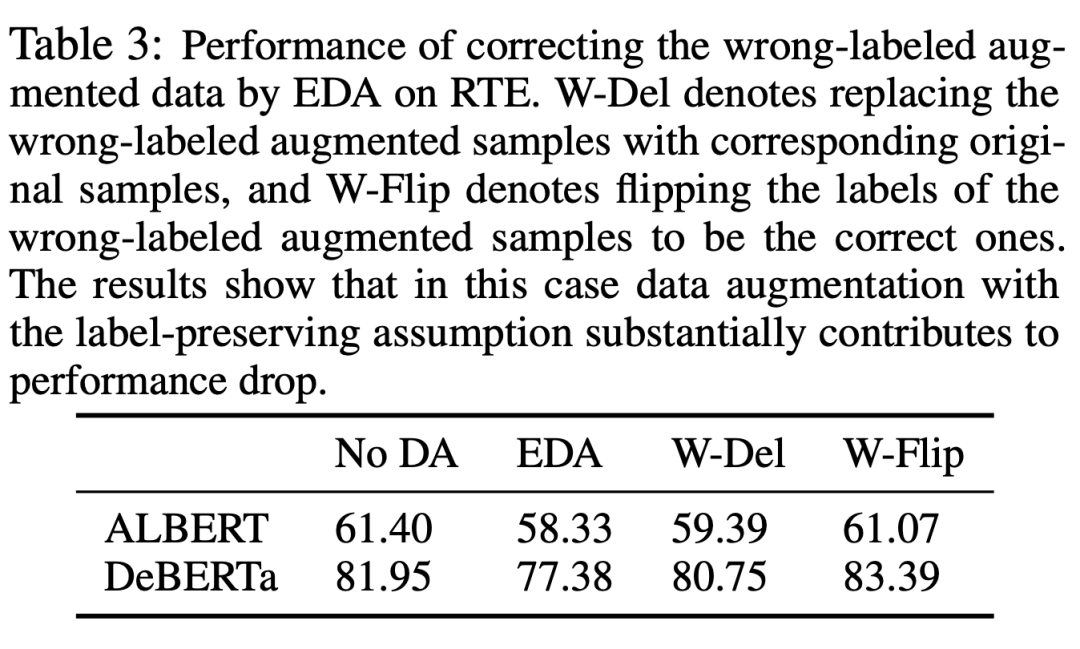
我们进一步尝试修正上述问题增广数据:
(1)将错误标签的数据样本替换为原始样本;
(2)改变错误的标签。修正增广数据后的结果如下表格所示,结果表明通过删除错误样本和纠正样本标签都可以有效矫正上述故障模式,大幅提升小样本学习性能。
FlipDA: 自动标签反转数据增广
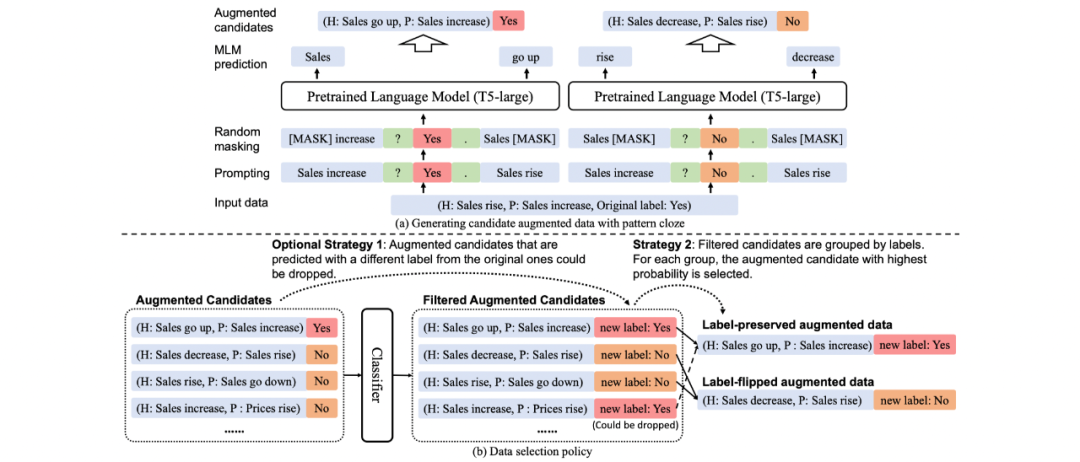
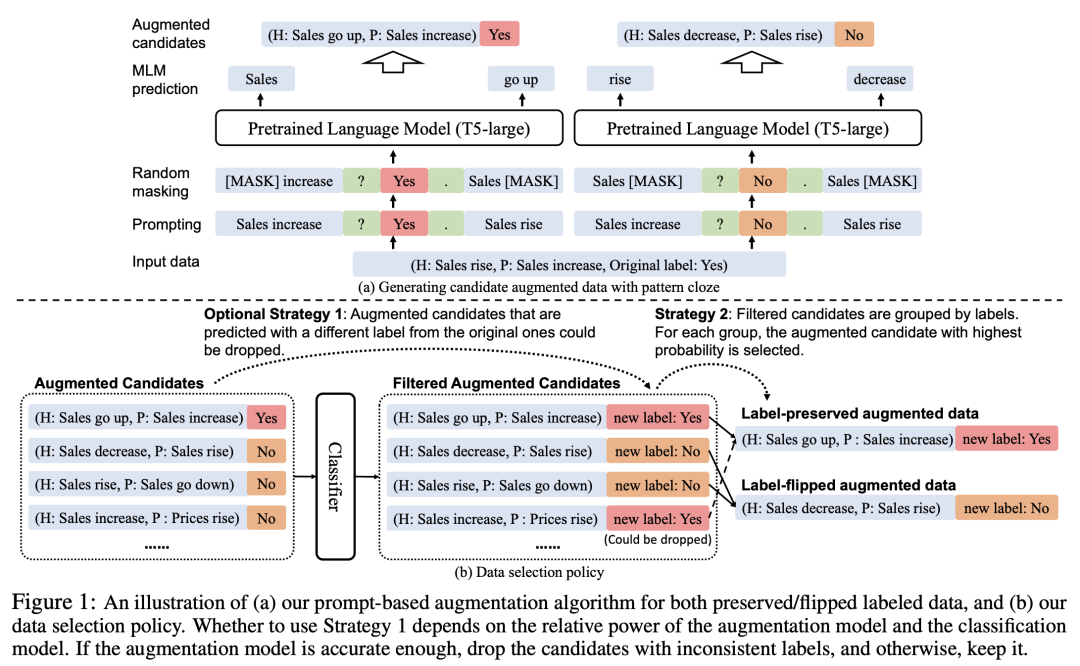
基于上述观察和实验结果,我们提出了FlipDA,一种自动进行标签反转的数据增广方法。该方法整体基于self-training架构,总共包含如下4个步骤:
1. 使用原始数据训练一个分类器。
2. 使用T5模型生成改变样本和保持样本标签的增广样本。
先将样本中的句子进行mask操作,然后使用prompt将句子进行连接。对于不同的标签,我们会填入不同的标签,然后让T5模型自动补全被mask掉的句子,从而生成保持标签和翻转标签的不同样本。下图(a)。
3. 使用分类器为每个类别选择最可能的样本。
先用分类器给生成的候选样本打标,然后对于每个标签选择可能性最大的样本。下图(b)。
4. 使用原始数据样本和新增广数据样本混合重新训练分类器。
FlipDA方法示意图
实验结果
我们在SuperGLUE的8个数据集上进行了实验,其中涵盖了共指消歧、因果推断、文本蕴含、词义消歧、问答等较为困难的自然语言理解任务。
我们分别在两个大规模预训练模型:DeBERTa-v2-xxlarge和ALBERT-xxlarge-v2上进行了实验。
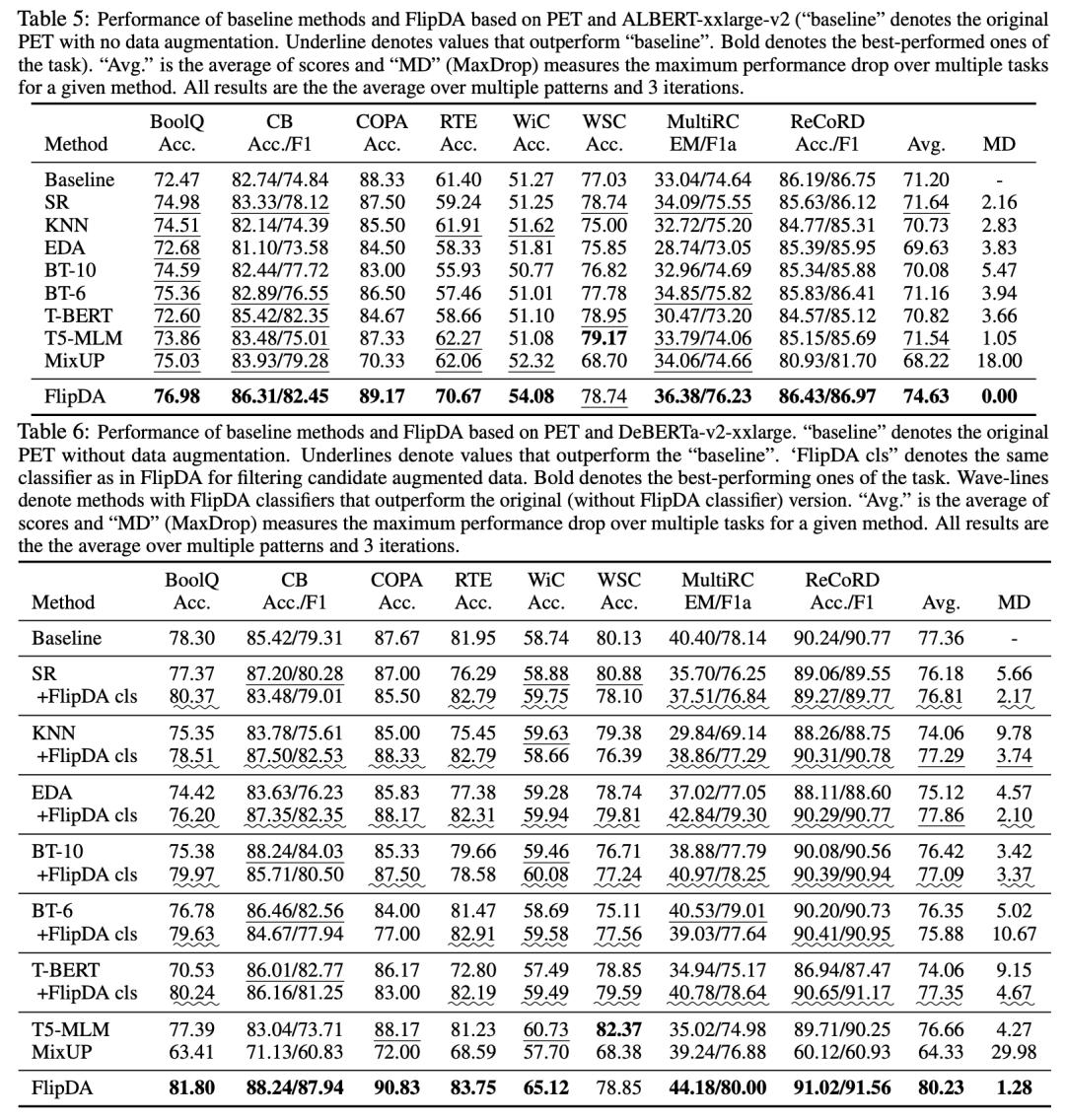
实验结果表明:FlipDA相较于诸多基准方法有显著优势,FlipDA在大多数任务上获得更显著的性能提升(Avg.),同时几乎未发生性能下降(MD, max drop)。
此外,我们基于RTE数据集对不同类型的增广样本进行案例分析。
结果表明:FlipDA在四种不同类型的增广条件下生成的样本自然可读,且信息更加准确。

总结
FlipDA强调并且有效解决了小样本自然语言理解任务上,数据增广的有效性和鲁棒性问题。通过自动化的标签反转数据增广,FlipDA进一步提升小样本泛化性能,进而实现了更大幅度更稳健的性能提升。
此外,从理论上进一步理解为什么,以及如何在现有数据点附近生成标签翻转数据提高泛化能力将是至关重要的;增加增强数据生成的多样性和质量也是一个重要的长期目标。
参考资料:
https://arxiv.org/abs/2108.06332



