基于自回归填空的通用语言模型预训练 | 论文荐读
作者:
Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. GLM: General Language Model Pretraining with Autoregressive Blank Infilling. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL 2022).
Code & Data:
https://www.aminer.cn/pub/622819cdd18a2b26c7ab496a
近年来,在互联网文本上预训练的大规模语言模型大大提高了各种 NLP 任务的最新技术水平,比如在英文维基百科上训练的 BERT 模型,提出时在各种自然语言理解的排行榜上取得了第一名的成绩,在某些任务上甚至取得了 10% 以上的提升。同时,预训练模型的参数规模也在不断增大。2019 年谷歌的 T5 模型首先达到了百亿参数的规模,在多个领域取得了最佳的性能。2020 年 OpenAI 发布的 GPT-3 模型将预训练语言模型的参数提高到了千亿级别,并且展示了惊人的小样本学习能力。然而,现有的预训练模型分为自编码模型、自回归模型和编码器-解码器模型三类,分别适用于自然语言理解、长文本生成和条件文本生成三类任务。没有一种预训练模型可以在所有任务上取得最优的效果。
针对上述问题,我们提出了一个基于自回归填空的通用预训练框架(General Language Modeling,GLM)。通过在一个统一的框架中同时学习双向和单向的注意力机制,模型在预训练阶段同时学习到了上下文表示和自回归生成。在针对下游任务的微调阶段,我们也通过完形填空的形式统一了不同类型的下游任务,从而实现了针对所有自然语言处理任务通用的预训练模型。
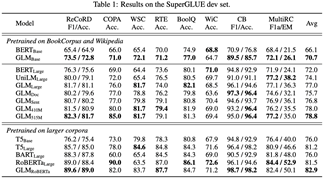
我们首先在 SuperGLUE 自然语言理解数据集上进行了评测。从表中我们可以看到,在等量的训练数据下,GLM-Base 的分数比 BERT-Base 要高 4.6%,GLM-Large 的分数比 BERT-Large 要高 5.0%。在同时引入更多的训练数据之后,GLM-RoBERTa 能够超过 T5-Large 的性能,但是只有 T5-Large 一半的参数规模。

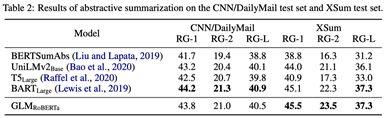
然后我们在条件文本生成任务上进一步评估了 GLM 的多任务能力。我们在两个文本摘要数据集 CNN/DailyMail 和 XSum 上进行和测试。结果见下表。可以看出,GLM-RoBERTa 可以取得和 seq2seq 预训练模型 BART 相当的性能,并且稳定超过 T5-Large 模型。
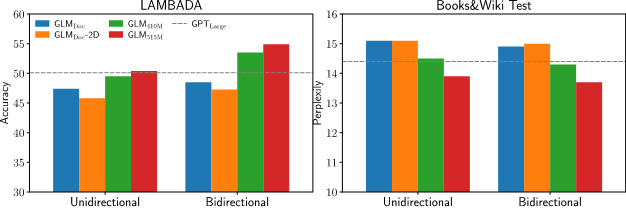
最后我们测试了在语言建模任务上测试了 GLM 的长文本生成能力。可以看出在加入长填空任务之后 GLM 的性能可以接近同等参数的GPT模型。同时,1.25 倍参数的 GLM 模型可以同时在三类任务上取得最优的效果。
点击【阅读原文】查看代码数据




