ACL 2019 | 理解 BERT 每一层都学到了什么

来源:AI科技评论
探索BERT深层次的表征学习是一个非常有必要的事情。

一、BERT
二、短语句法
 ,然后通过结合第一个和最后一个隐藏向量
,然后通过结合第一个和最后一个隐藏向量
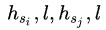
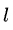 层的跨度表征
层的跨度表征
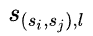 。
。


图2-2. BERT不同层的跨度表征聚类图
三、探测任务
表层任务:句子长度(SentLen)探测,单词在句子中存在探测(WC);
句法层任务:词序敏感性(BShift),句法树深度(TreeDepth),句法树顶级成分序列(TopConst);
语义层任务:时态检查(Tense),主语数量(SubjNum),名词动词随机替换敏感度(SOMO),协作分句连词的随机交换(CoordInv)。
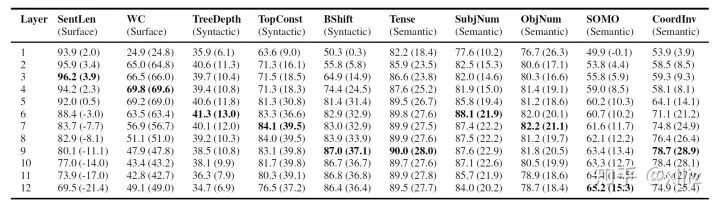
四、主谓一致
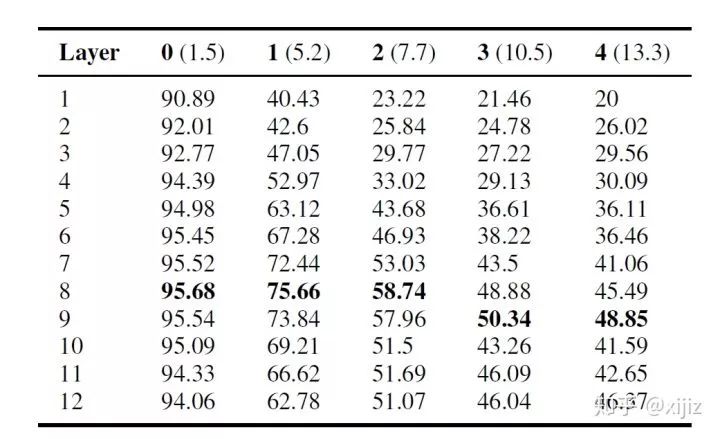
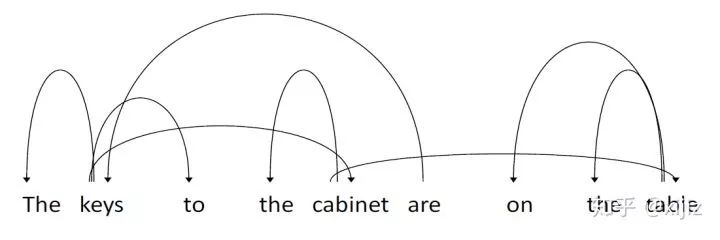
五、组合结构

图2-5. 均方误差图
编辑:黄继彦
校对:杨学俊

登录查看更多
相关内容

Arxiv
15+阅读 · 2018年10月11日


相关VIP内容
相关资讯
相关论文
Arxiv
15+阅读 · 2018年10月11日