简介: 今年AAAI 2020接收了1591篇论文,其中有140篇是与图相关的。接下来将会介绍几篇与图和知识图谱相关的几篇论文。以下为内容大纲:

- KG-Augmented Language Models In Diherent Flavours
Hayashi等人在知识图上建立了自然语言生成(NLG)任务的潜在关系语言模型(LRLM)。就是说,模型在每个时间步上要么从词汇表中提取一个单词,要么求助于已知关系。 最终的任务是在给定主题实体的情况下生成连贯且正确的文本。 LRLM利用基础图上的KG嵌入来获取实体和关系表示,以及用于嵌入表面形式的Fasttext。 最后,要参数化流程,需要一个序列模型。作者尝试使用LSTM和Transformer-XL来评估与使用Wikidata批注的Freebase和WikiText链接的WikiFacts上的LRLM。
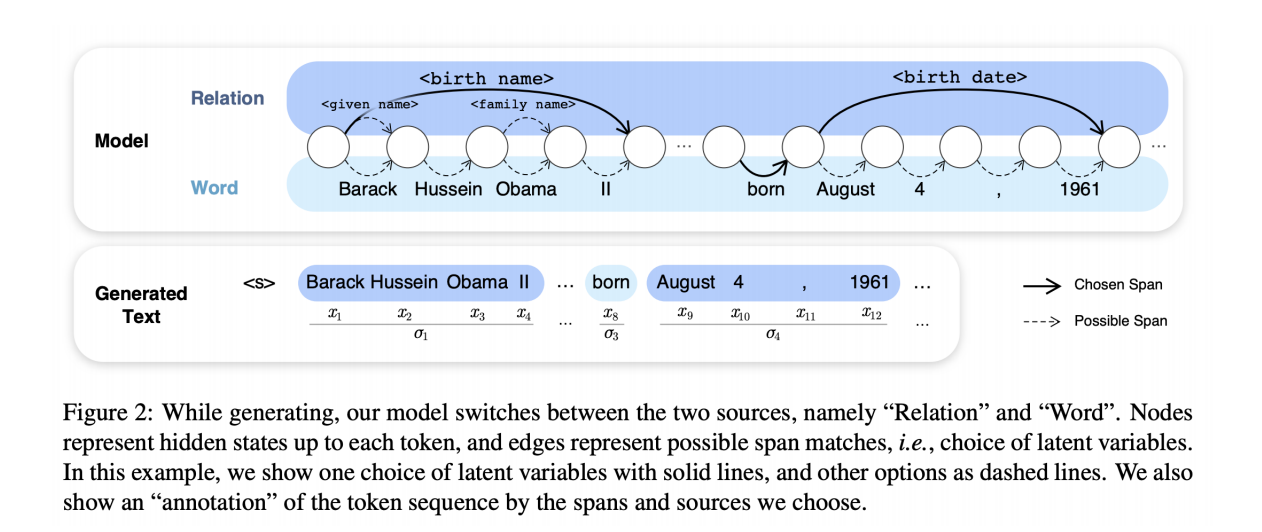
Liu等人提出了K-BERT,它希望每个句子(如果可能)都用来自某些KG的命名实体和相关(谓词,宾语)对进行注释。 然后,将丰富的句子树线性化为一个新的位置相似嵌入,并用可见性矩阵进行遮罩,该矩阵控制输入的哪些部分在训练过程中可以看到并得到关注。
Bouraoui等人进一步评估了BERT的关系知识,即在给定一对实体(例如,巴黎,法国)的情况下,它是否可以预测正确的关系。 作者指出,BERT在事实和常识性任务中通常是好的,而不是糟糕的非词性任务,并且在形态任务中相当出色。
- Entity Matching in Heterogeneous KGs
不同的KG具有自己的模型来建模其实体,以前,基于本体的对齐工具仅依靠此类映射来标识相似实体。 今天,我们有GNN只需少量培训即可自动学习此类映射!
Sun等人提出了AliNet,这是一种基于端到端GNN的体系结构,能够对多跳邻域进行聚合以实现实体对齐。 由于架构异质性,由于相似的实体KG的邻域不是同构的,因此任务变得更加复杂。 为了弥补这一点,作者建议关注节点的n跳环境以及具有特定损失函数的TransE样式关系模式。
Xu等人研究了多语言KG(在这种情况下为DBpedia)中的对齐问题,其中基于GNN的方法可能陷入“多对一”的情况,并为给定的目标实体生成多个候选源实体。 作者研究了如何使他们的预测中的GNN编码输出更加确定。
- Knowledge Graph Completion and Link Prediction
AAAI’20标记并概述了两个增长趋势:神经符号计算与临时性的KG越来越受到关注。
- KG-based Conversational AI andQuestion Answering
AAAI’20主持了“对话状态跟踪研讨会”(DSTC8)。 该活动聚集了对话AI方面的专家,包括来自Google Assistant,Amazon Alexa和DeepPavlov的人员。在研讨会上,多个专家都提出了对话AI的相关研究方法。