小样本自然语言理解的基准测试FewNLU | 论文荐读
论文标题:
FewNLU: Benchmarking State-of-the-Art Methods for Few-Shot Natural Language Understanding (ACL'22)
作者:
Yanan Zheng*, Jing Zhou*, Yujie Qian, Ming Ding, Chonghua Liao, Jian Li, Ruslan Salakhutdinov, Jie Tang, Sebastian Ruder, and Zhilin Yang
论文链接:
https://arxiv.org/abs/2109.12742
论文代码和数据:
https://github.com/THUDM/FewNLU
FewNLU Leaderboard:https://fewnlu.github.io
现如今基于预训练模型的小样本自然语言理解领域尚缺乏一个标准的评价准则。已有相关工作采取不同的性能评价方式,例如 [1, 3, 4] 使用一组预先经验固定的超参数进行实验,然而有研究工作[2, 8]指出该实验评价设置可能面临高估真实性能的风险(超参数选择是在既往经验中观测了测试集性能的结果);例如 [5, 7] 提出采用一个小的验证集进行超参数选择,然而这些工作在关键细节各不相同(例如如何构建训练集-验证集数据拆分),然而这些细节差异实际上会导致严重性能评价偏差。总结来说,目前该领域尚缺乏标准评估准则的现状,极大阻碍了已有方法基于统一的标准公平比较,也无法客观评价该领域的真实进展。此外,小样本学习具有对许多因素敏感性高的特点,例如已有研究工作指出造成小样本学习不稳定的原因包括提示模板的选择、训练数据的顺序、权重的初始化、优化算法以及解码策略等,这也为设计稳健且有效的评价准则带来挑战。
基于上述现状,我们强调并解决小样本自然语言理解评价中三方面问题:
(1)提出一个新的小样本自然语言理解评价框架 FewNLU,并且从三个关键方面(即测试集小样本学习性能、测试集和验证集相关性、以及稳定性)量化评估该评价准则的优势。
(2)在新的评价框架下,本文对该领域近期的先进方法以及它们的组合方法,在相同的标准下进行了重新评价。重新评价的结果揭示一系列颠覆以往的新结论。
(3)我们开源工具包 FewNLU,其中实现了提出的标准评价框架以及领域先进的基准方法;并且构建 Leaderboard。

对小样本自然语言评价体系的衡量,我们提出衡量小样本评价体系的关键性指标,分别是:最终测试集小样本学习性能、测试集和验证集关于一个超参数空间分布的相关性、以及稳定性。同时我们以量化实验的方式,对几种候选的评价策略进行比较以论证其有效性。已有实验结果如下,可以看出,多次数据划分(Multi-Splits)是比 K 折交叉验证(CV)和最短描述距离(MDL)更好的数据拆分策略。
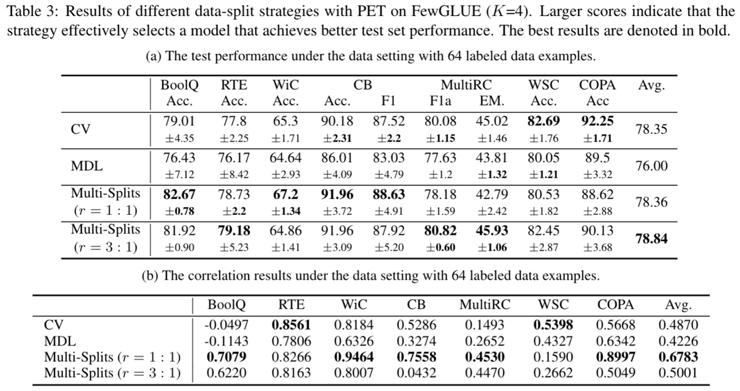
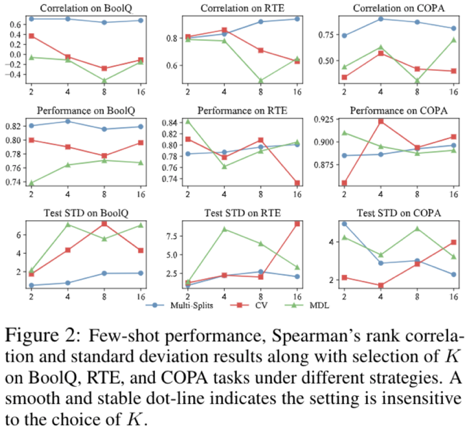
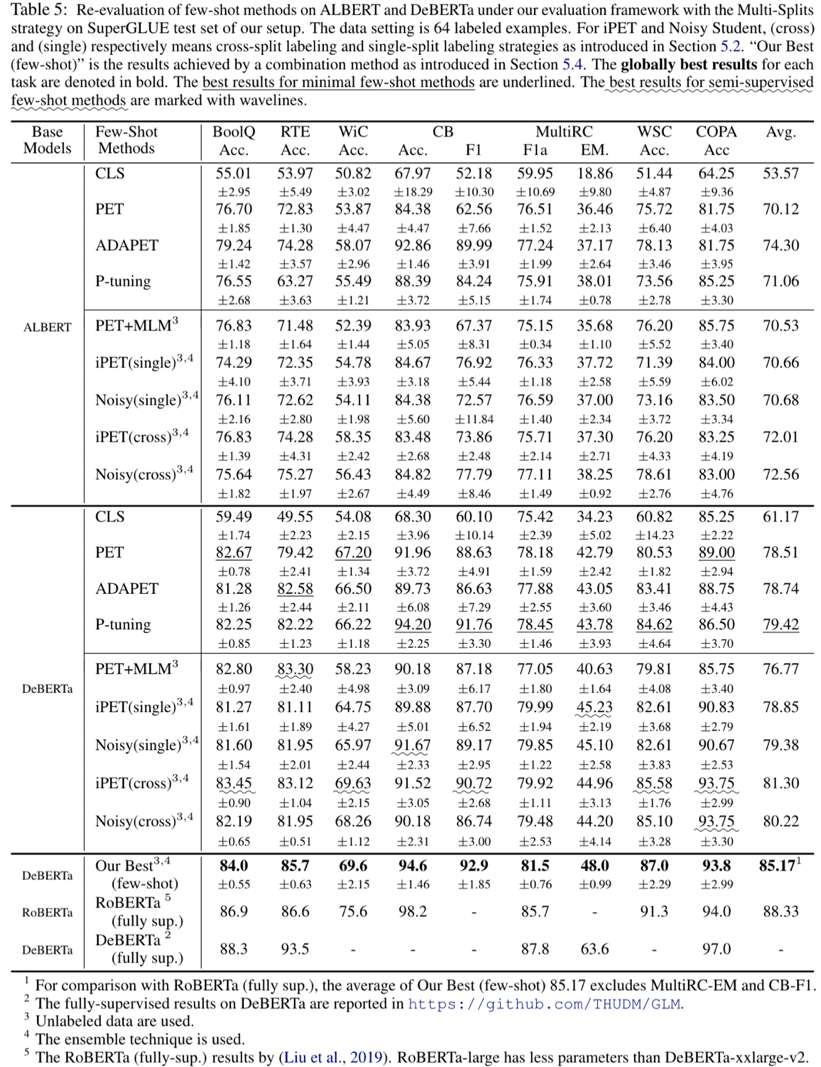
此外,我们还通过基于上述提出的小样本自然语言理解评价框架,对已有的先进小样本学习基线方法进行重新评估和比较,如下图展示。重新评估的结果揭示出一系列新发现和结论:
结论1: 小样本学习方法的绝对性能和相对性能差异,和先前相关工作中的结论不同,即在先前文献中未被准确估计。此外小样本方法(例如 ADAPET)在像 DeBERTa 这样的大型模型上的优势会显著降低。半监督少样本方法(例如 iPET和Noisy Student)的增益在较大的模型上也可以保持一致性。
结论2: 不同小样本学习方法的增益在很大程度上是互补的。通过将目前各种先进方法组合,它们可以实现优于任意单一方法的小样本学习性能。目前最佳组合方法的小样本学习性能,接近 RoBERTa上实现的全监督性能;但和目前 DeBERTa 上实现的最优全监督性能相比,它仍然存在较大的差异性。
结论3: 实验表明,已有相关工作中不存在单一的小样本学习方法能够在大多数 NLU 任务上取得主导性优势性能。这为未来进一步开发出具有跨任务一致性和鲁棒性的小样本学习方法提出新的挑战。
点击【阅读原文】查看paper






