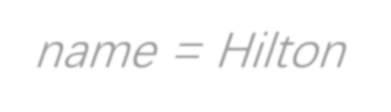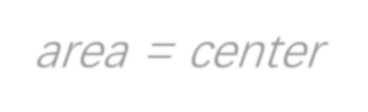As a crucial component in task-oriented dialog systems, the Natural Language Generation (NLG) module converts a dialog act represented in a semantic form into a response in natural language. The success of traditional template-based or statistical models typically relies on heavily annotated data, which is infeasible for new domains. Therefore, it is pivotal for an NLG system to generalize well with limited labelled data in real applications. To this end, we present FewShotWoz, the first NLG benchmark to simulate the few-shot learning setting in task-oriented dialog systems. Further, we develop the SC-GPT model. It is pre-trained on a large set of annotated NLG corpus to acquire the controllable generation ability, and fine-tuned with only a few domain-specific labels to adapt to new domains. Experiments on FewShotWoz and the large Multi-Domain-WOZ datasets show that the proposed SC-GPT significantly outperforms existing methods, measured by various automatic metrics and human evaluations.
翻译:作为任务导向对话系统的一个关键组成部分,自然语言生成模块将以语义形式表示的对话行为转换成自然语言的响应。传统模板或统计模型的成功通常依赖于大量附加说明的数据,这对新领域来说是行不通的。因此,对于国家语言生成模块系统来说,关键是要在实际应用中以有限的标签数据进行广泛推广。为此,我们提出了WhotWoz,这是第一个用于模拟任务导向对话系统中的微小学习设置的NLG基准。此外,我们开发了SC-GPT模型。它预先培训了一套庞大的附加说明的NLG系统,以获得可控的生成能力,并只对少数特定域标签进行微调,以适应新的领域。对WhotWoz和大型多域-WoZ数据集的实验表明,拟议的SC-GPT大大超越了以各种自动指标和人文评估衡量的现有方法。