DeepMind提出强化学习新方法,可实现人机合作

尽管人工智能研究人员正力图建立能在围棋、星际争霸到 Dota 等复杂游戏中击败人类专家的强化学习系统,但如何创建出能与人类开展合作而非竞争的强化学习系统是人工智能正面临的更大挑战。
在一篇由 DeepMind 的人工智能研究人员最新预发布的论文中,提出了一种称为 FCP(Fictitious Co-Play,虚拟合作)的新方法。该方法实现智能体与不同技能水平人类间的合作,无需人工生成数据训练强化学习智能体(agent)。论文已被今年的 NIPS 会议接收。
论文通过使用一款称为 Overcooked 的解谜游戏进行测试,结果表明在与人类玩家的组队合作中,FCP 方法创建的强化学习智能体表现更优,混淆度最低。论文结果可为进一步研究人机协作系统提供重要方向。
论文地址:https://arxiv.org/abs/2110.08176
强化学习可持续无休地学习任何具有明确奖励(award)、动作(action)和状态(state)的任务。只要具备足够的计算能力和时间,强化学习智能体可根据所在的环境(environment)去学习出一组动作序列或“策略”,以实现奖励(award)的最大化。强化学习在玩游戏中的有效性,已得到很好的证明。
但强化学习智能体给出的游戏策略通常并不能很好地匹配真人队友的玩法。一旦组队合作,智能体执行的操作会令真人队友大感困惑。由此,强化学习难以应用于需各方参与者协同规划和分工的场景。如何弥合机器智能与真人玩家间存在的鸿沟,是人工智能社区正面对的一个重要挑战。
研究人员正致力于创建各种强化学习智能体,达到能适应包括其它强化学习智能体和人类在内的各合作方的行为习惯。
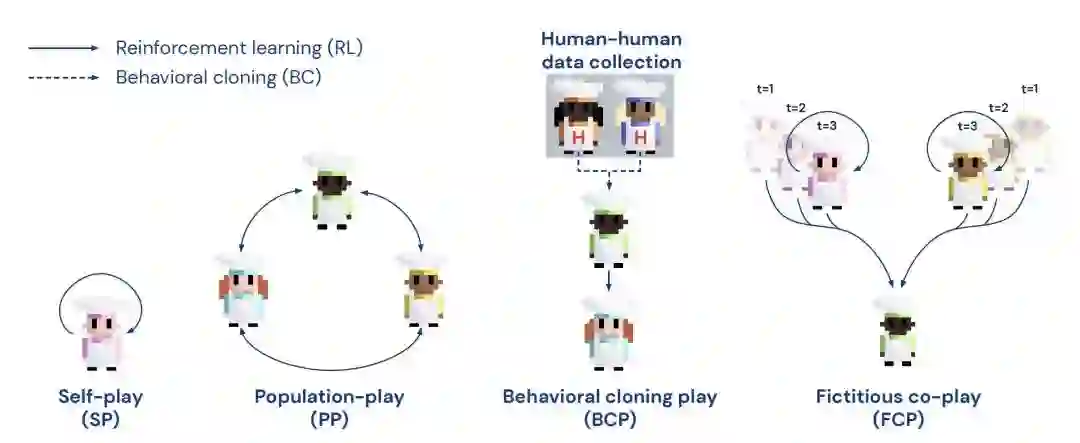
图 1 强化学习智能体的多种训练方法
SP 方法 (self-play,左右互搏法) 是游戏使用的经典强化学习训练方法。该方法让强化学习智能体与自身的一个副本持续对战,能非常高效地学习出实现游戏奖励最大化的策略。但该方法的问题在于,所生成的强化学习模型会过拟合智能体自身的游戏玩法,导致完全无法与使用其他方法训练的玩家合作。
另一种训练方法是 PP 方法 (popuation play,群体参与法),它在强化学习智能体训练中引入了多种具有不同参数和结构的队友模型。尽管在与真人玩家合作的竞技游戏中,PP 方法要明显地优于 SP 方法,但其依然缺乏应对“共同收益”(common-payoff)场景下的多样性(diversity)问题。“共同收益”指玩家必须协同解决问题,并根据环境变化去调整合作策略。
第三种方法称为 BCP 方法 (behavioral cloning play,行为克隆法),它使用人工生成的数据训练强化学习智能体。有别于在环境中随机选取起始点,BCP 方法根据采集自真人玩家的游戏数据去调整模型参数,使智能体生成更接近于人类玩家游戏模式的行为。如果可以采集具有不同技能水平和游戏风格玩家的数据,那么智能体就能更灵活地适应队友的行为,更有可能与真人玩家很好地配合。然而 BCP 方法的挑战性在于如何获取真人数据,特别是考虑到要使强化学习模型达到最佳设置,通常所需的游戏量是人工所无法企及的。
DeepMind 新提出的强化学习 FCP 方法,其关键理念是在无需依赖于人工生成数据的情况下,创建可与具有不同风格和技能水平玩家协作的智能体。
FCP 方法的训练分为两个阶段。首先,DeepMind 研究人员创建了一组使用 SP 方法的强化学习智能体,分别在不同的初始条件下独立完成训练,使模型收敛于不同的参数设置,由此创建了一个多样化的强化学习智能体池。为实现智能体池中技能水平的多样化,研究人员保存了每个智能体在不同训练阶段的快照。
正如论文所述,“最后一个检查点表示的是一个经完全训练的‘熟练’玩家,而较早的检查点则代表技能尚不纯熟的玩家。需说明的是,使用多个检查点实现各个玩家技能的多样性,这并不会导致的额外训练成本。”
第二个阶段使用池中所有的智能体,训练出一个新的强化学习模型。新智能体必须达成策略上的调优,才能实现与具有不同参数值和技能水平的队友开展协同。论文提出,“FCP 智能体完全可以达到跟随真人玩家带队,在给定范围的策略和技能中去学习出一个通用的策略。”
DeepMind 的人工智能研究人员将 FCP 方法应用于解谜游戏 Overcooked。游戏玩家在网格化场景中移动,与物体互动,执行一系列步骤,最终完成烹饪和送餐任务。Overcooked 的游戏逻辑简单,并需要队友间的协作和工作分配,因此非常适合测试。
为测试 FCP 方法,DeepMind 研究人员简化了完整的 Overcooked 游戏任务。他们精心挑选了一组具有多种挑战的地图,包括强制协作和受限空间等。
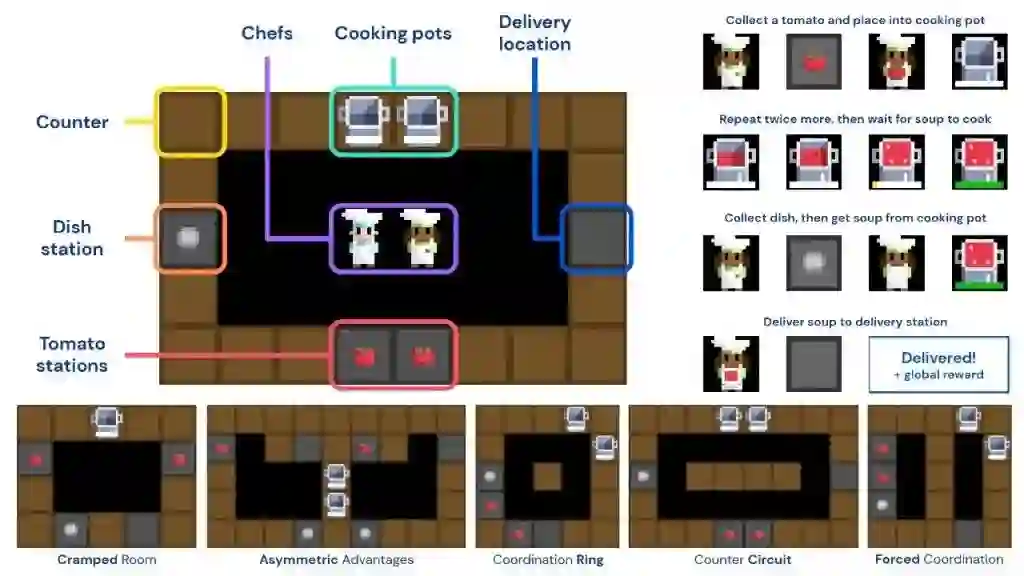
研究人员分别训练了一组 SP、PP、BCP 和 FCP 智能体。为了比较各方法的性能,他们首先组了三个队,分别测试每种强化学习智能体类型,即基于人类游戏数据训练的 BCP 模型、在不同技能水平上训练的 SP 智能体,以及代表低水平玩家的随机初始化智能体。测试根据在相同数量剧集中所能提供的餐食数,衡量各方法的性能优劣。
结果表明,FCP 方法的表现要明显优于其他强化学习智能体训练方法,可以很好地泛化各种技能水平和游戏风格。出乎意料的是,测试进一步表明了其他训练方法是非常脆弱的。正如论文所述,“这意味着其他方法可能无法达到与技能水平一般的玩家组队。”
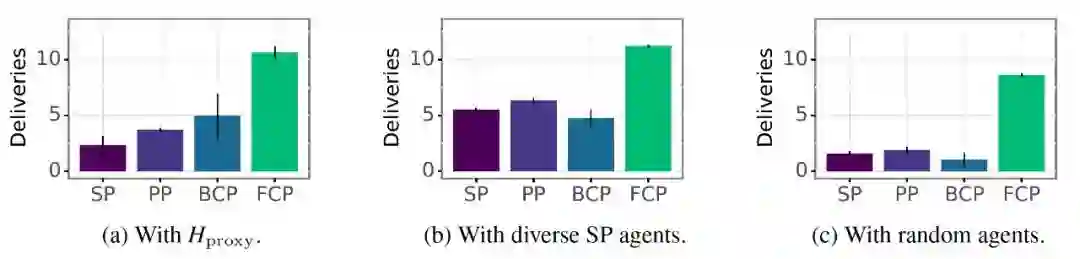
论文进而测试了每种类型的强化学习智能体在与人类玩家合作中的表现。研究人员开展了有 114 名人类玩家参加的在线研究,其中每位玩家参与 20 轮游戏。在每一轮游戏中,玩家与其中一种强化学习智能体组队,但并不知道该智能体的具体类型,随机进入一个厨房场景。
根据实验结果,“人类 -FCP”组队的性能,要优于其他所有“人类 - 强化学习智能体”组队。
每两轮游戏后,参与玩家根据与强化学习智能体组队的体验,给出一个 1 到 5 之间的评分。相对其他智能体,参与玩家对 FCP 队友表现出明显的偏好。反馈表明,FCP 智能体的行为更加连贯、更好预测,适应性更强。例如,强化学习智能体似乎具备了感知队友行为的能力,在每个烹饪场景中选择了特定角色,避免相互产生混淆。
与之相比,其他强化学习智能体的行为则被测试参与者描述为“混乱无章,难以合作”。

图 4 DeepMind 使用各种强化学习智能体与人类玩家组队
在论文中,研究人员也指出了该工作的一些局限性。例如,在 FCP 智能体的训练中,只使用了 32 个强化学习合作队友。尽管这完全可应对简化版的 Overcooked 游戏,但应用于更复杂的环境时可能会受限。DeepMind 研究人员指出,“对于更复杂的游戏,为表示足够多样化的策略,FCP 所需合作伙伴的总体规模可能难以企及。”
奖励定义是限制 FCP 应用于更复杂环境的另一个挑战。在简化版 Overcooked 中,奖励是简单而且明确的。但在其他环境中,强化学习智能体在获得主要奖励前,必须去完成一些子目标。而智能体实现子目标的方式,必须要与人类合作伙伴的方式保持一致。这在缺少人类数据的情况下,是很难去评估和调优的。研究人员提出,“如果任务的奖励函数与人类处理任务的方式非常不一致,那么和所有缺少人类数据的方法一样,该方法同样很可能会生成非最优的合作伙伴。”
DeepMind 的研究可归为人机协作领域研究。在麻省理工学院科学家的一项最新研究中,探索了强化学习智能体在与真人玩家玩纸牌游戏 Hanabi 中的局限性。
DeepMind 提出的强化学习新技术,在弥合人类和人工智能间鸿沟上取得了进步。研究人员希望其“能为未来研究人机协作造福社会这一重要挑战奠定坚实的基础。”
原文链接:
https://bdtechtalks.com/2021/11/22/deepmind-reinforcement-learning-fictitious-coplay/

你也「在看」吗?👇



