
论文题目: Attending to Entities for Better Text Understanding
论文作者: Pengxiang Cheng ,Katrin Erk
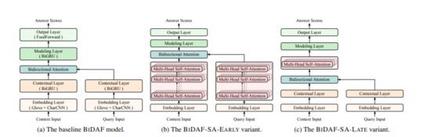
论文摘要: NLP的最新进展见证了大规模预训练语言模型(GPT,BERT,XLNet等)的发展。基于Transformer(Vaswani等人,2017),并在一系列最终任务中,此类模型取得了最先进的结果,接近人类的表现。当与足够多的层和大量的预训练数据配对时,这清楚地证明了堆叠式自我注意架构的强大功能。但是,在需要复杂而又长距离推理的任务上,表面水平的提示还不够,在预训练的模型和人类绩效之间仍然存在很大的差距。Strubell等。 (2018)最近表明,可以注入句法知识通过监督的自我注意将其构建为模型。我们推测,将语义知识(尤其是共指信息)类似地注入到现有模型中,将会提高此类复杂问题的性能。上在LAMBADA(Paperno et al.2016)任务中,我们显示了从头开始训练并同时作为自我注意的辅助监督的模型优于最大的GPT-2模型,并设置了新的最新技术,而仅包含与GPT-2相比,它只占很小一部分参数。我们还对模型架构和监督配置的不同变体进行了全面分析,为将类似技术应用于其他问题提供了未来的方向。
成为VIP会员查看完整内容
相关内容

专知会员服务
37+阅读 · 2020年3月14日
专知会员服务
49+阅读 · 2019年11月15日
Arxiv
3+阅读 · 2019年8月22日
相关主题



相关VIP内容
专知会员服务
37+阅读 · 2020年3月14日
专知会员服务
49+阅读 · 2019年11月15日
相关资讯
相关论文
Arxiv
3+阅读 · 2019年8月22日