赛尔译文 | 基础模型的机遇与风险 (三)
原文:On the Opportunities and Risks of Foundation Models
链接:https://arxiv.org/pdf/2108.07258.pdf
译者:哈工大 SCIR 张伟男,朱庆福,聂润泽,牟虹霖,赵伟翔,高靖龙,孙一恒,王昊淳,车万翔(所有译者同等贡献)
转载须标注出处:哈工大 SCIR

-
引言 -
能力 -
应用 3.1 医疗保健和生物医学 3.2 法律 3.3 教育 -
技术 -
社会 -
结论
 图12 医疗保健和生物医学的基础模型。我们可视化了一个交互式框架,其中基础模型在采用医疗保健生态系统中各种来源生成的多模态数据进行训练时,可以实现跨医疗保健和生物医学的各种任务。第一列列出了多个数据来源,包括护理服务提供方、付款人、机构(大学、非营利组织和政府)、制药、可穿戴设备和医学出版物/论坛。第二列显示了数据源生成的几种数据模态。它们包括图像(例如,胸部X光片)、视频(例如超声波)、化合物图表、电子健康记录 (EHR) 表格、临床记录等文本、如ECG这样的时间序列,和遗传数据。第三列将基于此类数据训练的基础模型可视化,然后应用于第四列中列出的医疗保健和生物医学下游任务。这个过程可以生成新的数据,进一步改进基础模型,从而形成基础模型和任务之间的双向关系
。
图12 医疗保健和生物医学的基础模型。我们可视化了一个交互式框架,其中基础模型在采用医疗保健生态系统中各种来源生成的多模态数据进行训练时,可以实现跨医疗保健和生物医学的各种任务。第一列列出了多个数据来源,包括护理服务提供方、付款人、机构(大学、非营利组织和政府)、制药、可穿戴设备和医学出版物/论坛。第二列显示了数据源生成的几种数据模态。它们包括图像(例如,胸部X光片)、视频(例如超声波)、化合物图表、电子健康记录 (EHR) 表格、临床记录等文本、如ECG这样的时间序列,和遗传数据。第三列将基于此类数据训练的基础模型可视化,然后应用于第四列中列出的医疗保健和生物医学下游任务。这个过程可以生成新的数据,进一步改进基础模型,从而形成基础模型和任务之间的双向关系
。
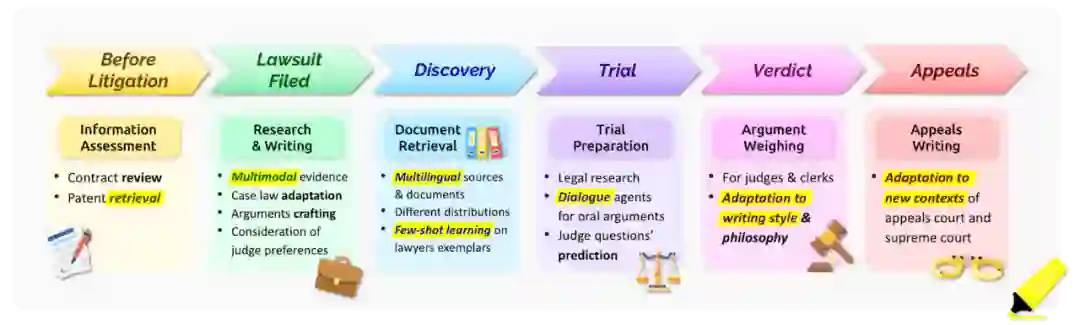 图13 美国民事案件各个步骤的示例以及基础模型可能有帮助的地方。在每个阶段,可能需要处理不同的模态,并且需要适应新的法院制度或法律要求。
图13 美国民事案件各个步骤的示例以及基础模型可能有帮助的地方。在每个阶段,可能需要处理不同的模态,并且需要适应新的法院制度或法律要求。
49 由于作者的专业知识,我们的讨论仅限于在美国的法律应用。然而,这里的一些讨论可能适用于全球的法律场所。
50 我们注意到,在本节中,我们认为基础模型是指任何自监督的预训练模型,它被用来快速适应新的环境,几乎没有监督学习。关于扩展的定义,也请参见 §1: 引言和 §2.6: 哲学中的讨论。
51 https://spot.suffolklitlab.org/
52 https://www.kirkland.com/publications/article/2020/04/technology-assisted-review-framework
53 例如,在法庭上讲非裔美国人的英语方言已被证明是审判期间偏见的潜在来源。https://www.nytimes.com/2019/01/25/us/black-dialect- courtrooms.html
54 例如,在 People v. Superior Court (Vasquez), 27 Cal.App.5th 36 (2018) 中,一名被告在 17 年里没有得到审判,因为公设辩护人办公室的预算严重削减,人员不足。法院裁定,公设辩护人办公室的系统性故障构成了对正当程序的违反,被告的案件被驳回了。
 图14
一位作者所写的一份虚构的辩护状的摘录。法学专业学生被指导写辩护状的原型形式包括。(1)介绍论点;(2)以有说服力的方式陈述法律规则;(3)将法律规则应用于案件事实;(4)有说服力地总结论点。这往往需要从以前的案件和当前的案件事实中进行信息检索和转述。
图14
一位作者所写的一份虚构的辩护状的摘录。法学专业学生被指导写辩护状的原型形式包括。(1)介绍论点;(2)以有说服力的方式陈述法律规则;(3)将法律规则应用于案件事实;(4)有说服力地总结论点。这往往需要从以前的案件和当前的案件事实中进行信息检索和转述。
55 https://www.americanbar.org/groups/public_education/publications/teaching-legal-docs/how-to-read-a-u-s– supreme-court-opinion/ 56 https://www.supremecourt.gov/casehand/courtspecchart02162010.aspx 57 https://www.stanfordlawreview.org/submissions/article-submissions/

58 例如,一条规则可能是这样的:对于没有结婚也不是未亡配偶的个人,第 (1) 和 (2) 款的适用方法是用 750 美元代替 600 美 元。美国《国内税收法》(IRC)第 63(f)(3) 条。
59 对于律师事务所和法律技术公司来说,那些已经可以实现高性能并且可因此更直接地产品化的任务,可能被认为更值得进行昂贵的人工标注。
60 参见 Vieira et al. [2020] 的讨论。 61 例如,Vasquez,美国一案中, 编号为 3: 16-cv-2623-D-BN(Dist. Court, ND Texas 2019),律师依靠谷歌翻译来证明前任律师(母语者)对认罪协议的翻译有误。
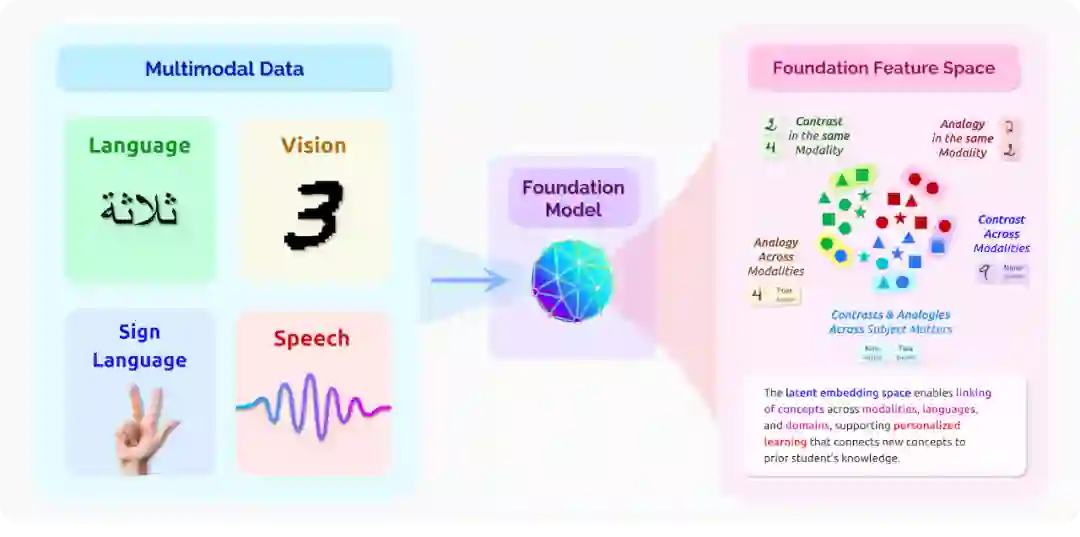 图15 教育领域的基础模型可以在多个数据源上进行训练,以学习教育所需的能力:对各种主题的理解和不同的教学技术。
这些基础模型可以以通用的方式应用于一系列的任务和目标,如了解学生、协助教师和生成教育内容。
图15 教育领域的基础模型可以在多个数据源上进行训练,以学习教育所需的能力:对各种主题的理解和不同的教学技术。
这些基础模型可以以通用的方式应用于一系列的任务和目标,如了解学生、协助教师和生成教育内容。
62 这个学生犯了一个常见的错误,就是把个位数和十位数相加的结果连在一起。
图16 该图说明了一个将各种模态(图像、语音、手势、文字)和语言的信号嵌入一个通用的特征空间的系统。
这样一个特征空间允许思想在不同的模态和语言之间被联系起来。
与教学相关的链接类型包括类比(不同语言间的相似性)和对比(不同语言间的不同概念),这两种类型都可以发生在同一模态或不同模态间。
63 2013 年,Facebook 启动了Free Basics 项目,向全世界提供免费互联网,从而传播机遇和互联互通。现在,联合国人权理事会报告说,在缅甸,Facebook 在没有适当的人为节制的情况下努力贯彻这种愿望,加速了仇恨言论,煽动了分裂,并在罗兴亚人的种族灭绝中煽动了线下暴力。Free Basics 现在成为技术对社会影响的复杂性的一个警告。
登录查看更多
相关内容
Arxiv
2+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月19日





相关VIP内容
相关资讯
相关论文
Arxiv
2+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月19日