
论文名称:A Survey on Natural Language Processing for Programming论文作者:朱庆福,罗先镇,刘芳,高翠芸,车万翔原创作者:罗先镇,朱庆福论文链接:https://arxiv.org/pdf/2212.05773.pdf转载须标注出处:哈工大SCIR
摘要 自然语言处理技术正越来越多地被应用于辅助程序开发,这极大提升了编程效率。本文围绕编程语言的两大核心特点:结构性和功能性,系统梳理了将自然语言处理技术应用于编程领域的研究进展,内容涵盖任务定义、数据集构建、评估方法、关键技术以及代表性模型等诸多方面,以期为读者全面展现这一新兴交叉领域的研究现状。
引言
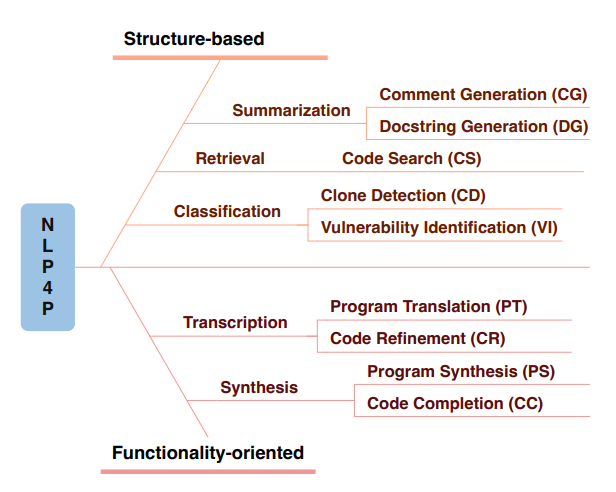
面向编程的自然语言处理(NLP4P)是自然语言处理和软件工程的交叉领域,旨在利用自然语言处理技术辅助程序开发。它能让程序员从繁琐的工作中解放出来,如自动生成文档;也让非专业用户获得更便捷的编程体验,如通过自然语言实现代码生成。诸如此类的应用使得NLP4P可以显著提升整个社会的生产力。 不同于自然语言,编程语言有两个本质特点:结构性(structure-based)和功能性(functionality-oriented)(如图1所示)。结构性指编程语言拥有复杂的结构,如层次、循环、递归等,对其进行恰当建模是理解程序的关键。功能性指程序应将输入转化为预期输出,执行特定功能,而设计面向功能的算法是生成正确程序的核心。这两个特性是常规自然语言技术没有考虑或者涉及的,如何将这两个特性很好地结合是NLP4P的一个基本课题。

虽然已经有从预训练角度的综述,但是这两个特性对于NLP4P还未被充分探讨过。本文将从这两个特性出发,系统阐述它们在NLP4P各个层面(任务、数据集、评估、技术和性能)的作用,并说明未来的潜在方向。
任务
数据集
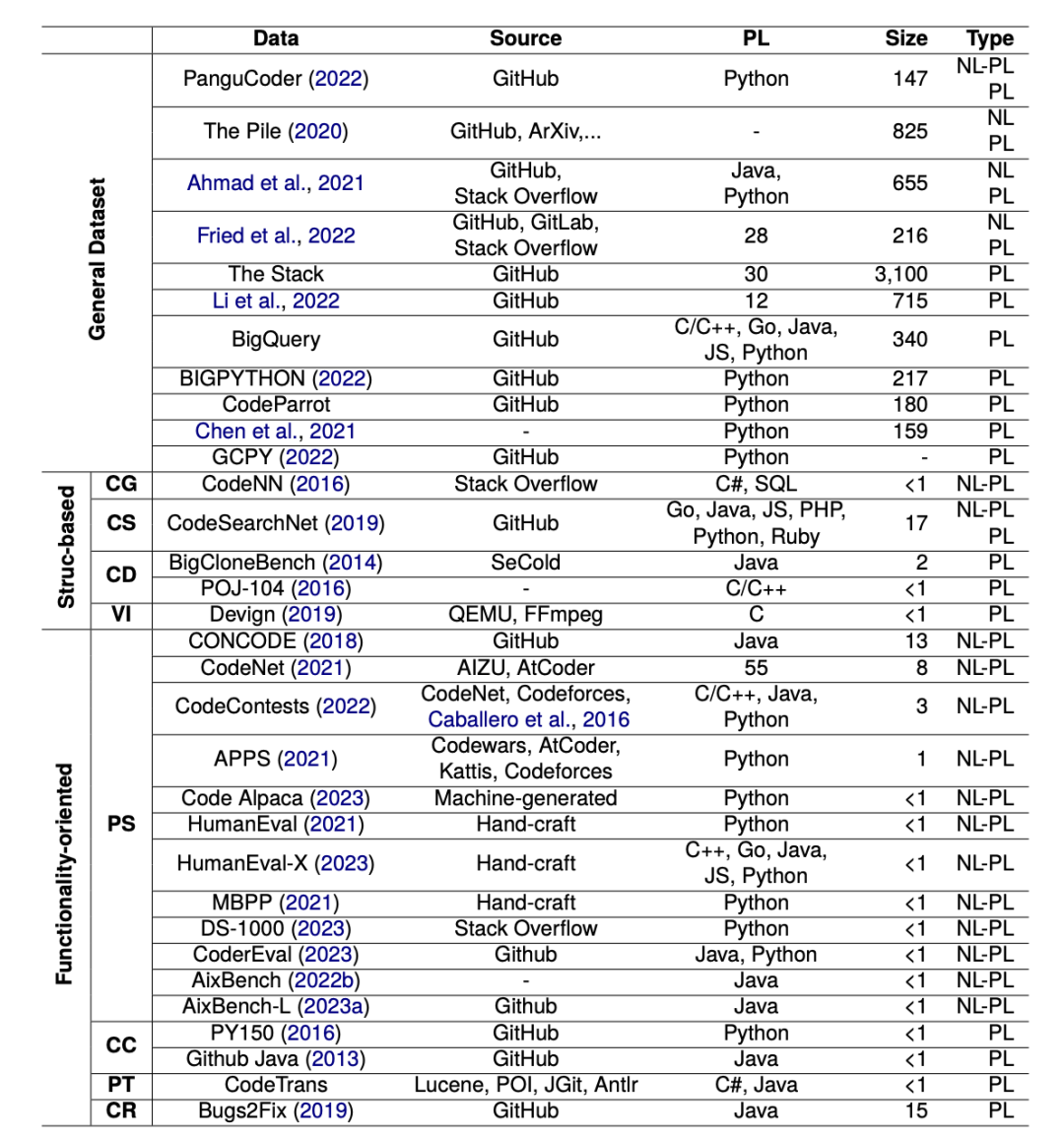
高质量的数据集是NLP4P研究得以持续深入的根本保障。我们从数据的分类、内容等角度对现有数据集进行了系统盘点,力求为研究者们提供一个全景式的参考。 我们首先根据任务的分类,将数据集分为通用数据集、基于结构的数据集和面向功能的数据集。通用数据集来自开源平台(如GitHub、GitLab等)和社区网站(如StackOverflow),规模庞大且预处理较少,更适合用于语言模型的预训练阶段,以学习通用的编程知识。然而,这些数据有时也会包含较多噪声,如内容空泛的提交记录,与问题无关的代码片段等,对后续任务造成干扰。因此,如何在保证规模的同时提高数据质量,是构建通用数据集需要考虑的重要问题。 基于结构的数据集则经过了面向特定任务的预处理和标注。例如,通过现有的开源解析工具提取程序的抽象语法树、控制流图等结构化表示,用以支持代码摘要、克隆检测等任务。这些数据集相对更加干净和贴合任务需求,但在通用性和规模上不如第一类数据集。因此,如何在有限的人工标注资源下最大化数据的效用,是这类数据集的重点优化方向。 面向功能的数据集则更加强调对程序功能的精准刻画。为了评估生成程序的正确性,这些数据集通常为每个样例配备了相应的测试用例。构建这样的数据集需要大量专业知识和工程投入,因此目前主要依赖人工方式,或从在线测评系统中获取。尽管高度匹配任务需求,但这类数据集的规模普遍较小,多样性有限,泛化能力还有待验证。同时,测试用例的设计本身也存在主观性和盲点。如何以更加自动化、智能化的方式扩充程序功能评测的维度和深度,是一个值得长期探索的问题。 除了数据的分类,数据的内容上也需要重视。根据数据集中包含的语言类型,现有数据集可以分为平行数据集和单边数据集。平行数据集包含成对的自然语言和编程语言,体现了两类语言在语义层面的紧密联系,主要用于把自然语言作为需求来源的任务,如程序合成、代码搜索等。而单边数据集则主要由编程语言或者自然语言构成,分别适用于聚焦程序内容本身或程序文本描述的任务。值得注意的是,平行数据的构建本身就是一个需要大量知识和经验的过程。因此,平行数据集在语义对齐性上普遍要优于单边数据集。
评估
对于NLP4P中的不同任务,其评估方法各有侧重,主要可以分为自然语言(NL)评估和编程语言(PL)评估两大类。 对于以NL为输出的任务,例如代码摘要,评估通常参考传统NLP领域的方法。常见的自动评估指标包括BLEU、MENTOR和ROUGE,这些都是通过比较生成文本与参考文本之间的相似度来进行的。然而,这些自动评估指标可能与实际文本质量相关性较弱。因此,人工评估在此类任务中至关重要,可以补充自动评估的不足。人工评估侧重于几个独立的维度,如自然性、多样性和信息量,提供更精确、细致和全面的评估。尽管人工评估更为耗时和劳动密集,但它能够对测试集的小部分进行更深入的分析。 与NL评估不同,PL评估主要关注程序的功能性和正确性。其中一个方法是基于参考的评估,将编程语言通过类似于自然语言的n-gram基准进行评估。为了更好地捕捉到结构性属性,CodeBLEU指标考虑了抽象语法树和数据流图。此外还有基于测试用例的评估方法。主要的两个基于测试用例的指标是测试用例平均通过率和严格准确率。测试用例平均通过率计算所有样本的平均测试用例通过率。严格准确率是一个更为严格的指标,只有当程序通过所有测试用例时,才被视为接受,其最终的严格准确率是被接受程序的比例。为了提高性能,我们可以为每个样本生成多个程序版本,并根据测试用例筛选出最佳程序。 综上所述,NL评估更侧重于生成文本的质量和可读性,而PL评估则侧重于代码的功能性和正确性。在NLP4P领域中,根据任务的不同特点选择合适的评估方法,对于提高研究成果的有效性和实用性至关重要。
技术
NL与PL之间的差异性要求我们在处理PL时需要更多的设计。首先,理解程序内容的关键在于适当地表达其结构信息;其次,程序生成的核心是精心设计算法以实现功能上的正确性。因此,我们分别介绍基于结构的理解和面向功能的生成两种技术手段。 5.1 基于结构的理解 与自然语言相比,编程语言具有更复杂的结构,如层次结构、循环和递归。通常,可以通过适当的数据结构明确表示这些结构,如相对距离、抽象语法树(AST)、控制流图(CFG)、程序依赖图和代码属性图等。例如,Ahmad等(2020)提出将源代码序列中两个标记之间的相对距离表示为可学习的嵌入,并将其引入到Transformer模型中作为注意力机制偏置。结果表明,相对距离是捕捉结构信息的有效方法。此外,AST是一种包含程序语法和结构的树状信息表示,它可以简化解析树中的非必要部分(如括号),但AST可能由于深层层次结构而导致解析时间延长并增加输入长度。 5.2 面向功能的生成 不同于自然语言,编程语言是可执行的,需要将输入转换为预期输出以实现特定功能。确保功能正确性的技术涵盖了整个模型开发过程,包括准备指令微调数据(自指导,Self-Instruct)、生成(交互式编程)和后处理(采样和过滤)。例如,Chaudhary(2023)采用自指导方法来自动构建名为Code Alpaca的指令-代码数据集。同时,evol-instruct是一种进化指令方法,将现有样本进化为更复杂和多样的样本。此外,交互式编程是一个渐进式范式,可以通过将问题分解成几个简单的子问题并逐步解决来进行交互。为了进一步提高功能正确性,NLP4P发展了一种基于采样的范式,首先生成大量候选程序,然后通过基于测试用例的过滤和聚类技术来选择所需程序。为了确保覆盖所需程序,首先采样数量应尽可能大,其次最好使用带有温度参数的标准采样或Top-K采样算法而不是生成候选程序相似度较高的束搜索。过滤掉未通过测试用例的程序,得到最终结果。 5.3 主干模型 面向功能性的算法通常是模型无关的,与主干模型相关的更多的是结构性。RNN以及变体LSTM可以处理线性的token序列。但面对非线性结构时,转化成线性结构往往意味着信息的损失。比如AST的先序遍历是无法恢复出AST的。针对这个问题,SBT( structure-based traversal )通过在遍历结果上加括号来表示层次信息,Multi-way Tree-LSTM直接将AST作为输入,对每个子节点用标准LSTM处理之后再用Tree-LSTM汇总到父节点上。类似的操作在CNN上也被提出,TBCNN(tree-based convolutional neural network)通过权重和位置特征编码AST。Transformer在捕捉长距离依赖上效果显著,而PL恰好会在很长的代码中出现较远的依赖关系。其他的主干模型比如前馈神经网络、递归神经网络、图网络也被用于捕捉PL的结构(AST)。但是当面临较大规模的数据时,Transformer是唯一的选择。
代表性的预训练模型
SOTA的预训练模型可以根据使用测试集的不同分为两类。一类是使用CodeXGLUE的,更加关注代码的结构;一类是使用HumanEval,更加关注代码的功能正确性。我们也根据基于结构还是面向功能,将模型分为两类。 基于结构的模型:GraphCodeBERT、Unxicoder和CodeT5在训练时加入了PDG或AST的信息,而encoder-only的CodeBERT,和encoder-decoder架构的PLBART并没有加入PL的结构信息。相比之下,加入了结构信息的模型会有更高的性能。Unixcoder在理解任务上效果最好,CodeT5在生成上性能卓越。但是当面对代码生成任务时,面向功能的模型是更好的选择。CodeGen2.5,CodeT5+,StarCoder和Code Llama在HumanEval上的结果如图4所示。Instruct和Python的中缀分别代表在SFT数据和Python数据上进一步训练的版本。可以看出,参数是影响模型性能的主要因素。随着参数量的增加,模型性能是不断提升的。Python版本的结果也说明在专一语料上进一步训练也可以获得提升。
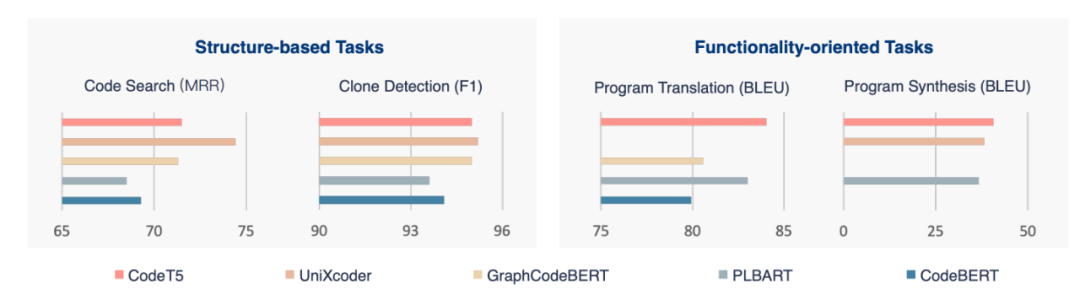
图 3. 不同模型在CodeXCLUE上各个任务的性能。
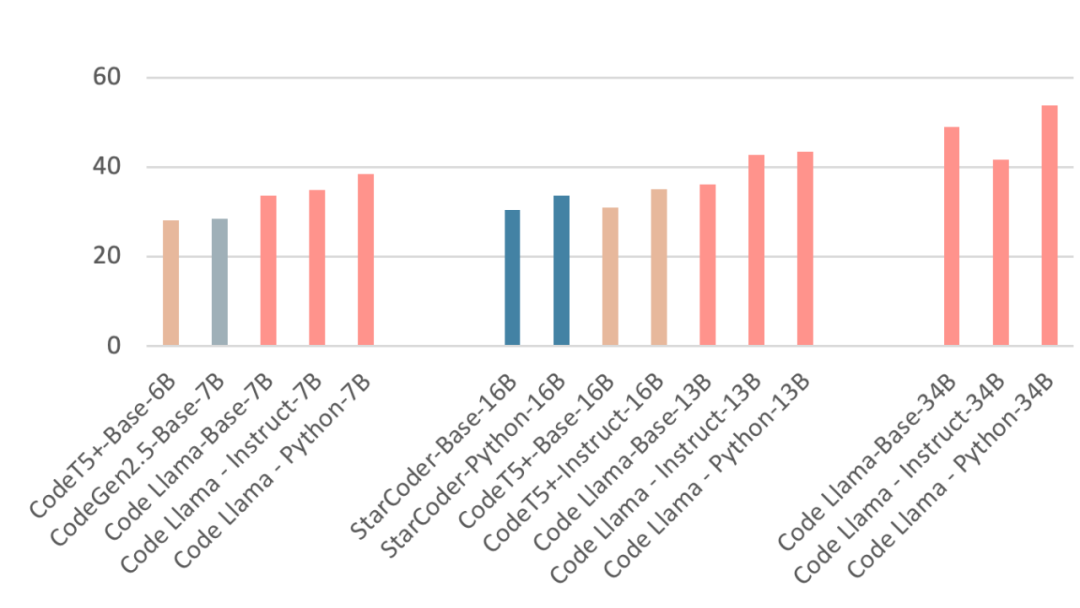
图 4. 不同版本的模型在HumanEval上的结果。
未来的发展方向
尽管NLP4P已经获得很大的进展,但是SE和NLP领域的一些特性还没有被有效利用。比如多语言和多模态。虽然GitHub上有海量的数据,但是其中编程语言的分布是非常不均衡的,而且自然语言大部分都是英语。低资源的代码语言和自然语言性能明显低于平均性能。简单的解决办法是在使用时将低资源语言翻译成高资源语言,但是这不但会引入额外的工作量,翻译过程还可能会导致错误的累积。多语言的方法将各种语言表示到统一的语义空间,可以用于解决这个问题。NL的表述有时需要其他模态来辅助理解,比如经典的图论问题—七桥问题,很难通过语言描述。多模态的核心在于模态之间的对齐,但是,目前NLP4P领域缺少这样的数据集,而重新标注又面临着巨额成本。因此,如何利用现有的多模态数据集和模型的知识是一个关键的问题。
总结
我们从基于结构和面向功能两个方面,系统地回顾了整个NLP4P领域,包括任务、数据集、技术和模型等等。结构性是选择主干模型的主要因素,而功能性是评估的核心。在最后,我们也指出了未来的发展方向。
