
OpenAI在昨天悄然放出了GPT第三代——《Language Models are Few-Shot Learners》。刷遍Twitter!史无前例!论文介绍了GPT-3这是一种由1750亿个参数组成的最先进的语言模型。论文由32位作者72页pdf。

最近的工作表明,通过对大量文本进行预训练,然后对特定任务进行微调,在许多NLP任务和基准测试方面取得了巨大的进展。尽管这种方法在架构中通常与任务无关,但它仍然需要成千上万个特定于任务的实例微调数据集。相比之下,人类通常只需要几个例子或简单的指令就可以完成一项新的语言任务——这是目前的NLP系统仍然难以做到的。在这里,我们展示了扩展语言模型极大地提高了任务无关性、低命中率的性能,有时甚至达到了与先前最先进的微调方法的匹配性能。具体来说,我们训练了一个带有1750亿个参数的自回归语言模型GPT-3,比以前任何非稀疏语言模型都多10倍,并在小样本设置下测试了它的性能。对于所有任务,GPT-3的应用没有任何梯度更新或微调,任务和小样本演示指定纯粹通过与模型的文本交互。GPT-3在许多NLP数据集上实现了强大的性能,包括翻译、问答和完形填空任务,以及一些需要即时推理或领域适应的任务,如整理单词、在句子中使用新单词或执行3位算术。同时,我们还确定了一些数据集,其中GPT-3的小样本学习仍然效果不佳,以及一些数据集,其中GPT-3面临着与大型web语料库上的训练有关的方法问题。最后,我们发现GPT-3可以生成新闻文章的样本,这些文章是人类评价者难以区分的。我们讨论了这个发现和一般的GPT-3的更广泛的社会影响。

GPT-3的主要目标是用更少的领域数据、且不经过精调步骤去解决问题。
为了达到上述目的,作者们用预训练好的GPT-3探索了不同输入形式下的推理效果。
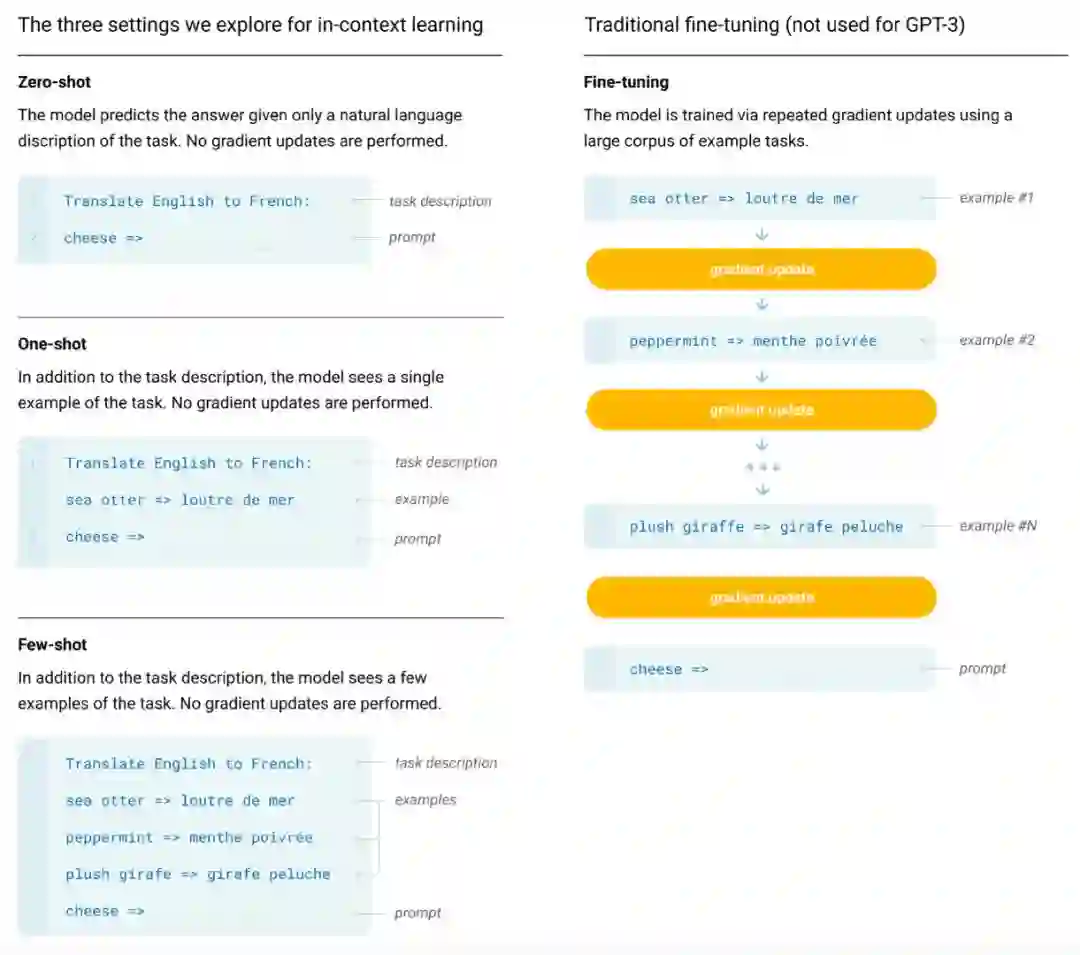
这里的Zero-shot、One-shot、Few-shot都是完全不需要精调的,因为GPT-3是单向transformer,在预测新的token时会对之前的examples进行编码。
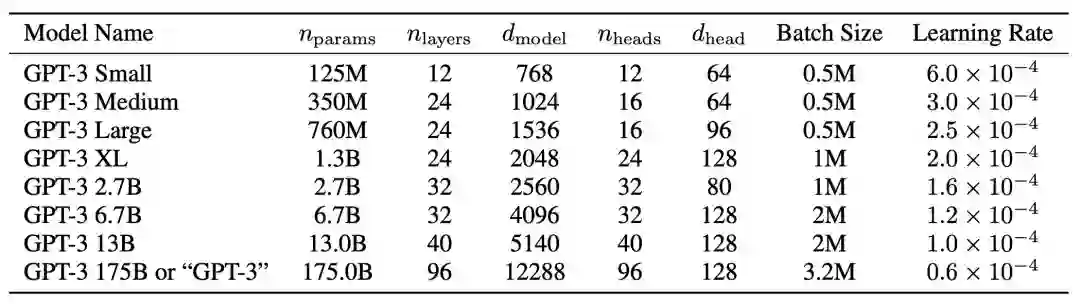
作者们训练了以下几种尺寸的模型进行对比:
实验证明Few-shot下GPT-3有很好的表现:
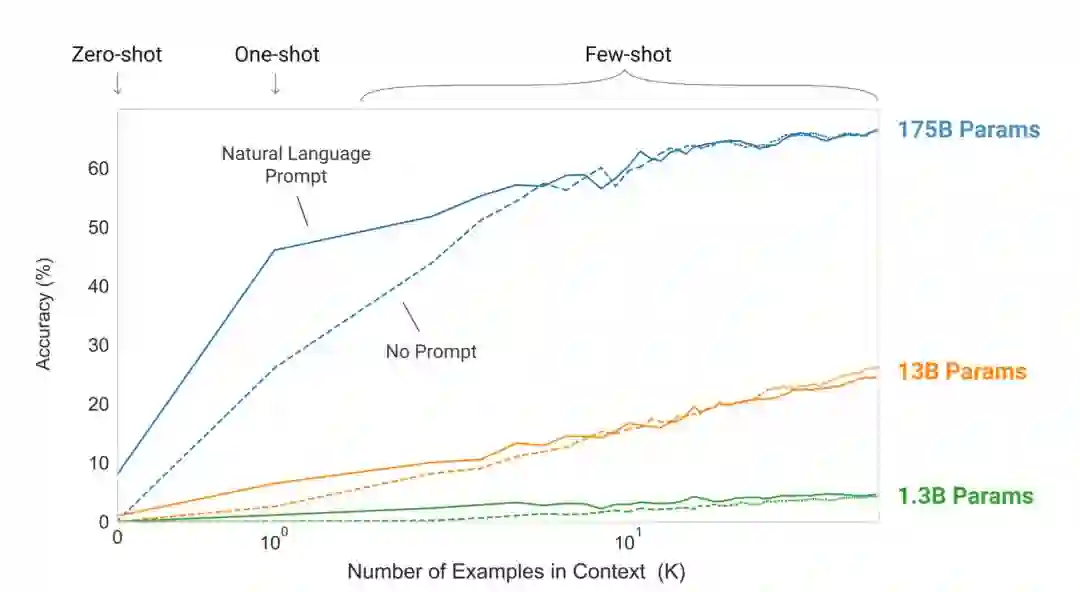
最重要的是,GPT-3在Few-shot设定下,在部分NLU任务上超越了当前Fine-tuning的SOTA。

