CVPR2020 | 单目深度估计中的不确定度探究
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文作者:晓silence
https://zhuanlan.zhihu.com/p/141540812
本文已由原作者授权,不得擅自二次转载
论文标题:On the uncertainty of self-supervised monocular depth estimation

论文链接:https://arxiv.org/abs/2005.06209
开源代码(已开源):
https://github.com/mattpoggi/mono-uncertainty
本文是我对这篇论文的翻译以及理解,可能会有理解不到位或者错误的地方,欢迎各位批评指正,互相讨论。如需转载请联系本人
上次也贴出过一篇CVPR2020的论文阅读——D3VO,只是写了深度估计的部分,没有写后面的直接法SLAM部分,主要是SLAM相关的知识不够扎实,害怕理解不够到位,所以只在深度估计相关的部分做了阐述。那篇文章中主要用到的就是ECCV2018提出来的对数似然估计函数,然后将整个网络的结果放在了直接法SLAM中。这一篇主要是利用多种现有的方法来进行不确定度的估计。
作者在他的论文中提出的贡献点主要有三个:

提出了与深度估计有关的不确定度的评价方法
主要研究了这种自监督学习对不确定度估计以及深度估计的影响
提出了一种self-teaching的方法,来对不确定度进行建模,这种方法在姿态未知的情况下,十分有用,通常可以提高深度的估计准确度
1. 深度估计中,多种不确定度的建模方法
1.1 Uncertainty by image flipping ( Post )
这种方法是利用图像翻转来进行不确定度的估计的,训练的时候只训练一个模型,在测试的时候会得到两个深度图像 



这里将深度图的不确定度定义为翻转前后两个图的差:

这种好处就是,对原始的网络不用经过任何的修改,只需要在进行inference的时候进行两次forward就行了,这种方法得到的就是小样本上的方差。

1.2 Empirical estimation
这一部分的不确定度估计,主要是进行模型集成,通过不同的方法训练出多个不同的模型,根据不同模型对同一张图片的预测,统计最后的均值以及方差。
Dropout Sampling ( Drop )
这一部分是对比较熟悉的dropout的一个变化,我们比较熟悉的dropout实在训练阶段进行dropout但是在测试阶段会使用全部的特征,而文中的方法是在测试阶段依旧保留dropout,进行多次深度估计然后估计得到方差和均值:
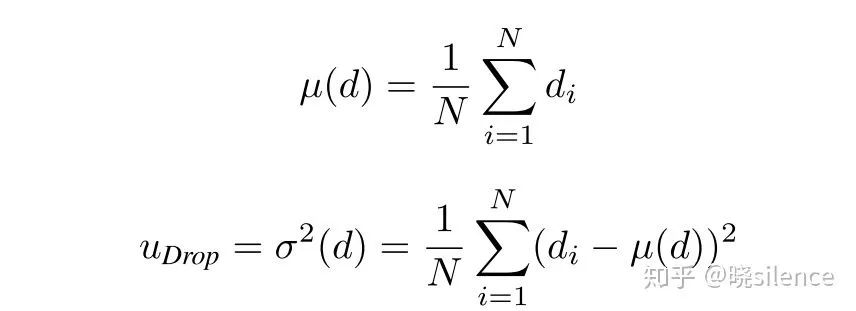
这种方法需要经过N次的inference,然后最后得到相关的分布情况。
Bootstrapped Ensemble ( Boot )
这种方法是利用不同的初始化参数,初始化多个不同的网络,然后进行训练,训练以后利用dropout里面对均值和不确定度估计的方法进行估计,但是这种方法是需要经过N次的training得到不同的模型,然后利用drop的式子进行均值以及方差的估计。N次的training需要的成本过于高昂。
Snapshot Ensemble ( Snap )
这篇文章是2017年在ICLR上的一篇文章,作者是densenet的一作,这篇CVPR的文章中也就采用了这种训练一次得到多个模型的思路,进行了对上述的 Boot 方法需要多个初始化得到多个模型的弊端进行了改进,利用的是余弦退火法,通过周期性地改变学习速率以得到多个不同的模型,使用的学习速率的公式为:
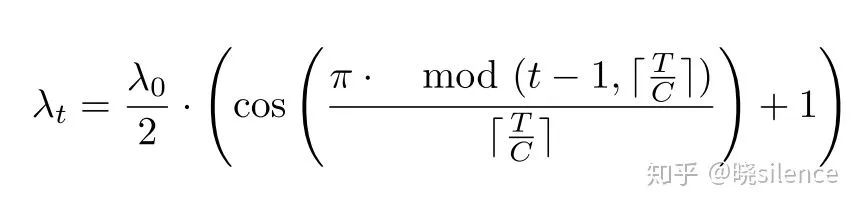
其中T是需要训练的总步数,C是保存的模型数,然后作者是从C个保存的模型中,抽取N个模型,进行了平均值和方差的统计,统计方法和 drop 相同
1.3 Predictive estimation
这一部分的方法是学习到一个可以预测不确定度的模型,不确定度就是模型的输出。
Learned Reprojection ( Repr )
这个方法是我不是很明白的一个方法,添加了的不确定度,似乎是反应哪一点的loss比较大,就说明哪一点估计的不够准确,提出的loss如下:
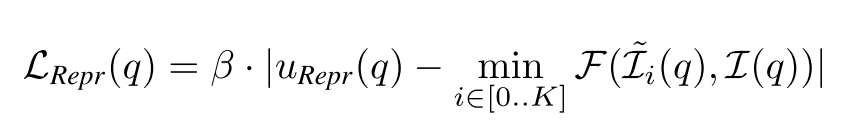
其中设置了 

Log-Likelihood Maximization ( Log )
这个loss也就是对误差进行了建模,直接从网络里面输出一个不确定度,如果是L1 loss就建模成Laplician分布如果是L2 loss就建模成Gaussian分布,这个是最后得到的loss公式为
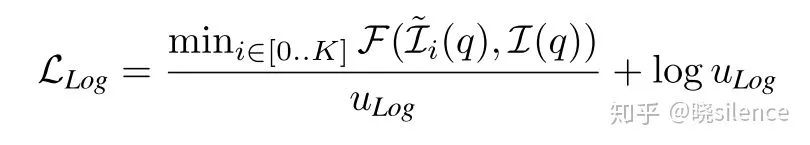
不过在利用这个公式进行训练的时候,loss会出现负值,这个是正常现象。作者在文中说,这个loss在训练双目的时候和传统的监督loss是一样的,因为在双目训练的时候只有一个未知数是
Self-Teaching (Self)
上一个利用Log的方法同时没有办法把深度和姿态的不确定度进行解耦,作者提出了利用teacher-student framework来解耦这两个不确定度。首先利用自监督的办法学习一个 

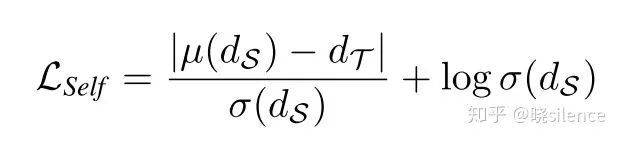
也就是说,第一个是原来的训练方法,第二个是类似监督的训练方法整个网络的训练的pipeline为:
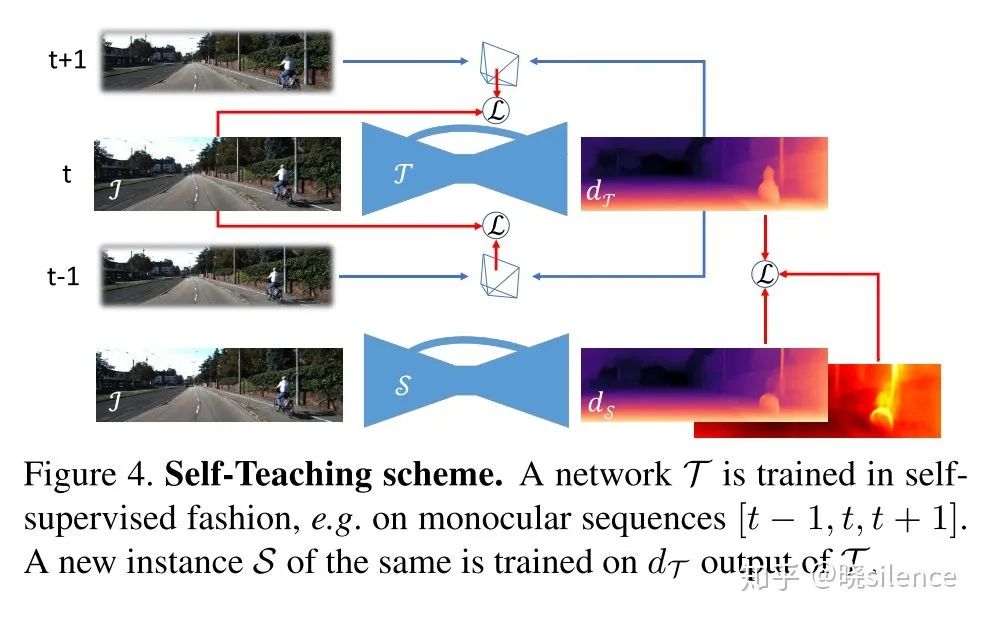
利用这种方法将两个网络进行了解耦,并且最终训练出来的
1.4 Bayesian estimation
再Bayesian深度学习框架中,模型的不确定性可以解释为边缘化所有可能的 
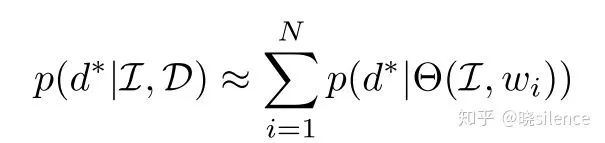
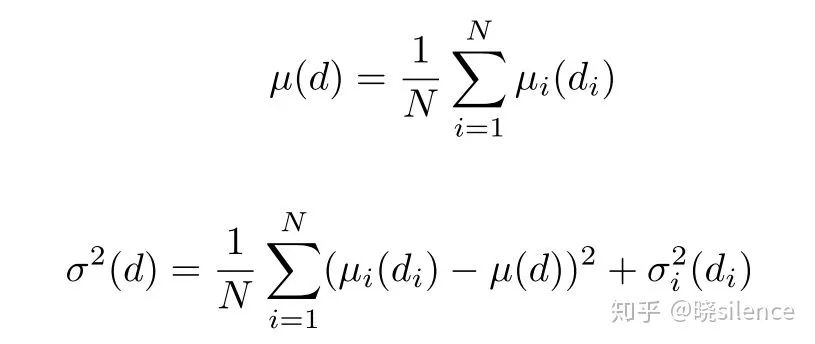
文章选用最好的 Boot 以及 Self 来进行建模的。(这一部分的解释非常含糊,最好看以下原始的那篇论文,加深理解)
2. 实验部分
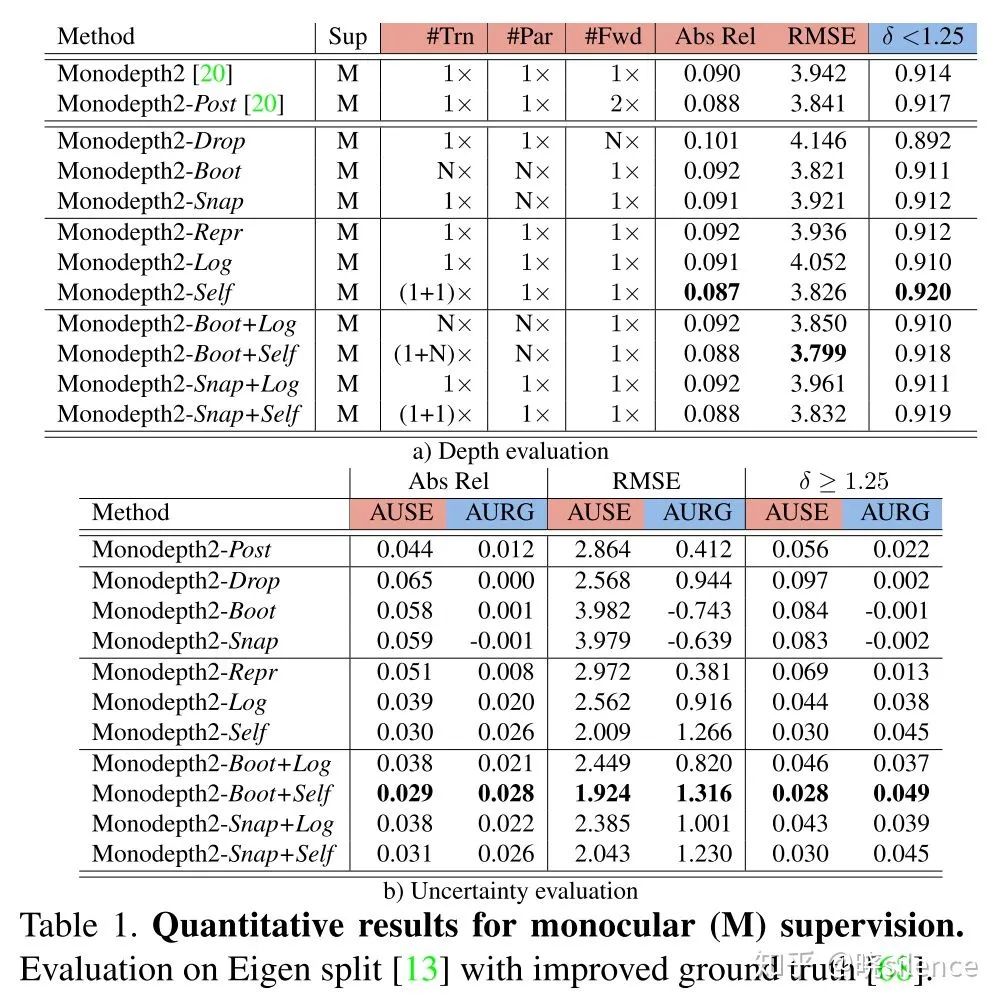
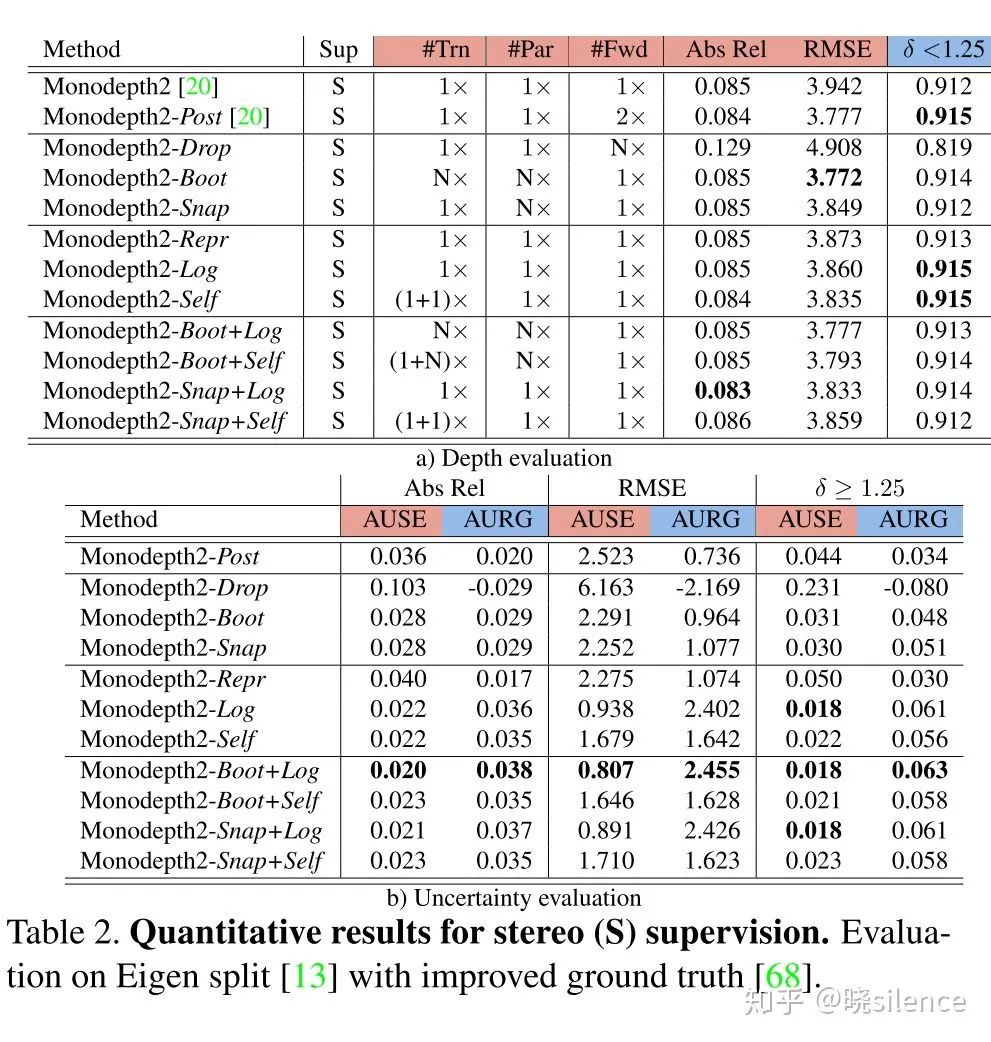
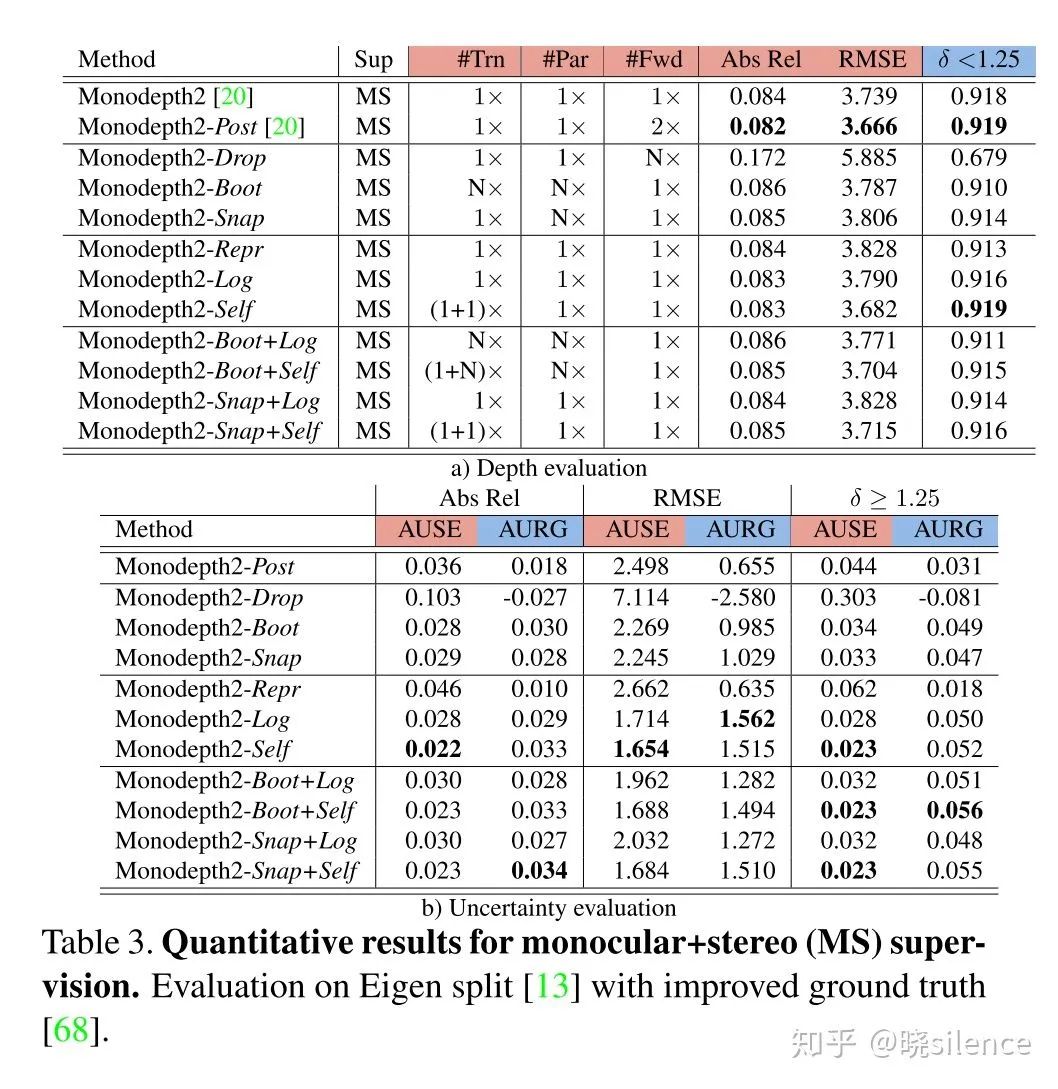
整个网络的框架是采用的monodepth2,在这篇文章的README里面有相关的链接,在empirical estimation里面N=8,C=20,dropout只在decoder部分使用了,boot部分只使用了训练集的25%进行单独模型的训练,然后在predictive estimation里面将输出的通道数增加了1。详细可以看论文里面的实验设置。
2.1 Uncertainty metrics
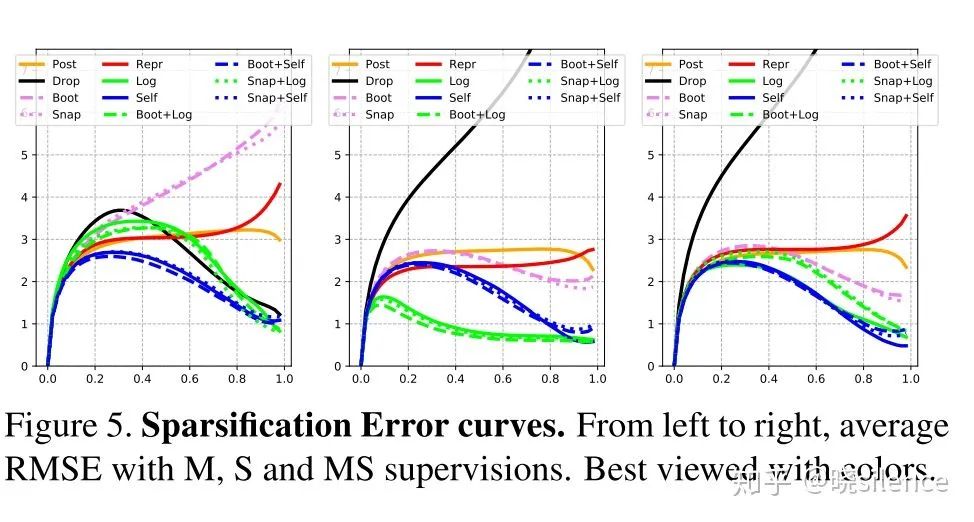
深度的一些评价指标在所有的论文里面都有,这篇文章的另一个贡献点就是提出了深度估计相关的不确定度的评价指标。对于不确定度的评价,文章中主要采用了sparsification plots的做法,主要步骤如下:
将深度图像按照不确定度的降序进行排序,然后每次取掉这些深度值的一小部分(不放回),然后对剩下的部分进行误差的计算。(文章中是按照2%的点进行抽取的)这种方法就可以计算不确定度低的地方是不是计算出来的误差也会比较低。
同时绘制一个理想的曲线,理想的 sparsification plot 是根据误差矩阵的降序进行绘制的,也就是和上面采用相同的办法,抽取掉一部分误差高的点,用剩下的点计算误差,这条曲线文中成为oracle。(这块的意思就是,抽取掉的不确定度高的点和抽取掉的误差高的点曲线的差距)
提出了两个评价指标AUSE以及AURG,AUSE是Area Under the Sparsification Error,越低越好,计算方法就是用不确定度的曲线(1中获得的)减去oracal曲线,主要评价不确定度和实际的误差的关系,AURG是Area Under the Random Gain,越高越好,其中一条曲线是在所有点计算出来的误差,不进行任何删除,另一条曲线就是1中的曲线,用不删除的曲线减去1中的曲线,如果相差越大证明不确定度估计是有效果的
文章中选用的评价指标有三个,分别是Abs Rel, RMSE, 

其余的部分可以看文章,里面有更多的实验数据以及Supplementary Material里面的一些说明会更为详细,个人觉得这篇文章虽然用的方法基本都是别人提出来的,不过实验确实十分充分,对11中方法(其中有组合的)进行了实验,并且提出的评价指标后续可能可以用得上,现在自监督的不确定度估计很大程度上都是做出来这个估计,但是没有实际的用处,而且到底不确定度是不是可靠的,还是说只是一个噱头,其实是不明确的,至少这个文章开了一个头,后面应该可以用很多基于这个的工作放出来。
还有最最重要的是开源了,后续关于复现的问题,我会再更新。
论文下载
在CVer公众号后台回复:Mono,即可下载本论文
重磅!CVer-深度估计 交流群已成立
扫码添加CVer助手,可申请加入CVer-深度估计微信交流群
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如深度估计+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
请给CVer一个在看!

