自然语言处理常识推理综述论文,60页pdf
【导读】常识推理是机器智能的关键任务,也是非常具有挑战性的研究问题。密歇根州立大学的Shane Storks等学者最近在Arxiv上发布了一篇关于常识推理的综述论文《Commonsense Reasoning for Natural Language Understanding: A Survey of Benchmarks, Resources, and Approaches》,详细阐述了常识推理的任务、数据、资源、推断方法,是很好的参考文章。

自然语言处理常识推理
摘要
常识知识和常识推理是机器智能的主要瓶颈。在NLP社区中,已经创建了许多基准数据集和任务来处理用于语言理解的常识性推理。这些任务旨在评估机器获取和学习常识的能力,以便推理和理解自然语言文本。随着这些任务成为常识性研究的工具和驱动力,本文旨在概述现有的任务和基准、知识资源以及用于自然语言理解的常识性推理的学习和推理方法。通过这一点,我们的目标是支持更好地理解这种技术的现状、局限性和未来的挑战。
引言
常识和常识推理在机器智能的各个方面,从语言理解到计算机视觉和机器人技术,都发挥着至关重要的作用。Davis和Marcus(2015)对常识性推理的挑战进行了详细的描述,从理解和构建特定或一般领域的常识性知识的困难,到各种形式推理的复杂性及其对问题解决的集成。正如戴维斯和马库斯(2015)所指出的那样, 常识推理是一个需要可以集成不同模式的推理的方法(例如,符号通过演绎推理和统计推理基于大量的数据),以及标准和评价指标。
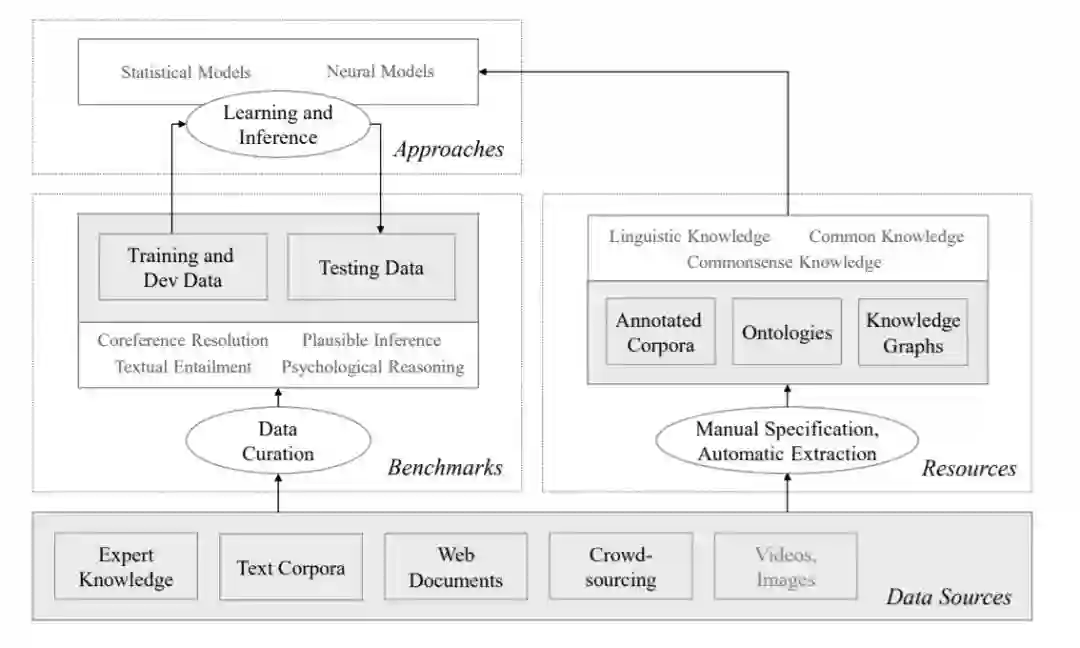
图1. NLP社区在常识性知识和推理方面的主要研究工作发生在三个领域:基准和任务、知识资源以及学习和推理方法。
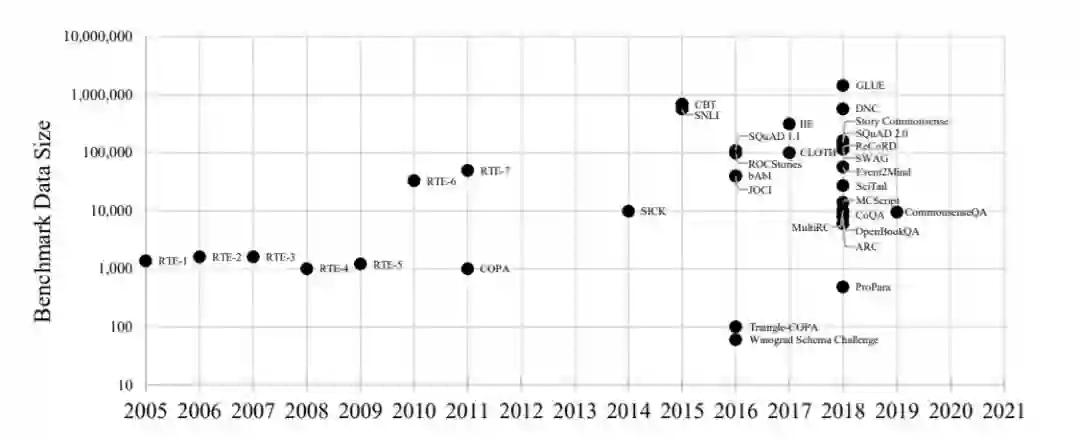
图2. 自本世纪初以来,针对语言理解的常识性推理的基准测试任务激增。2018年,我们见证了比以往任何时候都要多的大型基准数据集的诞生。

图3. 用于创建、注释(即),并验证选定的常识性基准测试和任务,其中M表示专家手动方法,A表示通过语言生成的自动方法,T表示文本挖掘,C表示众包。数据大小包括比较使用的方法
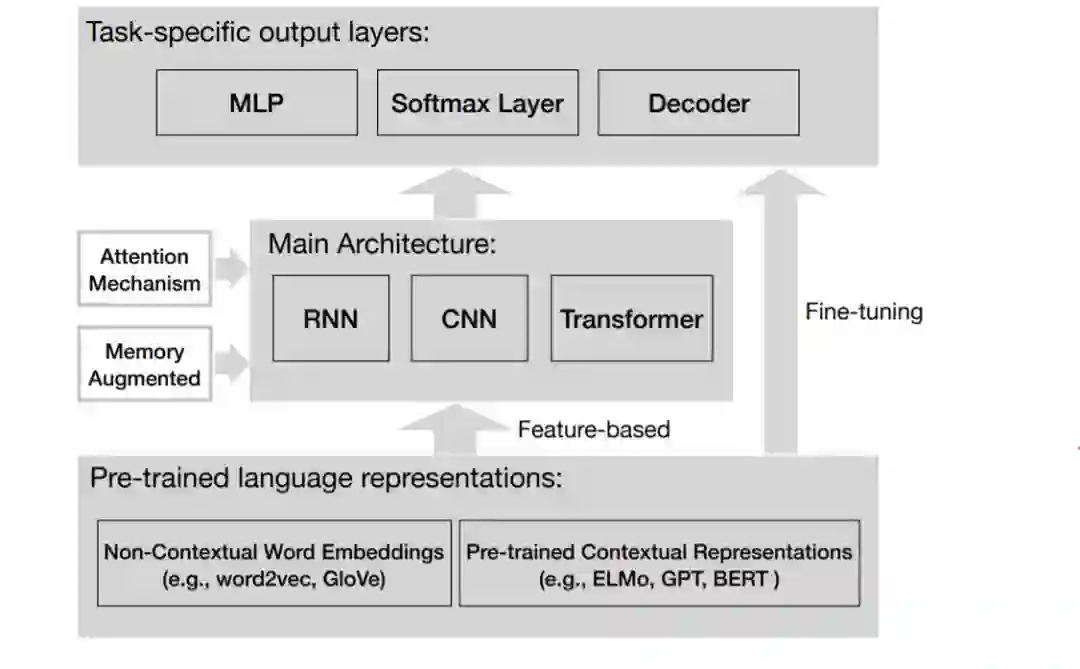
图4. 用于基于语言的常识性任务的神经方法中的常见组件。
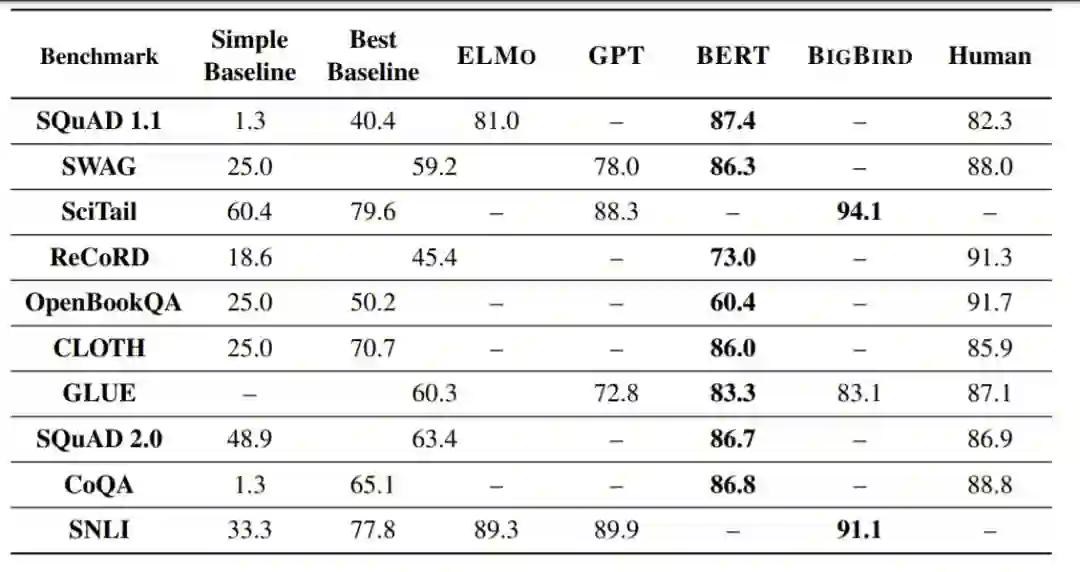
图5. 各方法在数据集上的精确匹配精度进行比较,这是本文中为每个基准、ELMO、GPT、BERT、BIGBIRD和人类提供的最佳性能基准。ELMO指的是使用ELMO嵌入的性能最高的列表方法。以粗体显示每个基准测试上的最佳系统性能。
更多请阅读论文查看:
http://www.zhuanzhi.ai/paper/71efadd1daed14fc906bbbff8f49a1f1
【论文便捷下载】
请关注专知公众号(点击上方蓝色专知关注)
后台回复“CRNLP” 就可以获取《自然语言处理常识推理综述论文》的下载链接~
-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!520+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询《深度学习:算法到实战》课程,咨询技术商务合作~

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程



