
题目: Understanding Knowledge Distillation in Non-autoregressive Machine Translation
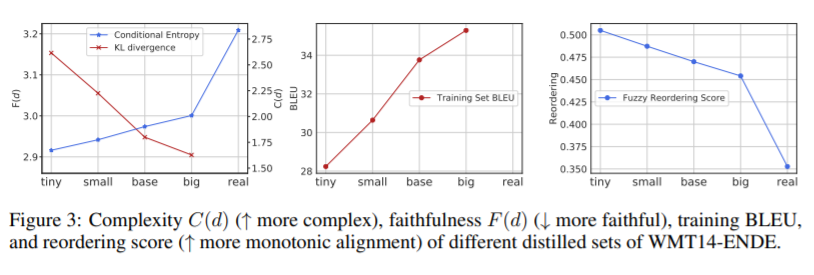
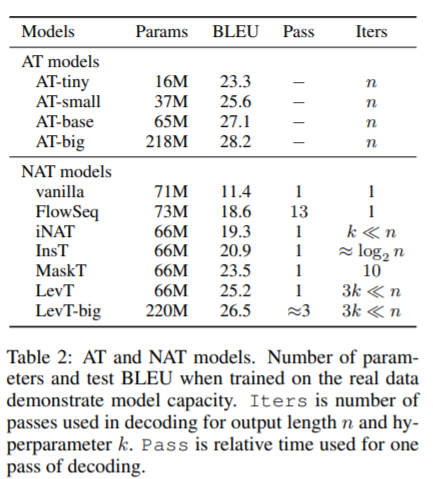
摘要: 非自回归机器翻译(NAT)系统并行地预测输出标记序列,与自回归模型相比,在生成速度上获得了实质性的改进。现有的NAT模型通常依赖于知识蒸馏技术,该技术从一个预先训练好的自回归模型中创建训练数据,以获得更好的性能。知识蒸馏在经验上是有用的,它使NAT模型的准确性得到了很大的提高,但是这种成功的原因到目前为止还不清楚。在这篇论文中,我们首先设计了系统的实验来研究为什么知识蒸馏对于NAT训练是至关重要的。我们发现,知识蒸馏可以降低数据集的复杂性,并帮助NAT对输出数据的变化进行建模。此外,在NAT模型的容量和为获得最佳翻译质量而提取的数据的最优复杂度之间存在很强的相关性。基于这些发现,我们进一步提出了几种可以改变数据集复杂性的方法,以提高NAT模型的性能。我们为基于nat的模型实现了最先进的性能,并缩小了与WMT14 En-De基准上的自回归基线的差距。
成为VIP会员查看完整内容

相关内容

Arxiv
4+阅读 · 2018年2月19日


相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年2月19日