CVPR 2018 | 伯克利等提出无监督特征学习新方法,代码已开源

在有类别标注的数据上进行训练的神经网络分类器可以捕获明显的类间视觉相似性,而不需要人为引导。这篇论文研究的是这种情况是否可以扩展到传统的监督学习领域之外:可不可以仅仅通过让单个实例的的特征具有判别性,来学习一个好的特征表示,捕捉实例间的相似性,而不是类间的。
作者将这个想法描述成实例级别的非参数分类问题,使用噪声对比估计来应对大量实例类别带来的计算挑战。实验结果显示,在无监督学习设置下,该方法在现有的 ImageNet 分类问题上的表现相比于其他方法得到了大幅提升。在训练数据更多,网络架构更好的情况下,该方法也可以不断地显著提高表现性能。通过微调学习到的特征,算法进一步在半监督学习和目标识别任务上取得了更好的结果。非参数模型非常紧凑:每张图片 128 维特征,对于 100 万张图像,此方法只需要 600M 存储空间,算法在运行时可以进行快速的最近邻检索。
更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
随着深度神经网络的崛起,尤其是卷积神经网络,为计算机视觉领域带来了重大突破。大多数模型是通过监督学习训练的,需要完整标注的大量数据集。然而,获取标注数据的代价是十分高的,在某些情况下甚至是不可行的。因此在近几年,无监督学习受到了越来越多的关注。
我们非监督学习的想法源自于对目标识别任务的监督学习结果的观察。在 ImageNet 数据集上,top-5 分类误差远远低于 top-1 分类误差,而 softmax 输出的可能性第二高的结果与测试图像视觉相关性极高。

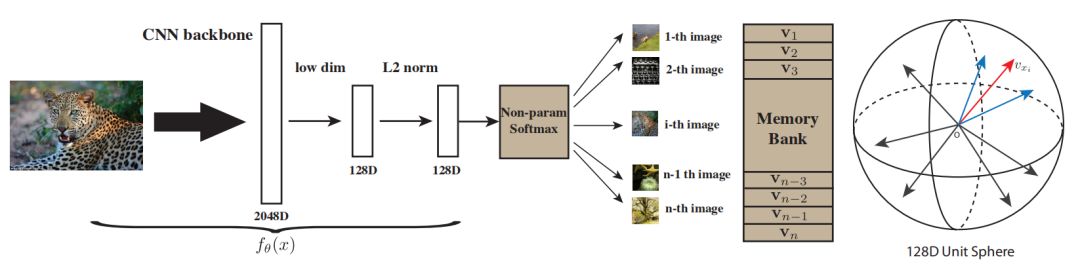
图 1 对于一张类别为“美洲豹”的图像,训练的神经网络分类器中得分最高的几类往往是视觉相关的,例如“美洲虎”和“非洲猎豹”。数据中的明显相似性拉近了这些类之间的距离。我们的无监督方法将类标级别的监督信息应用到极致,学习出能够区分单个实例的特征。
我们提出了一个问题:是否能够通过纯粹的判别学习来得到一个能够反应实例间明显相似性的度量?如果我们学习判别不同的实例,即使没有语义类别的标注,我们也能得到能捕捉实例间明显相似性的表示。
然而我们面临一个主要的挑战,即我们现在的“类别”数目,变成了整个训练集。例如 ImageNet,会成为 120 万类而不是 1000 类。单纯在 softmax 层扩展到更多类是不可取的。我们通过用噪声对比估计(NCE)估计完整的 softmax 分布,然后通过近似正则化方法来稳定学习过程。
过去衡量非监督学习的有效性通常依赖线性分类器,例如 SVM。然而如何能保证通过训练学习到的特征在未知的测试任务上是线性可分的呢?
我们认为对于训练和测试任务都应该采用非参数的方法。我们将实例级判别视作度量学习问题,其中实例之间的距离(相似度)以非参数的方式由特征直接计算。也就是说,每个实例的特征被存储在离散的存储组中,而不是网络中的权重。在测试时,我们使用基于 K- 近邻(KNN)对学习到的度量进行分类。我们的训练和测试是一致的,因为模型的学习和评价都涉及图像之间的相同度量空间。实验结果显示,我们的方法在 ImageNet 1K 数据库上的 top-1 准确率达到了 46.5%,在 Places205 数据库上达到了 41.6%。
我们的目标是学习一个无监督内嵌函数:
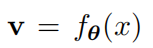
f 是深度神经网络,参数为θ,将图片 x 映射为特征 v。这一内嵌函数为图像 x 和 y 的空间引入一个度量:
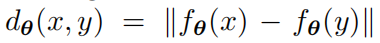
一个好的内嵌函数应该能将具有视觉相似性的图像映射到度量空间相近的位置。
我们的无监督特征学习方法为“实例级别判别”。我们将每张图片实例视作属于它自己的一类,然后训练分类器来区分不同的实例类别。
假设我们有 n 张图,属于 n 类,以及它们的特征 v1,…vn。在传统的参数 softmax 中,对于图像 x 的特征 v,它被归为 i 类的概率为: 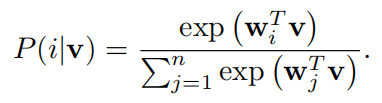
其中 wj 是类别 j 的权重向量,wTv 衡量 v 与 j 类实例的匹配程度。
公式(1)中,问题在于权重向量 w 作为类别原型,阻碍了实例间的对比。
我们提出公式(1)的非参数变体,用 vTv 取代 wTv。那么 v 属于 i 类的概率为: 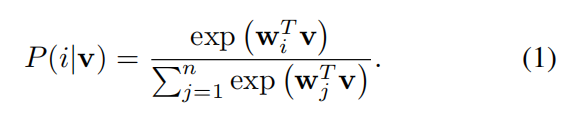
学习目标就变成了最大化联合概率:
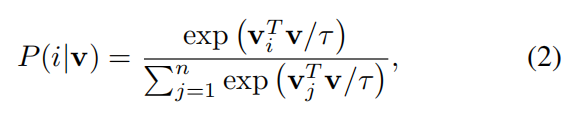
或等同于最小化它的负对数似然值:
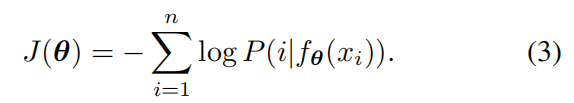
要计算(2)式中的概率,需要用到所有图像的特征。如果每次都对这些特征进行计算,计算量太大,我们采取一个特征存储组 V 来存储特征。假设 fi 为图像 xi 输入网络 fθ的特征,在每一次学习迭代中,fi 和网络参数θ通过随机梯度下降优化。随后更新 V 中对应实例的特征,将 vi 更新为 fi。我们将存储组 V 中的所有表示初始化为单元随机矢量。
从类别权重矢量 wj 到特征表示 vj 的概念变化是很重要的。原始的 softmax 方程中的{wj}只对训练类别有效。因此它们无法泛化到新类别,或者新的实例。当我们去掉这些权重矢量后,我们的学习目标完全关注于特征表示和它所引入的度量,可以在测试时用于任何新的实例。在计算方面,我们的非参数方法消除了计算和存储权重矢量梯度的需求,使模型更易扩展至大型数据应用场景。
计算公式(2)中的非参数 softmax 的成本十分高,尤其是类别数量很大时。因此我们采用噪声对比估计(noise-contrastive estimation,NCE)来估计全部的 softmax。
我们将 NCE 进行一定的修改,使其更适合我们的模型。为了解决需要与训练集中所有实例计算相似度这一难题,我们将多类别分类问题变成一系列二分类问题,二分类任务需要判别数据样本和噪声样本。在我们的模型中,存储组中的特征 v 对应第 i 个样例的概率为:
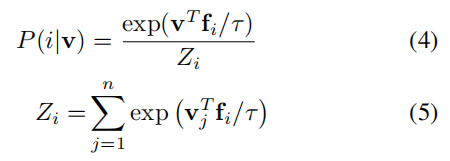
其中 Zi 是正则化常数。我们将噪声分布设置为均匀分布:
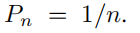
我们假设噪声样本比数据样本要多 m 倍,那么样本 i 的特征是 v 的后验概率则为:
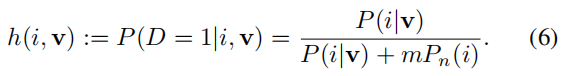
我们估测的训练目标是最小化数据样本和噪声样本的负对数似然分布:
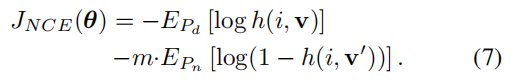
其中 Pd 代表实际数据分布。对于 Pd,v 是对应图像 xi 的特征,而对于 Pn,v’是另外一张图像的特征,根据噪声分布 Pn 随机采样得到。在我们的模型中,v 和 v’都从无参数存储组 V 中采样得到。
我们将 Zi 视作常数,通过蒙特卡洛估计来计算它,以减少计算量:
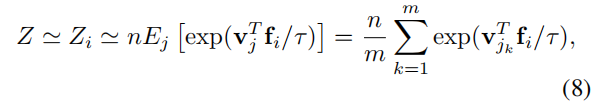
NCE 方法将计算复杂度从每样本 O(n) 降到了 O(1)。虽然降低幅度很大,但是我们的实验依然能够产生不错的结果。
与传统的分类不同,我们的每一个类别下只有一个实例。因此每一个训练 epoch 每一类都只访问一次。因此,学习过程由于随机采样波动会产生大幅震荡。我们采用近段优化方法并且引入一个额外项鼓励训练机制的平滑性。在第 t 次迭代时,数据 xi 的特征表示从网络中计算得到:
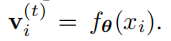
所有表示的存储组存储在上一次迭代中:
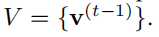
对于 Pd 中的正样本,损失函数为:
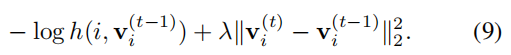
随着学习收敛,不同迭代之间的差距逐渐消失,增加的损失减少至最原始的一个。通过近段正则化,我们最终的目标函数变为:
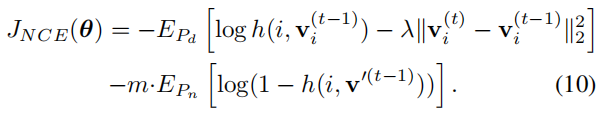
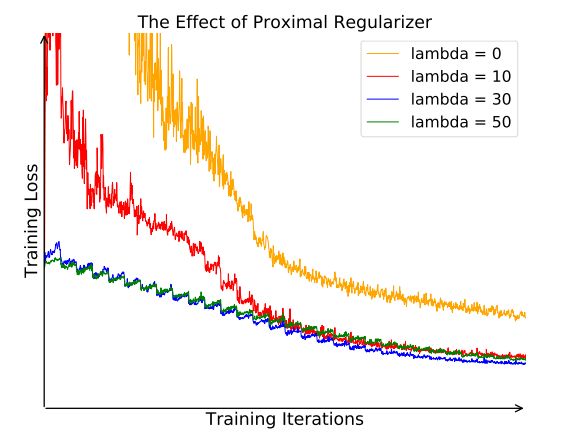
图 3 近段正则化的效果。原始的目标函数值震荡幅度很大,并且收敛很慢,而正则化的目标函数则有更平滑的学习动态。
要分类测试图像 x,我们首先计算它的特征 f=fθ(x),然后将它和存储组中的所有图像的内嵌函数对比,使用余弦相似度 si=cos(vi, f)。前 k 个近邻,用 Nk 表示,随后被用于加权投票进行预测。类别 c 会获得一个总权重:
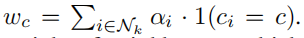
其中αi 是近邻 xi 的贡献权重,与相似度相关。
我们通过 4 组实验来验证我们的方法。第一组是在 CIFAR-10 数据库上,对比我们的非参数 softmax 和参数 softmax。第二组在 ImageNet 上,与其他无监督学习方法对比。最后两组实验分别进行半监督学习和目标检测任务,以证明我们的方法学习到的特征的泛化能力。
我们在 CIFAR-10 数据库上对比参数和非参数方法,CIFAR-10 含有 50000 个训练实例,一共 10 类。我们使用 ResNet18 作为主干网络,将其输出特征映射成 128 维矢量。我们基于学习到的特征表示来评价分类有效性。常用方法是用学习到的特征训练一个 SVM 分类器,然后通过对网络提取的特征进行分类来对测试实例进行分类。除此之外,我们使用最近邻分类器来评测学习到的特征。后者直接依赖于特征度量,因此能更好地反映特征表示的质量。
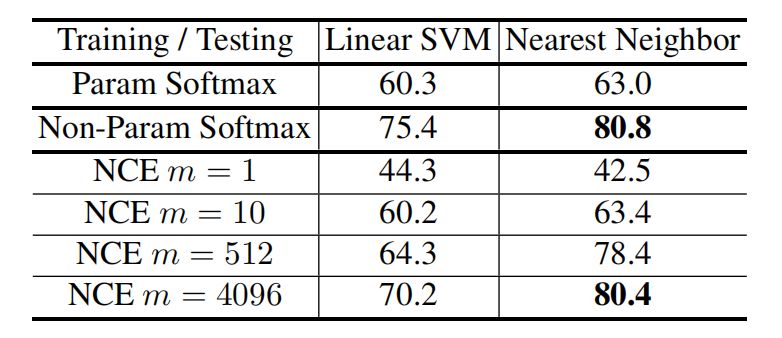
我们在 ImageNet ILSVRC 数据库上学习特征表示,然后将我们的方法和其他无监督学习代表方法进行对比。
我们选取一个随机初始化的网络,和其他无监督学习方法,包括自监督学习、对抗学习、样例 CNN。由于网络结构对算法表现有很大影响,我们考虑了几个经典的结构:AlexNet、VGG16、ResNet-18 和 ResNet-50。
我们评测了两个不同的方案:(1)对中层特征用线性 SVM 分类。(2)对输出特征用 kNN 分类器分类。
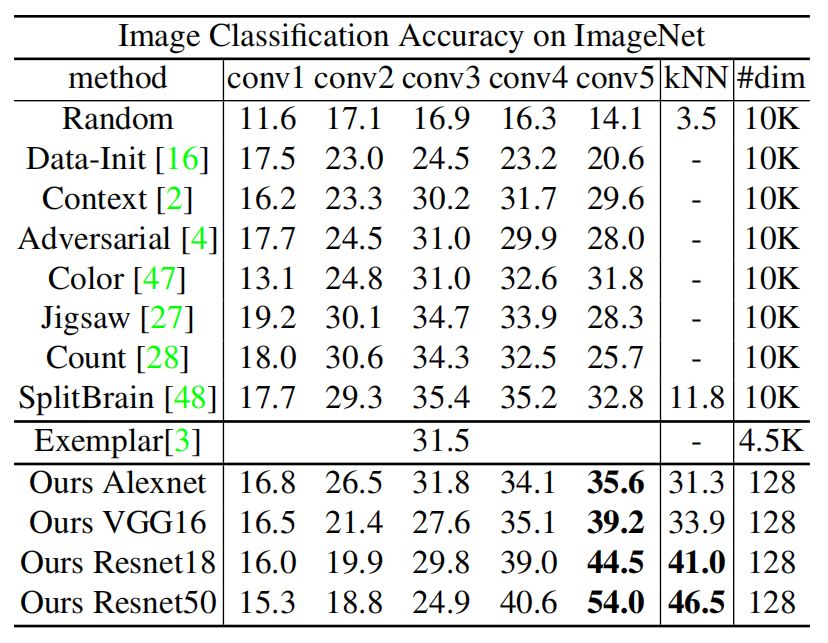
从表中可以看出:
利用线性分类器对 AlexNet 的中层特征进行分类时,我们的方法准确率达到了 35%,超过了所有方法。并且我们的方法随网络深度增加,可以很好的扩展。当网络从 AlexNet 变成 ResNet-50 时,我们的准确率达到了 54%,而用样例 CNN 结合 ResNet-101 时,准确率也仅有 31.5%。
使用最近邻分类器对最后的 128 维特征进行分类时,我们的方法在 AlexNet、VGG16、ResNet-18 和 ResNet-50 上识别率分别为 31.3%,、33.9%、41.0% 和 46.5%,与线性分类结果相近,表明了我们学习到的特征引入了合理的度量。
我们也研究了学习到的特征表示应该如何泛化到其他数据集。我们在 Places 数据库上做了另一个大型实验。Places 时场景分类数据集,包含 2.45M 张训练图片,共 205 类。表 3 对比了不同方法和不同评价策略的结果。
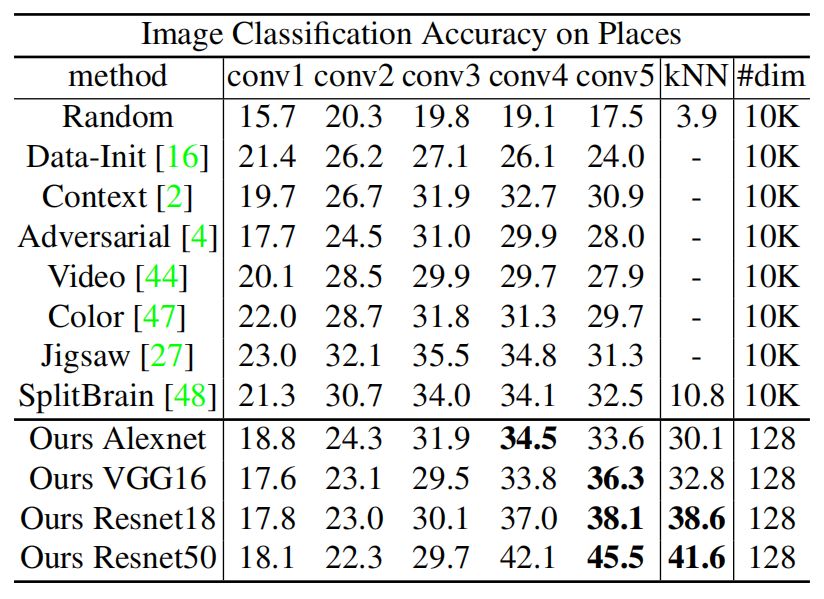
对 conv5 的特征利用线性分类器,我们的方法结合 AlexNet 得到的 top-1 准确率达到了 34.5%,用 ResNet-50 准确率达到了 45.5%。利用最近邻分类器对 ResNet-50 的最后一层分类,得到的准确率达到了 41.6%。结果显示了我们的方法学习到的特征具有良好的泛化能力。
无监督特征学习一直是难点,因为测试目标对于训练目标来说时不可知的。一个好的训练目标在测试中会连续提升。我们研究了训练损失和测试准确率随迭代次数的关系。
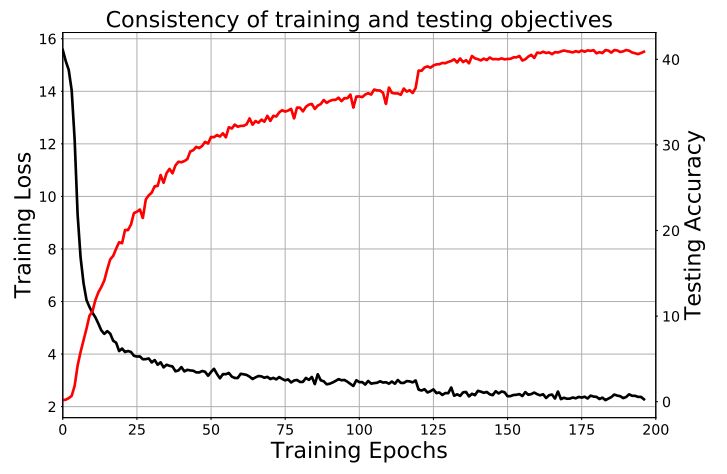
图 4 我们的 kNN 测试准确率在 ImageNet 数据集上随训练损失下降而持续增加,表明我们的无监督学习目标函数捕捉到了明显的相似性,与数据的语义标注能够良好匹配。
我们研究了内嵌特征维度从 32 到 256,算法效果的变化。表 4 显示,从 32 维开始,算法效果持续上升,在 128 维达到峰值,在 256 维趋于饱和。

我们用 ImageNet 的不同比例的数据集训练了不同的特征表示,然后用 kNN 分类器在全类标数据集上进行验证,研究我们的方法随数据集大小扩展的效果。表 5 显示了我们的特征学习方法在更大的数据集上效果更好,测试准确率随训练集增大而提高。这一特性对于有效的非监督学习方法十分重要,因为自然界最不缺的就是无标注数据。


我们研究了学习到的特征提取网络是否可以应用于其他任务,以及它是否可以作为迁移学习的一个好的基础。一般的半监督学习方法是首先从大量无标注数据中学习然后在少量有标注类标上进行微调。我们从 ImageNet 中随机选择一个子集作为标注数据,剩下的作为无标注数据。我们进行半监督学习,然后在验证集上测量分类准确率。
我们与 3 个基准方法做比较:(1)Scratch,在少量标注数据上进行全监督训练。(2)用 Split-brain 进行预训练。(3)用 Colorization 进行预训练。
图 6 显示了我们的方法性能明显优于其他方法,并且我们的方法是唯一一个超过监督学习的。当标注数据仅占 1% 时,我们超过其他方法 10%,证明了我们从无标注数据中学习到的特征对于任务迁移是有效的。
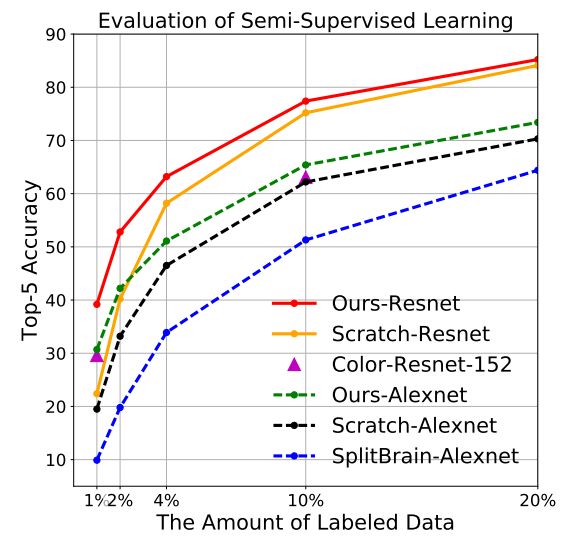
图 6 标注数据比例增加的半监督学习结果。我们的方法增加更连贯并且明显更好。
为了进一步评测学习到的特征的泛化能力,我们将学习的网络迁移至 PASCAL 目标识别任务上。从零开始训练目标识别网络十分困难,常用的方法是在 ImageNet 上预训练 CNN,然后对其进行微调。
我们对比了 3 种设置(1)直接从头开始训练(2)在 ImageNet 上进行无监督预训练(3)在 ImageNet 或其他数据上用各种无监督方法预训练。
表 6 列出了目标检测的 mAP。对于 AlexNet 和 VGG-16,我们的方法 mAP 分别达到了 48.1% 和 60.5%,与最好的无监督方法不相上下。用 ResNet-50,我们的方法 mAP 达到了 65.4%,超过了所有的无监督学习方法。这也证明了网络变深的时候,我们的方法可以很好的适应。
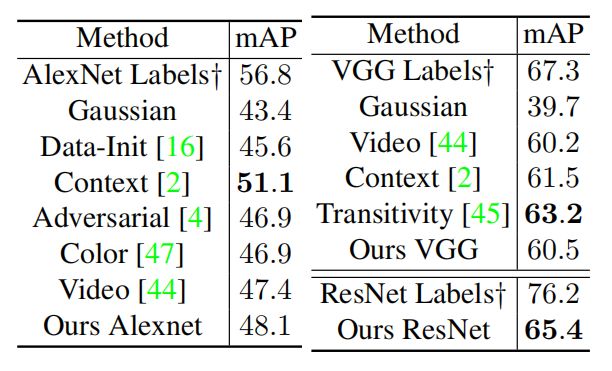
表 6 目标检测准确性,PASCAL VOC 2007 测试集。
我们提出了一种无监督的特征学习方法,通过一个新的非参数 softmax 公式来最大化实例之间的区别。它的动机来自于监督学习的能够得到明显的图像相似性这一观察。我们的实验结果表明,我们的方法在 ImageNet 和 Places 上的图像分类效果优于目前最先进的方法。特征用紧凑的 128 维表示,对更多的数据和更深的网络适应良好。在半监督学习和目标检测任务上,它也显示了良好的泛化能力。
查看论文原文:
https://arxiv.org/abs/1805.01978
Github 项目地址:
http://github.com/zhirongw/lemniscate.pytorch


如果你喜欢这篇文章,或希望看到更多类似优质报道,记得点赞分享哦!
┏(^0^)┛明天见!


